
翔宇现在更新了一套极简 RAG(Retrieval‑Augmented Generation)n8n 工作流,专为零基础小伙伴打造。

只需按照下列步骤:
- 1. 在 Pinecone 控制台新建一个 1536 维的向量索引;
- 2. 在 n8n 导入并启用对应工作流,即可立刻体验完整的「上传文档‑> 生成向量‑> 检索‑> 生成答案」闭环。
- 3. 如果安装或参数细节不清楚,可参考我在 《18. 跨境电商必备:Make 与 RAG 打造文章自动化创作工作流》(https://xiangyugongzuoliu.com/18-make-rag-ecommerce-content-workflow/)中的视频讲解。
什么是 RAG?
RAG 将大型语言模型 (LLM) 与外部向量数据库结合:先用相似度检索把最相关的知识片段找出来,再把这些片段与用户提问一起交给 LLM 生成回答或内容。
作用与价值
- 降低幻觉:模型回答基于真实资料,有据可查。
- 轻松扩充知识库:新增文档即可即时生效,无需重新训练模型。
- 场景丰富:客服问答、跨境商品描述、内部知识检索、合规报告生成……皆可快速落地。
希望这份工作流能成为你迈入 RAG 世界的第一块跳板,祝你玩得开心、学得顺手!
一.Pinecone 向量库快速创建
1. 登录 Pinecone 控制台,点 Indexes → Create。
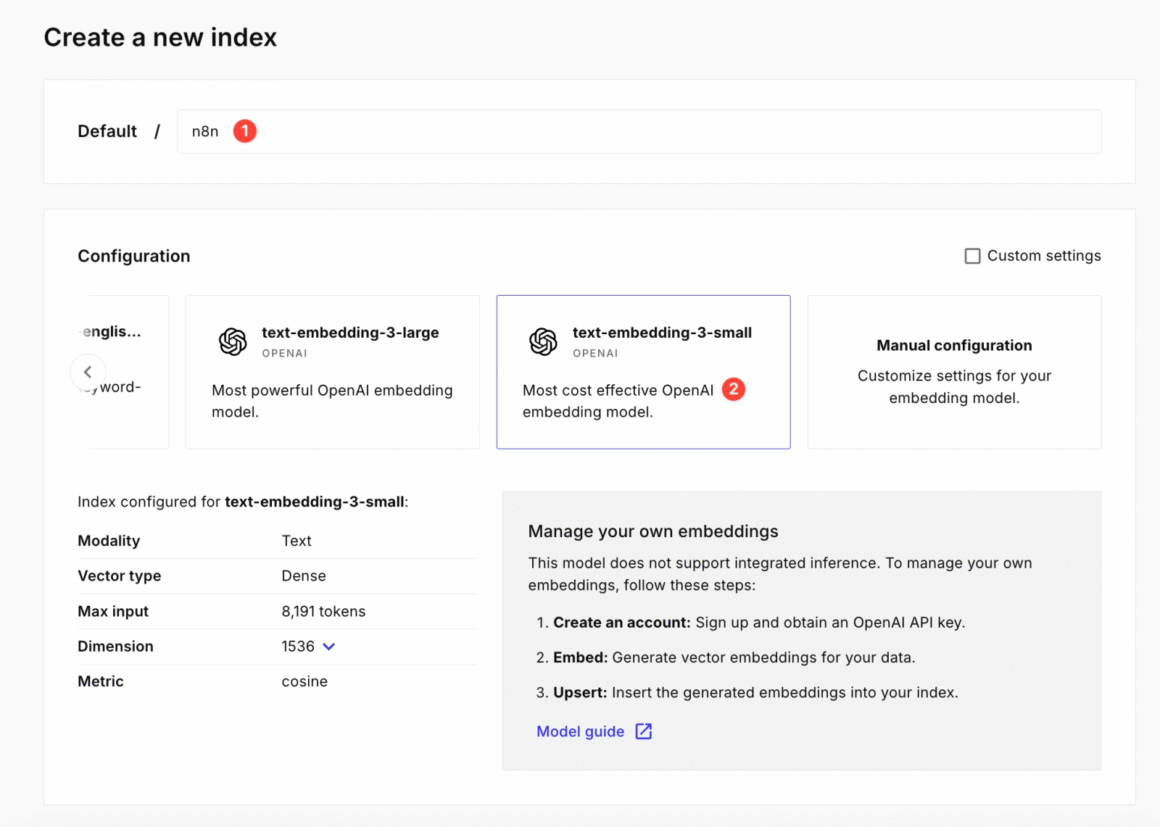
2. 设名为 n8n,Configuration 选 text-embedding-3-small OPENAI,点击Create index完成创建。
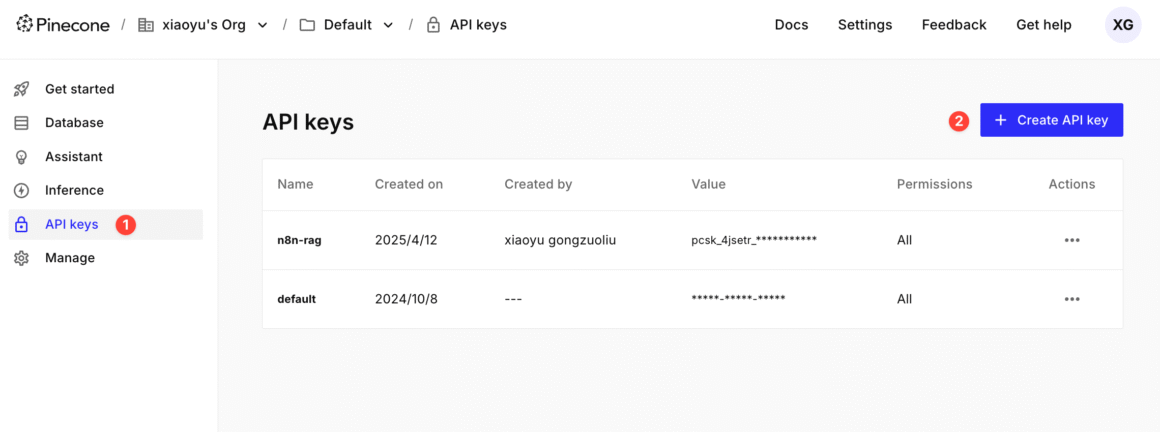
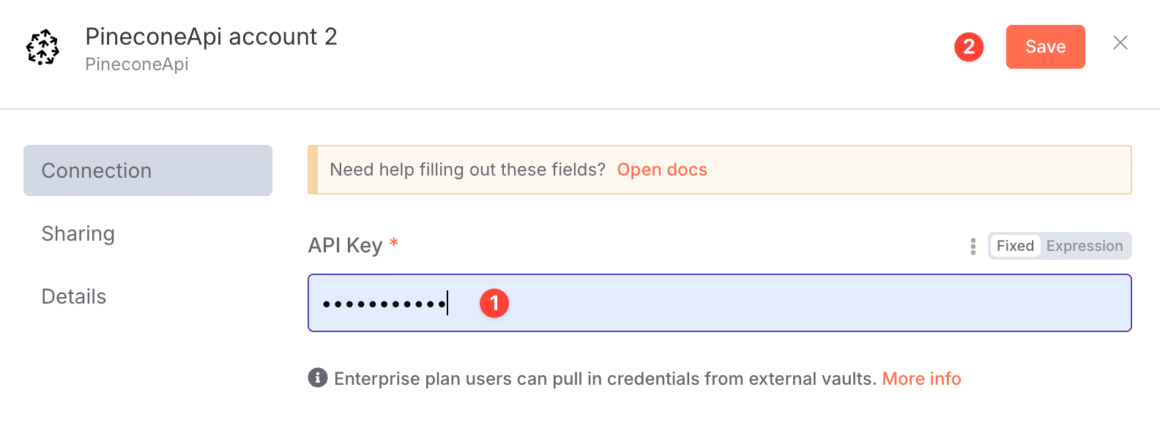
3. 创建与复制 API Key ,在 n8n 的 Credentials → PineconeApi 中保存,即完成向量数据库搭建。
二.工作流节点逐一拆解(由上到下顺序)
1. 上传 PDF(formTrigger)
生成一个带文件字段的表单,用户点“提交”即触发流程。
该节点负责把二进制文件 上传后续链路,省去手动上传步骤。
2. Pinecone Vector Store(mode: insert)
将向量批量写入 n8n 索引
Default Data Loader
接收切好的文本块并封装成 LangChain Document 对象,为后面的嵌入做准备。
Recursive Character Text Splitter
将长文档切成片段;参数 chunkSize = 3000、chunkOverlap = 200,既保证上下文连贯,又避免段落过大导致嵌入截断。
Embeddings OpenAI
调用 text‑embedding‑3‑small(输出 1536 维),把每段文本转成向量。模型与 Pinecone 维度匹配。
3. 对话(chatTrigger)
建立一个独立 Webhook,用于实时接收用户聊天消息,和上传 PDF 互不干扰。
4. 数据库对话(agent)
LangChain 智能体,串联聊天模型与 Pinecone 工具,负责提示工程和多步推理,真正实现 “RAG” 闭环。
Pinecone Vector Store (mode: retrieve‑as‑tool)
以工具形式检索最相关的片段;toolName: bitcoin_paper、toolDescription 用于在代理链中自描述。
Embeddings OpenAI
对用户问题做同款嵌入,保持查询与文档处在同一向量空间。
OpenAI Chat Model
使用 gpt‑4o‑mini;它接受问题和检索结果,输出自然语言答案。
到此,一个最小可用的 PDF→向量→检索→回答 工作流即告完成:上传文件即可写入知识库,随后在聊天窗口向模型提问获得基于文档的精准回答。
三.工作流下载:
小报童下载地址:https://xiaobot.net/post/8ffd5b01-2fff-4b46-a10b-bfdc382ce9f1
Buy me a coffee 下载地址:https://buymeacoffee.com/xiangyugongzuoliu/n8n-rag









