Hermes Skill 自我进化系统:让 AI 助手越用越聪明
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。
Calvin 是「翔宇工作流」的学员,方向是 AI 模型中转。他把这件事做成了独立站点「openbili」,覆盖 OpenAI SDK 兼容、模型路由、调用成本可见、失败可解释。本文将其介绍给关注同方向的读者。
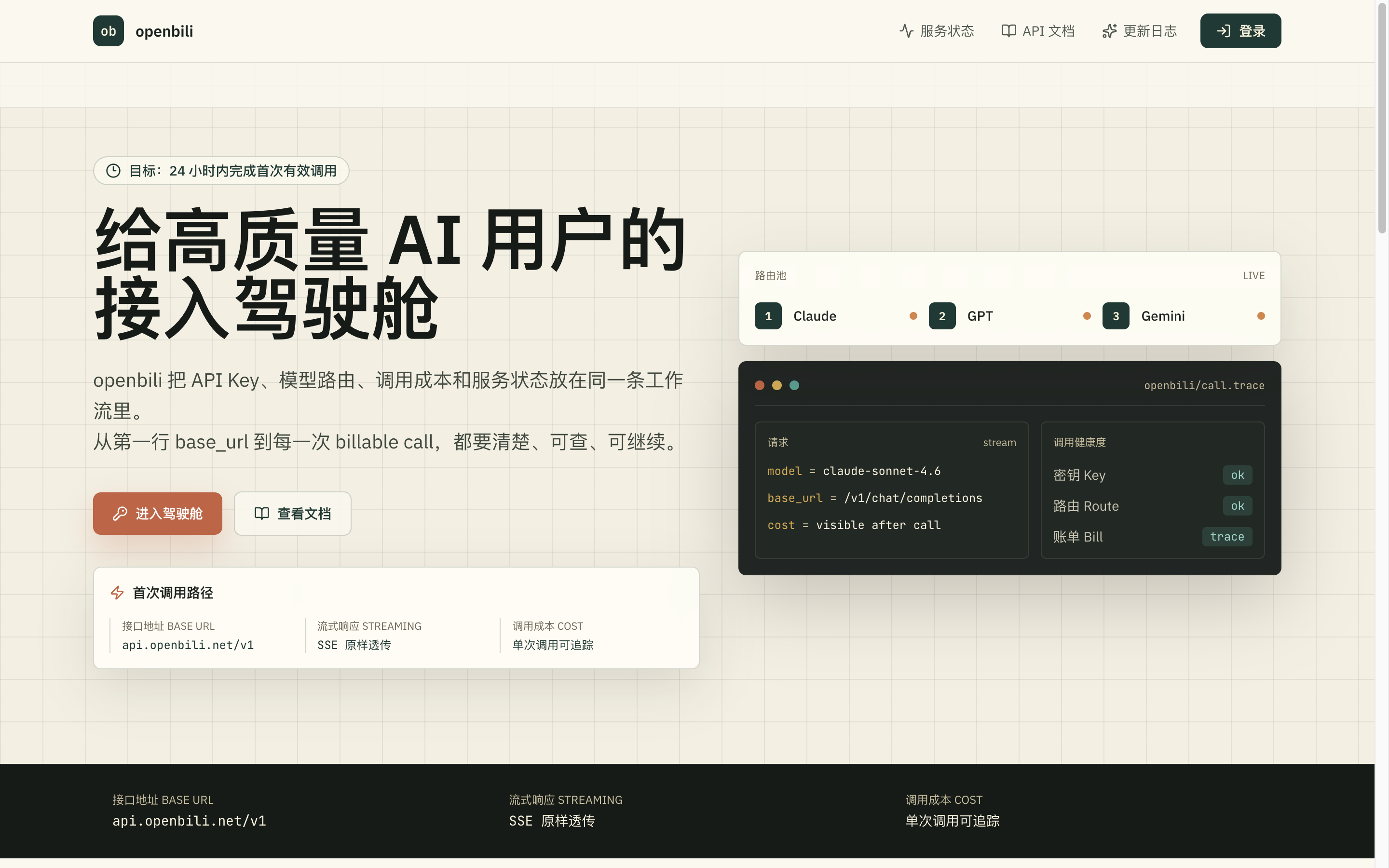
Calvin 是「翔宇工作流」的学员之一,方向是 AI 模型中转。近期他把这件事做成了独立站点 openbili 上线,本文将其介绍给关注同方向的读者。
做 AI 应用绕不开模型选择,再往前一步,还需要考虑成本能不能算清、失败能不能解释。openbili 选的切口比较直接:输入端是标准的 OpenAI SDK 调用,输出端是 Claude、GPT、Gemini 三条主线的响应,中间由路由池负责模型调度,旁边由账单与状态系统给出每一次调用的证据。把这三段拼起来,就是 base_url 与 api_key 一换,原本散落在不同厂商账号里的调用,被收拢到了一条可追踪的工作线上。
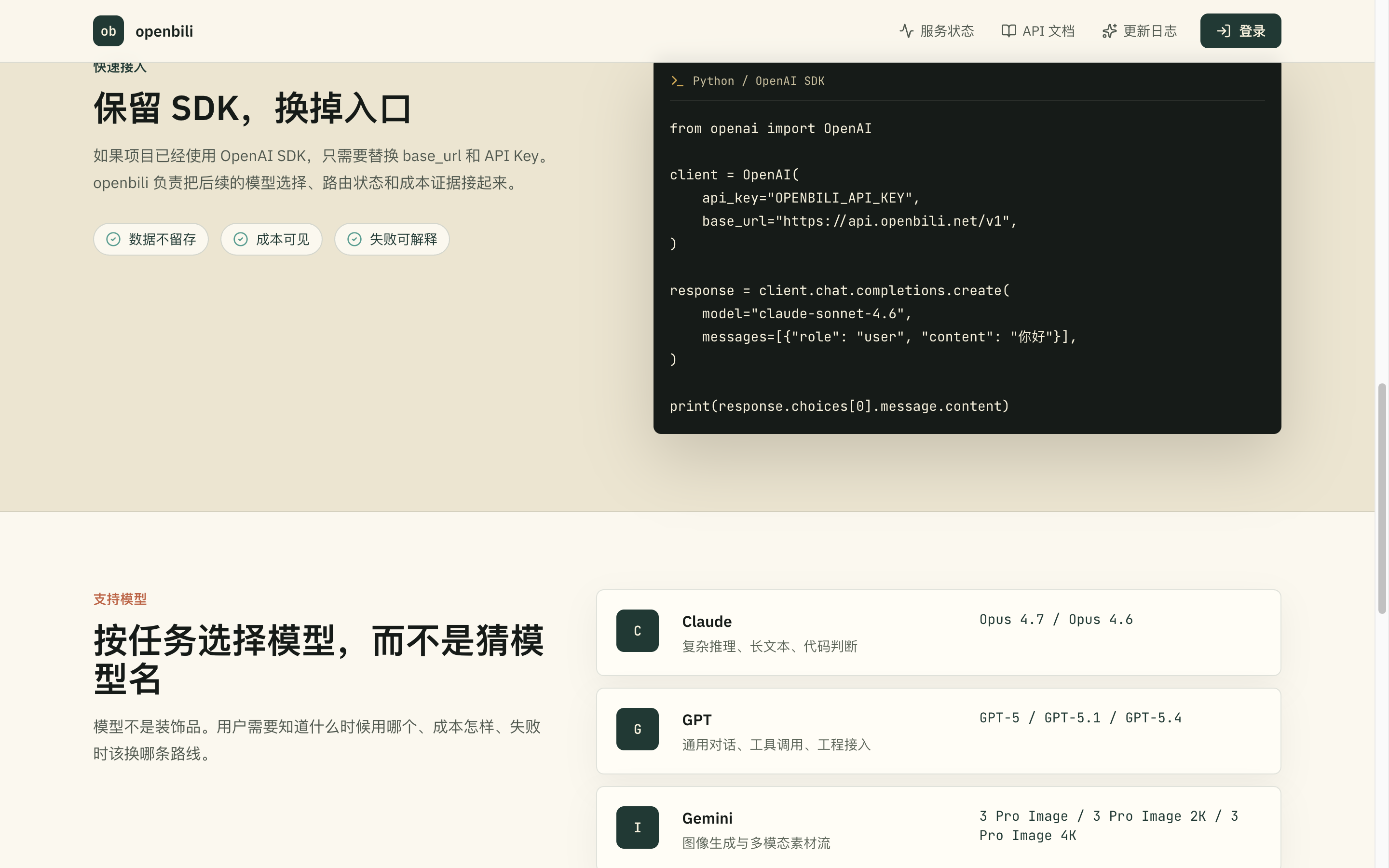
整个站点把接口地址、流式响应规格、调用成本这几件事都直接列在了正面。从首屏的 base URL,到「保留 SDK,换掉入口」的代码示例,再到按任务划分的模型矩阵,节奏是连贯的——驾驶舱的目标是让人立刻接入,不是先讲一段产品哲学。
对于打算从零开始接入 AI API 的开发者,比如以前只用过一家厂商、被官方 SDK 绑住的人,openbili 把第一次成功调用的路径压得比较短:创建 Key、跑通请求、看见成本、读懂状态,四步基本就完成了对一个新接入层的全部认知。「换上游」这件事的心智负担因此被降到了较低的位置。
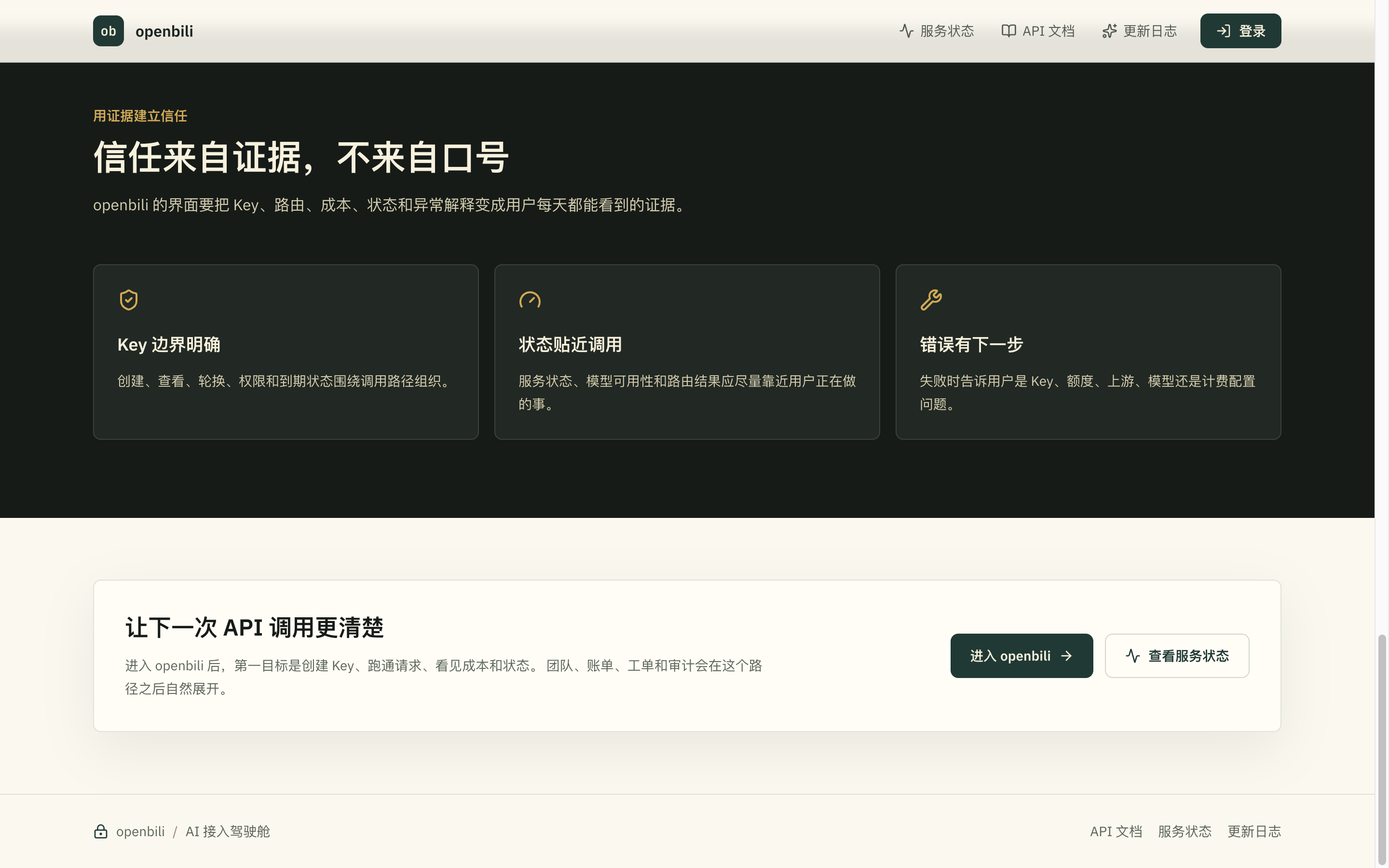
对于已经在 Claude、GPT、Gemini 之间反复切的工程师,要解决的是另一类问题:账号分散、计费口径不一致、失败原因混在不同后台里查不清楚。openbili 把「错误有下一步」放在三条信任要点之一——失败时要能区分是 Key、额度、上游、模型还是计费配置出了问题,这件事在多模型混用的场景里相当吃工程经验。
站内把支持模型按任务做了并列陈列:Claude 主推复杂推理与代码判断,GPT 偏通用对话与工具调用,Gemini 走多模态与图像生成;并把可用版本号一并列出(Opus 4.7 / 4.6、GPT-5 / 5.1 / 5.4、Gemini 3 Pro Image 系列)。这种「什么时候用哪个、可换哪条线」摊在桌面上的列法,比单堆模型名更贴近实际开发取舍。配上「数据不留存、成本可见、失败可解释」这条三件事的承诺,产品的心智边界就比较清楚——它不在模型那一层,而在接入那一层。
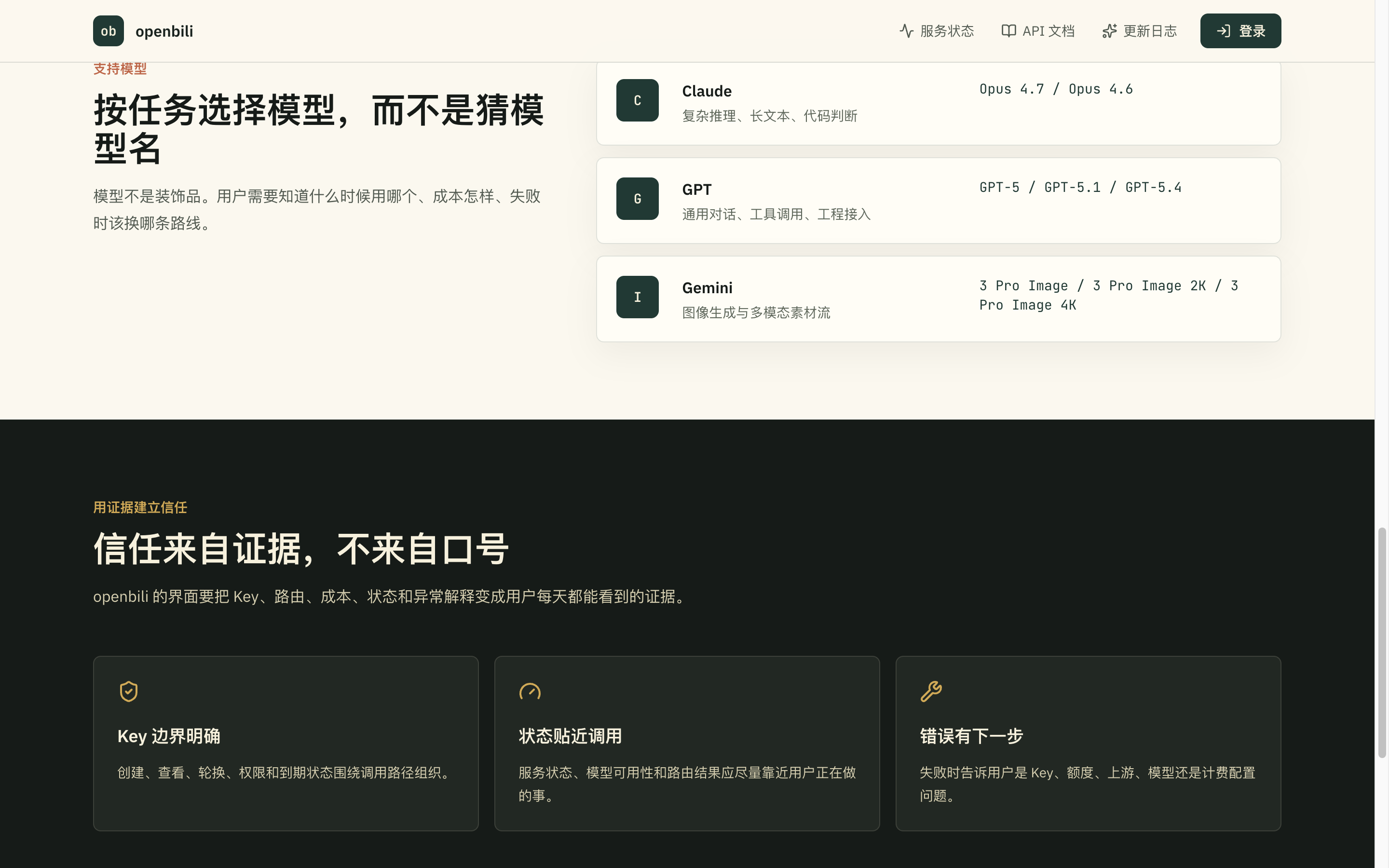
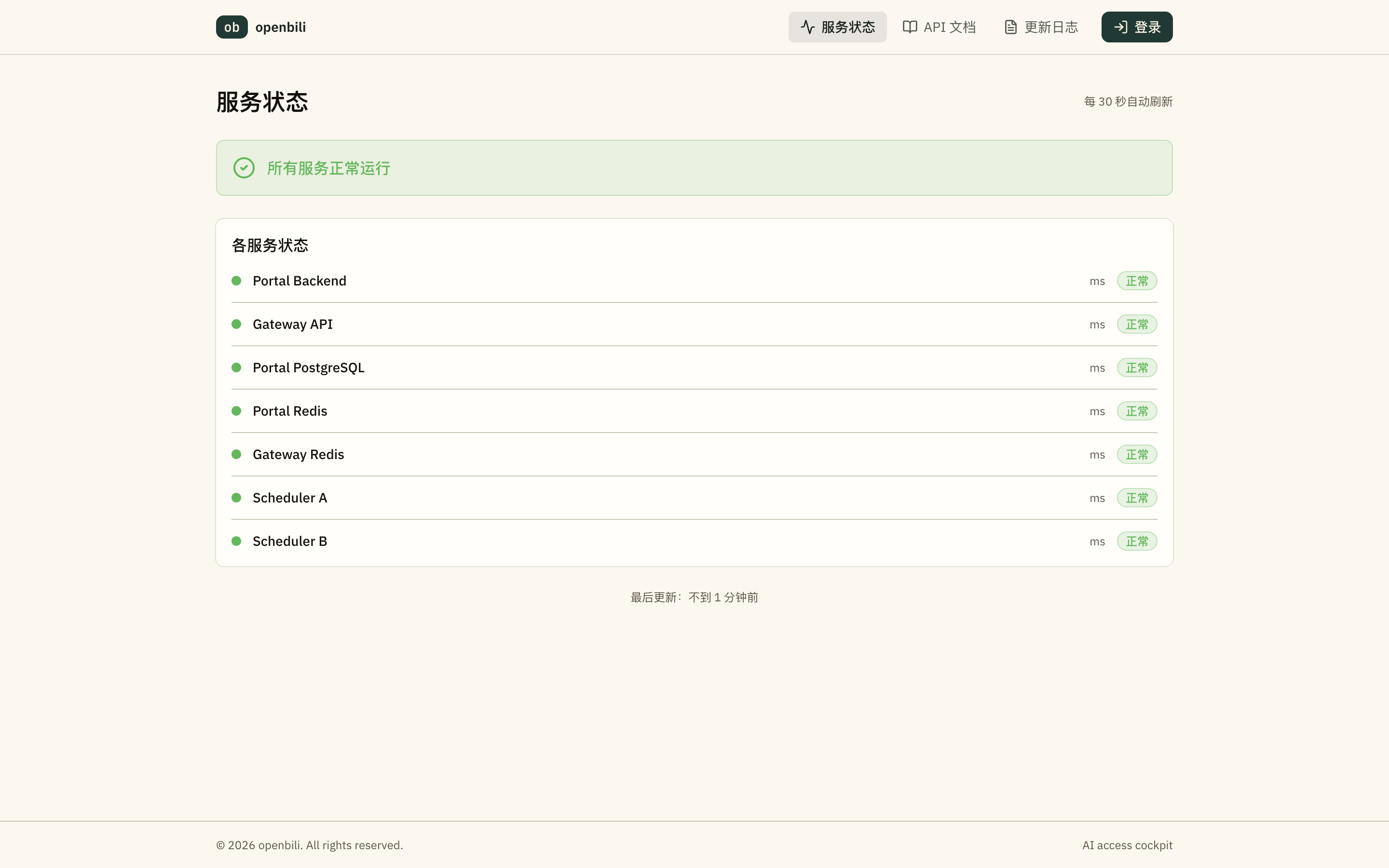
「服务状态」页则把 Portal Backend、Gateway API、PostgreSQL、Redis、Scheduler 等组件的运行健康度公开列出,每 30 秒自动刷新,状态贴近调用这件事在产品外侧也能直接看到。
如果喜欢用 AI 中转站把模型调用收到一处管,不妨试试。是否合适、是否需要进一步体验,由各位读者结合自身情况自行判断。下方附 1 个入口:
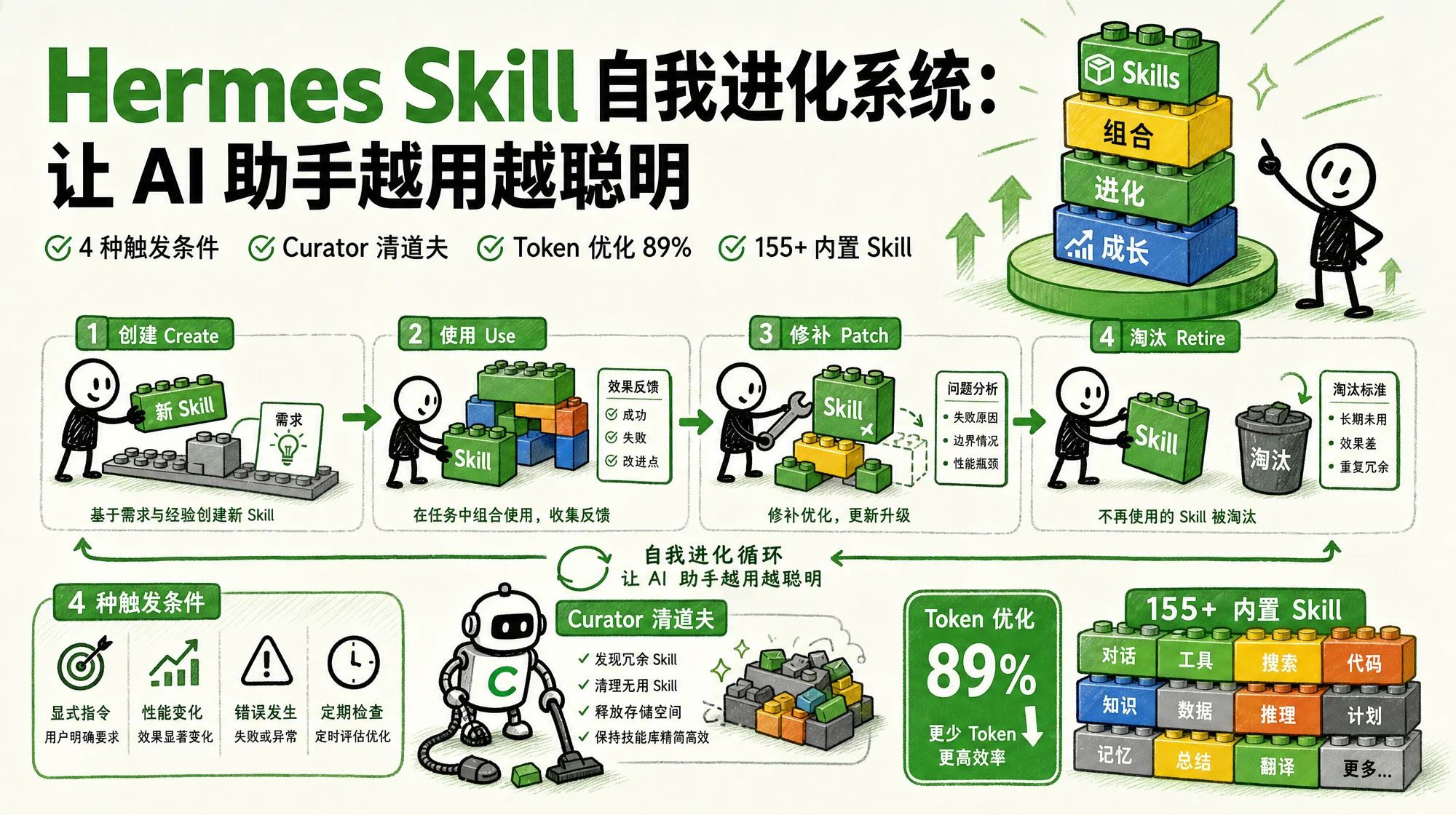
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。

Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。

基于两个 Ghost 站(中文站 + 英文站)18 个月的完整运营经验,覆盖选型决策、VPS 部署、域名配置、主题开发、Newsletter 增长、SEO 优化、多站管理和 API 自动化发布全链路。
每周精选 AI 编程与自动化实战内容,直达你的邮箱