Hermes SOUL.md 人设工程 + 三层记忆深度解析:让 Agent 精确遵循你的人格
Hermes Agent 的三层记忆系统——SOUL.md 定义身份、MEMORY.md 记录环境事实、USER.md 刻画用户画像——合计约 1,300 Token 的永久记忆预算,在会话启动时冻结注入系统提示词。本文深度拆解 10 层提示词拼装顺序、9 种外部记忆提供商对比、记忆安全扫描机制,附翔宇指针架构实战全文与 SOUL.md 调优四步法。
Hermes Agent 的三层记忆系统——SOUL.md 定义身份、MEMORY.md 记录环境事实、USER.md 刻画用户画像——合计约 1,300 Token 的永久记忆预算,在会话启动时冻结注入系统提示词。本文深度拆解 10 层提示词拼装顺序、9 种外部记忆提供商对比、记忆安全扫描机制,附翔宇指针架构实战全文与 SOUL.md 调优四步法。
Hermes Agent 语音模式支持三种交互表面:CLI 按键录音、Telegram 语音气泡、Discord 语音频道实时对话。本文覆盖 10 种 TTS 与 6 种 STT 提供商对比、零成本方案(faster-whisper + Edge TTS)、26 短语幻觉过滤器、四档 config.yaml 配置模板。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
用 n8n 搭建 AI 自动剪辑工作流,让 AI 当导演批量剪辑任意视频。工作流实现视频场景检测、AI 理解画面内容、自动编写解说词、TTS 配音和最终合成五个核心环节。教程涵盖 PySceneDetect 镜头切分、GPT-4V 视频理解 API 调用、解说词风格化生成和 FFmpeg 音视频合成参数,支持美食纪录片到科技评测等多种视频类型。

你有没有遇到过这样的情况:手上攒了大量的视频素材,想把它们剪辑成短视频发到抖音、TikTok,但一想到逐条剪辑、配音、对齐音画的工作量,就直接放弃了?
我是翔宇。翔宇在做视频内容的过程中一直在想:能不能让 AI 理解画面后自动完成剪辑和解说?这套工作流就是答案。
这正是我开发这套 n8n 工作流的初衷。经过七个版本的迭代打磨,我做出了一套真正意义上的"AI 导演批量剪辑系统"——你只需要提供原始视频和一个风格描述,整个工作流就会自动完成视频分析、剧本编写、分镜切割、多语言配音,以及毫秒级音画同步。从几分钟的短片到 6 小时的超长视频,都能处理。
更关键的是,这套工作流的杀手锏不在代码,而在提示词。只要 AI 大模型的能力提升,工作流的效果就会跟着提升——它不会过时。
本教程配套视频已发布在 YouTube,建议搭配视频一起学习效果更佳。
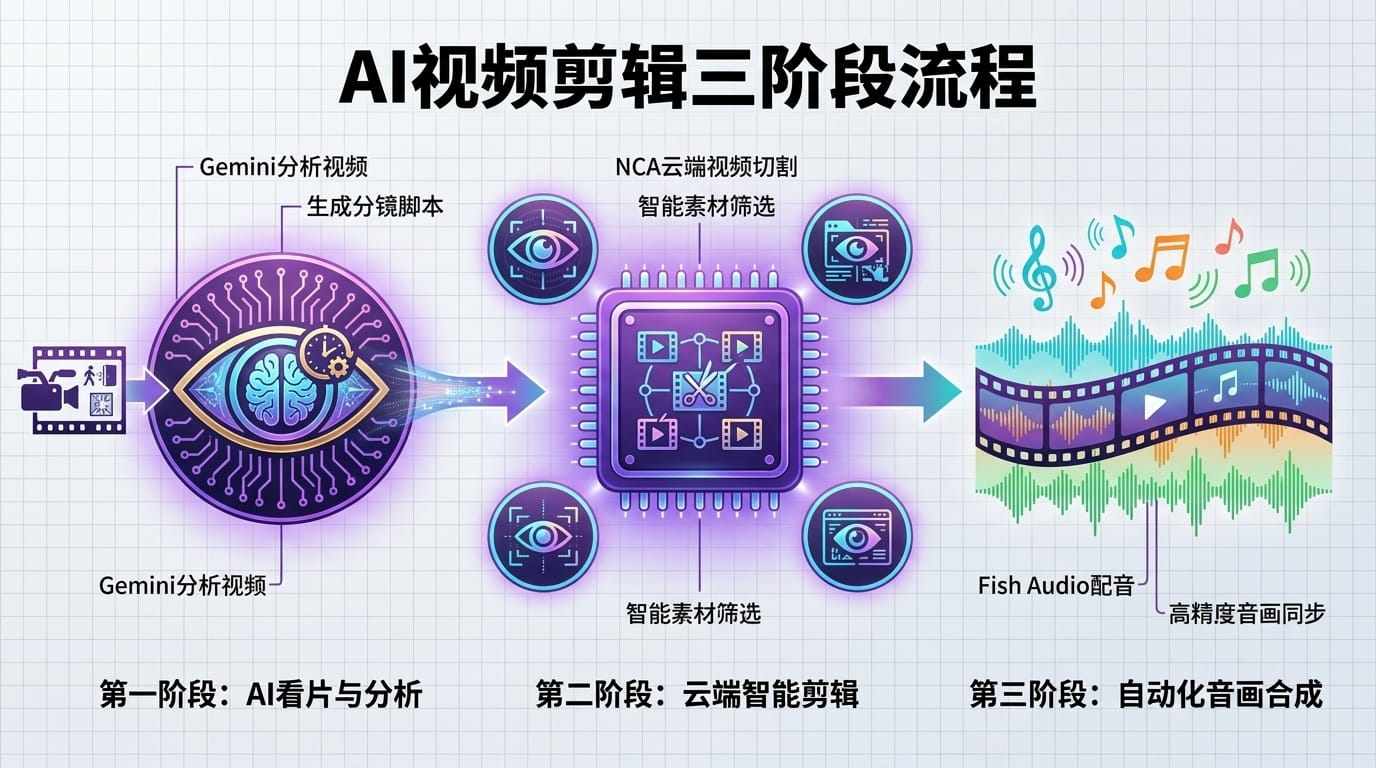
这套工作流的核心思路可以用一句话概括:让 AI 当导演,n8n 当制片人,云端工具当剪辑师。
整个流程分为三个阶段。第一阶段是"AI 看片"——把视频上传到谷歌云存储桶,通过 Vertex AI 让 Gemini 直接分析云端视频,生成包含时间戳、旁白、画面描述的完整分镜脚本。第二阶段是"云端剪辑"——NCA 工具根据分镜脚本在云端完成视频切割,不占用 n8n 任何内存。第三阶段是"音画合成"——Fish Audio 生成配音,通过三版本择优和自适应变速实现精准同步,最后全片拼接。
为什么选择 Vertex 而不是普通的 Gemini API?因为 Vertex 可以直接读取谷歌云存储桶中的文件 URI。5 个 G 的视频直接在云端处理,n8n 几乎零消耗。这是处理长视频的关键突破。
这个工作流前后迭代了七个以上的版本。最早的版本在 n8n 框架内上传视频到谷歌再处理,几十兆就卡住了。后来切换到 Vertex 的 URI 直调方案,彻底解决了大文件问题。
音画同步是另一个技术难点。NCA 工具的音频调速限制在 0.5 到 2 倍之间,超出就报错。直接让大模型精确控制字数也做不到。最终的解决方案是"脑筋急转弯"——让大模型分别生成三个不同字数版本的旁白(比如 40 字、50 字、60 字),再通过 JavaScript 代码选择时长最接近画面的那一个。这样声音和视频的比值可以达到 1.01 或 0.99,实现毫秒级同步。
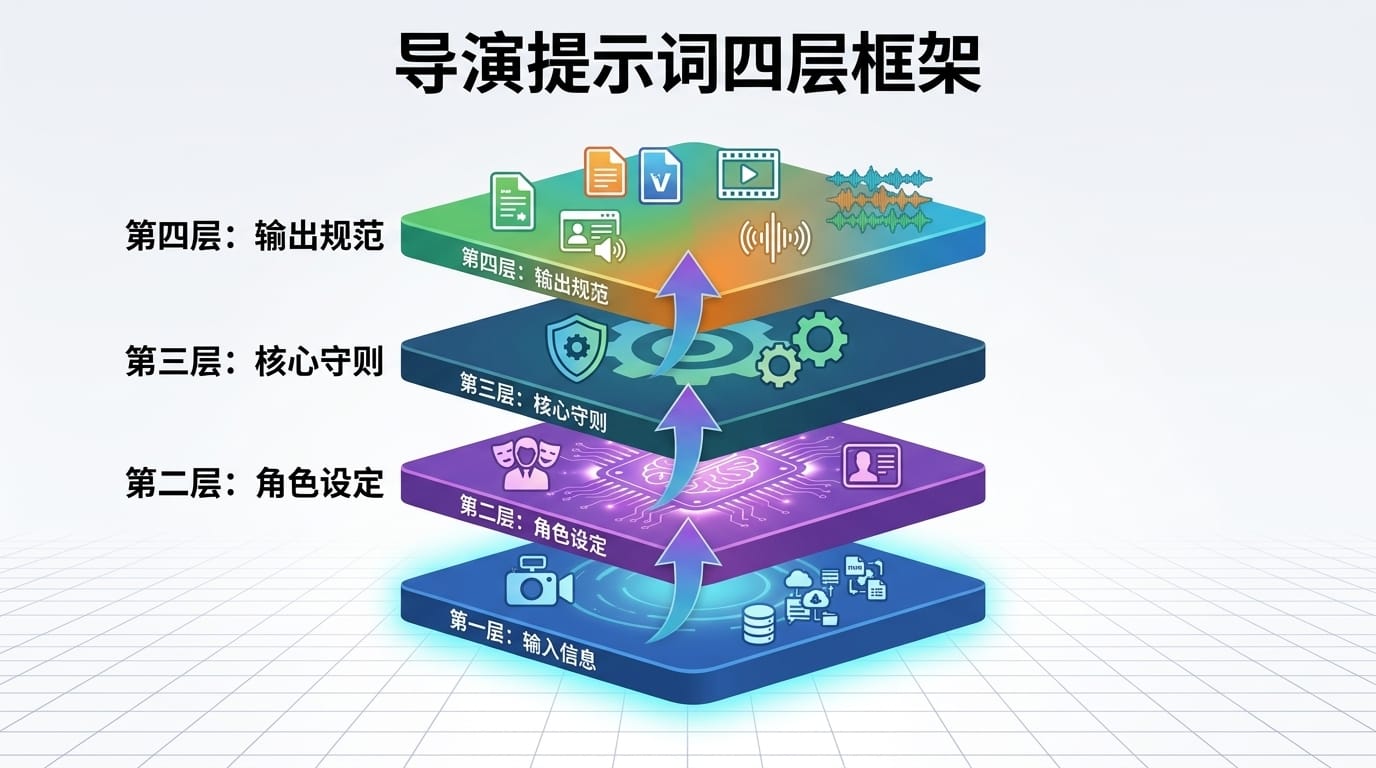
这套工作流所有效果的核心,都在提示词上。我设计了一个四层结构的导演提示词框架:
输入信息层:告诉 AI 分镜数量、频道名称、目标语言、推荐分镜时长范围。这些参数都可以在表单中调整。
角色设定层:定义导演的身份和风格。通用版本是"顶尖的 AI 全能解说导演",毒舌电影版是"深度学习了毒舌电影创作风格的解说导演",纪录片版是"善于将书面知识升华为引人入胜视听故事的 AI 纪录片导演"。
核心守则层:这是最重要的部分。包括内容识别与深度解读(先当观众再当导演)、技术标准(时长是天条,字数公式严格遵循)、深度解构(提炼每个方面的核心脉络和视觉重点)、剪辑心法(开篇定调、叙事构建、节奏掌控)。
输出规范层:JSON 格式要求,时间戳精确到毫秒,分镜数量严格对齐。
你只需要修改角色设定和核心守则,就能创造出完全不同的剪辑风格。正如我常说的——"Code is cheap, show me your prompt。"
在调教提示词的过程中,我发现一个重要规律:要求越多越冗杂,效果反而不如简单的提示词好。
处理两个小时的超长视频时,大模型的上下文 Token 已经非常有限。你再往提示词里塞各种限制,它根本没有注意力来兼顾。比如毒舌风格的提示词,同时要求音画同步、时间线顺序、风格化表达——这三个注意力本身就是冲突的。
我的建议是先用短视频(20 分钟以内)调试风格化提示词,效果满意后再逐步处理长视频,过程中不断精简提示词、消除冲突。框架先搭好,再做减法。
这套工作流有两种核心用法:
视频解说模式:AI 分析视频的实际内容,生成与画面对应的解说旁白。适合电影解说、纪录片、产品评测等。
素材模式:把视频纯粹当作画面素材,在文案框中输入完全独立的文本。比如拿一部治愈电影的画面,配上一个悬疑故事的文案——这就是一个全新的导演作品。
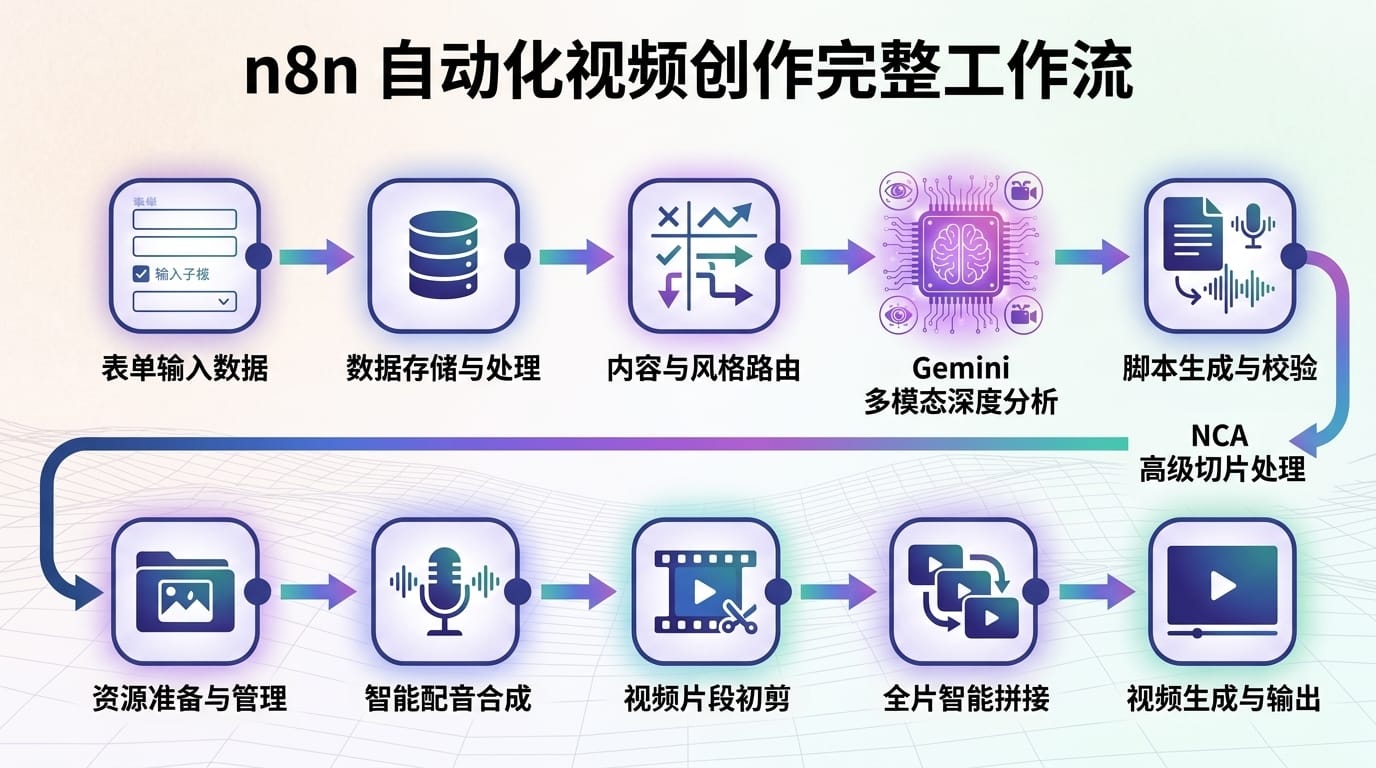
第一步:需求输入表单。 添加 Form 节点,设置素材网址(直链)、剪辑风格(下拉菜单)、分镜数量、语言、输入文案等字段。注意素材必须使用谷歌云存储的直链。
第二步:风格路由。 使用 Switch 节点,根据选择的剪辑风格走不同的分支,每个分支对应不同的导演提示词和音色。
第三步:设置参数。 在 Edit Fields 中配置提示词和音色 ID。每个风格分支单独配置。
第四步:参数综合。 把所有需要修改的参数集中在一个 Edit Fields 节点:Google Cloud 存储桶名称、Gemini API Key、NCA API Key、Fish Audio API Key、模型 ID 等。导入工作流后只需要修改这一个节点。
第五步:Gemini 多模态分析。 HTTP Request 节点通过 Vertex AI 发送视频 URI 给 Gemini。关键参数 mediaResolution 设为 low,可处理长达 6 小时的视频。
第六步:分镜提取。 Code 节点将 Gemini 返回的 JSON 解析为独立的分镜数组,每个分镜包含 Scene ID、起止时间、持续时长、旁白文案。
第七步:NCA 云端切片。 将分镜时间段发送给 NCA 的视频切割端点,配合状态轮询(每分钟查询一次 Job Status),等待所有分镜切割完成。
第八步:遍历分镜与音画同步。 使用 Loop 节点遍历每个分镜,对旁白进行三版本字数修正(分别乘以 4、4.5、5.5 的系数),再次调用 Gemini 多模态分析单个分镜画面。
第九步:三版本配音生成。 并行调用三组 Fish Audio 节点,分别为三个字数版本生成配音,上传到谷歌云存储并获取精确时长。
第十步:音画匹配与调速。 Code 节点选择时长最接近画面的配音版本,计算比值后通过 NCA 的 FFmpeg 端点对视频进行微调速,最后合成音视频。
第十一步:全片拼接与归档。 Aggregate 节点汇聚所有分镜,NCA 拼接为完整视频,保存到 Notion 数据库并通过 Form Ending 返回最终视频链接。
我用这套工作流测试了十几个不同领域的视频,覆盖了主流的内容赛道:
效果展示详见:工作流效果页面
Q:视频太长导致 Gemini 返回不准确怎么办?
这不是工作流的问题,而是大模型能力的边界。目前处理 2 小时以上的视频时,画面截取精度会下降。建议先从 20 分钟以内的视频开始,等模型能力提升后再处理更长的素材。
Q:NCA 调速报错怎么处理?
NCA 的 FFmpeg 调速支持 0.5 到 2 倍范围,超出会报错。在 n8n 的 Setting 里打开 Continue on Error,让它跳过当前分镜继续处理下一个。三版本择优机制已经大幅降低了超范围的概率。
Q:能不能完全免费运行?
Gemini 有 300 美元的免费额度,NCA 部署在谷歌 Cloud Run 上成本很低,Fish Audio 充值几美元就能用很久。唯一必须付费的是 n8n 的云端部署(约 5 美元/月)。整体成本极低。
这套工作流的价值不在于它能替代人工剪辑——而在于它把"从素材到成片"的全流程自动化了。你只需要准备好视频素材和风格提示词,就能 24 小时无人值守地批量生产内容。
我花了几个月的时间把导演提示词做到了极致,还准备了覆盖影视解说、财经、科技、游戏、美妆、旅游等二十多个赛道的 5 万字提示词模板,都在小报童和 Buy Me a Coffee 中。
但最重要的不是使用某一个工作流,而是学会一种和 AI 对话的能力、调教提示词的能力、结构化思维的能力。下一期我们将进入 AI 全自动写作系统,从视频领域跨越到文字领域。
📚 更多 n8n 自动化内容:n8n 自动化工作流完全指南


小红书、公众号、抖音、视频号、YouTube、X——6 个平台先做哪个?这个站先帮你选对平台,再给每个平台用 AI 做内容的打法。
Sean 已经算是「翔宇工作流」学员实践栏目的常客。前段时间我们刚介绍过他的 Animaker Dev,现在他又上线了 GoodTrans,把长文档翻译做成可编辑译文、双语对照、质量报告和异步邮件交付。

翔宇学员云燚和团队制作的 AI 时代深度播客《42织序》,由人类主播和 AI 搭档“序言”共同构成节目第二视角,目前两期围绕 AI 重塑工作、关系操作系统、岗位议价权等命题展开。本文将节目介绍给关注同方向的听众。
每周精选 AI 编程与自动化实战内容,直达你的邮箱