Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
n8n 工作流和 Claude Code Skill 看起来不同,本质上都是流程编排。这篇拆解一个 SEO 关键词调研案例:如何把节点、连接和数据流,迁移成可执行的 Skill 工作流。

任何 n8n 工作流都可以秒变 Claude Code Skill。
听起来像吹牛?我也这么想过。
直到我花了一天时间,真的把一个复杂的 SEO 关键词调研工作流完整迁移。那一刻我才意识到:这不是「转换」,是「升级」——因为 Skill 自带 Agent 能力,你不再需要配置一堆 API 节点,AI 直接理解任务并执行。
n8n 和 Skill 的底层逻辑是相通的——都是对流程化任务的编排处理。
今天,我要分享这个 SEO 关键词调研工作流的完整设计原理,让你理解为什么任何 n8n 工作流理论上都可以转化为 Skill,以及如何用这种思维让你的工作效率翻倍。
读完这篇文章,你将获得:
用生活理解技术 想象你是一位侦探,要调查某个关键词的「市场价值」。传统做法是:打开十几个网页,手动记录数据,再用 Excel 分析。这就像用放大镜一个个看线索。而自动化工作流,就像给你装了一套监控系统 + AI 助手,数据自动收集,分析报告自动生成。
先说说痛点。
如果你也是那种「明知道可以自动化,却还在手动操作」的人——
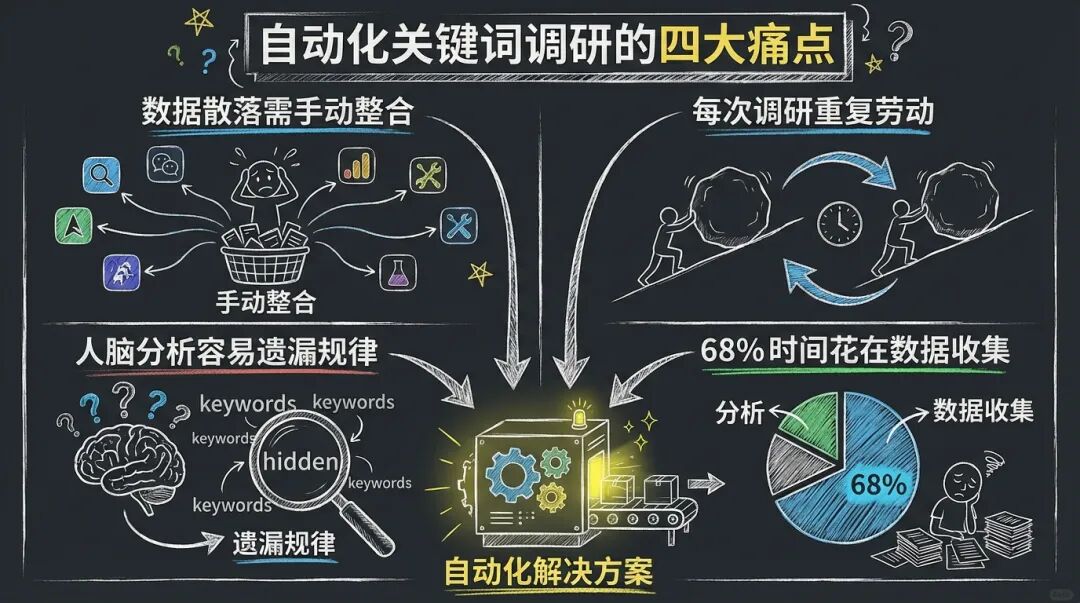
一定经历过这种折磨:花几个小时在各种工具之间切换,手动复制粘贴关键词数据,用 Excel 做聚类分析,最后写一份半生不熟的报告。
更糟糕的是,这个过程每换一个关键词就要重来一遍。
核心问题在哪?
记住这个 自动化的本质不是「让机器干活」,而是「让流程可复现」。一旦流程固化成工作流,你就可以无限次地以相同质量执行它。
根据 2025 年的行业调研,企业 SEO 团队平均有 68% 的时间花在数据收集和整理上,而真正的策略分析只占 32%。这个比例完全可以通过自动化反转。
自动化关键词调研的四大痛点
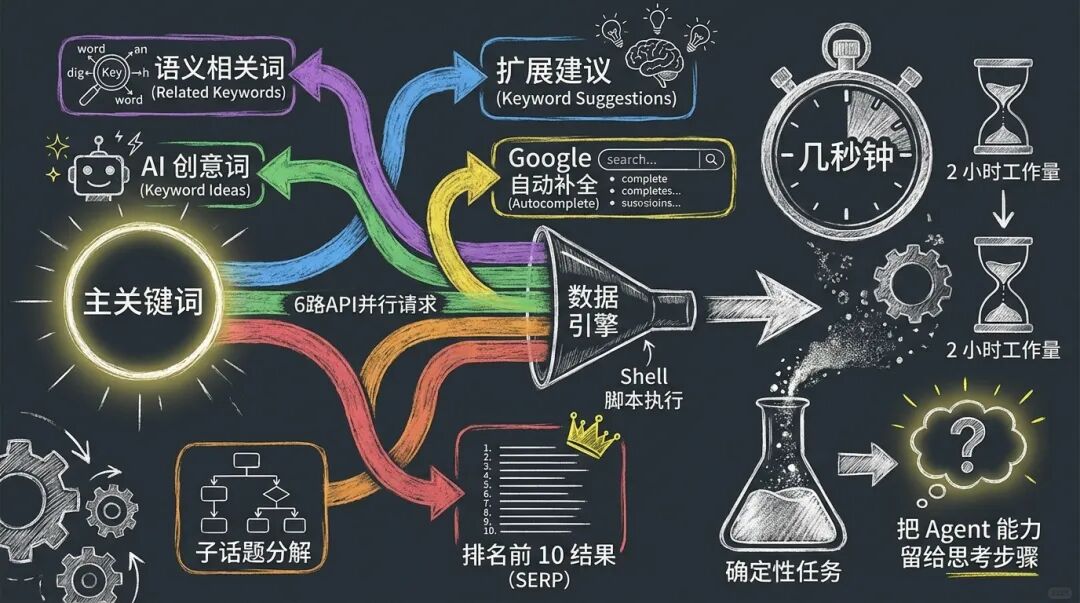
我设计的这套 Skill,用 6 个步骤完成一次完整的关键词深度调研:
Step 1:参数收集 → 询问关键词、目标市场、搜索深度
Step 2:DataForSEO 采集 → 6 路 API 并行,获取相关词、搜索量、竞争度、SERP 结果
Step 3:竞争者抓取 → 抓取 Top 5 排名页面的结构化内容
Step 4:AI 链式分析 → 4 轮深度分析(竞争者 → 用户意图 → 机会识别 → 内容大纲)
Step 5:报告生成 → 输出 6 Part 综合报告
Step 6:HTML 可视化 → 生成 Bento Grid 风格的仪表盘
设计洞见 为什么是「6 步」而不是「1 步搞定」?因为每个步骤的职责必须单一。数据采集和 AI 分析是两种完全不同的能力,混在一起会让系统变得脆弱。这就是软件工程里的「单一职责原则」。
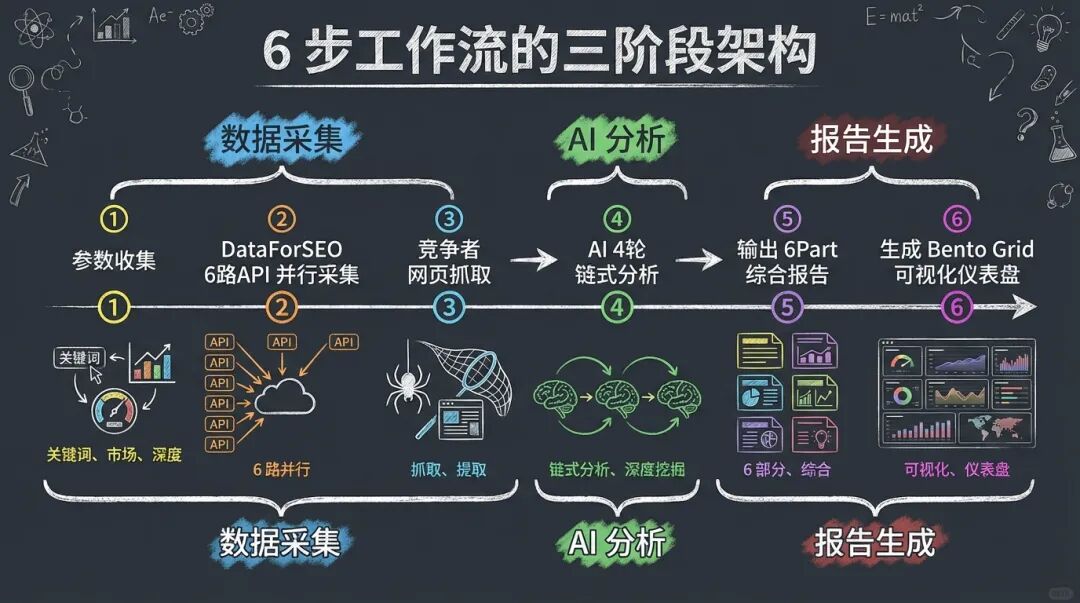
6 步工作流的三阶段架构
这套工作流的第一阶段是「数据采集」,包含 Step 1-3。
工作流从一个简单的问题开始:「你要调研什么关键词?」
别小看这个步骤。一个好的参数收集设计,决定了后续所有步骤的执行质量。
我的设计包含 4 轮提问:
打个比方 参数收集就像点外卖前填地址。你不告诉系统你在哪、要多辣、要不要葱,后面的所有配送都会出问题。
收集完成后,系统创建一个独立的运行目录,所有后续步骤的输出都存在这里:
这是整套工作流的「数据引擎」。
我第一次运行这个脚本时,愣住了。
6 路 API 并行请求,几秒钟内获取了我手动要花 2 小时整理的数据。那一刻我突然理解了什么叫「用系统打败努力」——不是你不够勤奋,是你在用错误的方式勤奋。
一个 Shell 脚本通过 6 路 API 并行请求,在几秒钟内获取:
三秒版 6 路 API 并行 = 用 1 次请求的时间,完成 6 次请求的数据采集。
这里有个设计细节:API 请求是用 Bash 脚本执行的,不是让 AI Agent 去调用。为什么?
因为 API 调用是「确定性任务」,输入输出完全可预测。这种任务用脚本执行更可靠、更快速、更省 Token。
把 Agent 能力留给真正需要「思考」的步骤。
这就是「数据与智能分离」的核心:能用确定性代码解决的,绝不浪费 AI 的「智力」。
DataForSEO 6 路 API 并行采集
有了 SERP 数据,我们知道了排名前 10 的 URL。接下来,抓取这些页面的结构化内容。
这个步骤用 Jina AI 的 Reader 服务抓取网页,再用 Node.js 脚本提取:
底层原理 为什么要抓取竞争者页面?因为 Google 已经用排名「投票」告诉你,这些页面是当前最符合搜索意图的内容。分析它们的共性,就是在「逆向工程」Google 的排名算法。
数据采集完成后,进入最核心的「AI 分析」阶段。
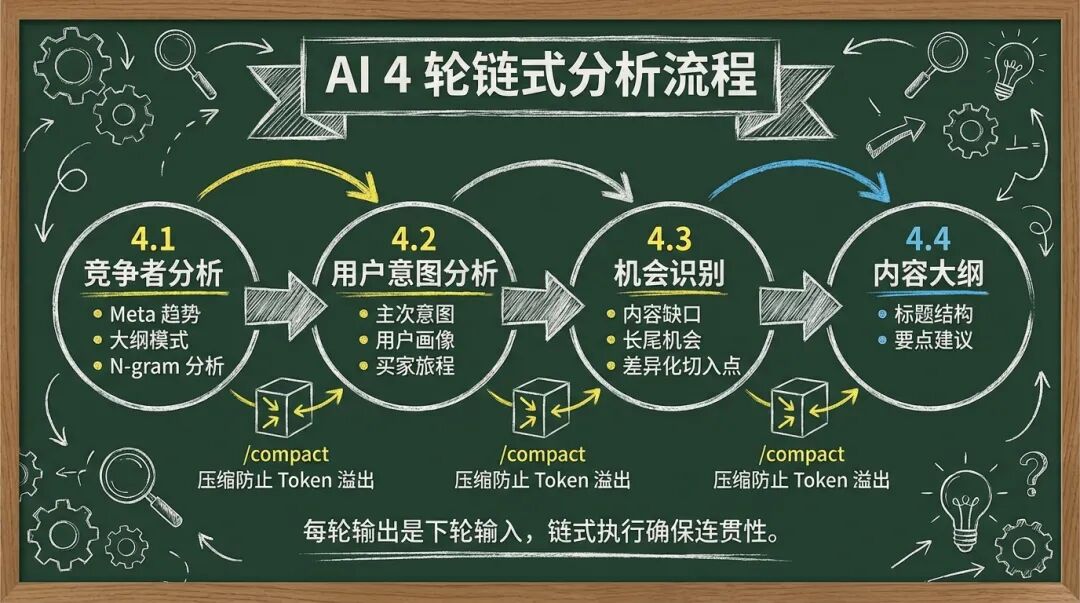
这个阶段只有一个步骤(Step 4),但内部分成 4 个顺序执行的子分析:
这一轮的核心问题:别人在怎么做?
输入:竞争者网页的结构化数据
输出:
这一轮的核心问题:用户真正想要什么?
输入:关键词数据 + 配置参数
输出:
输入:前两轮分析结果
输出:
输入:所有前置分析
输出:
结构拆解 为什么 AI 分析要分 4 轮,而不是一次性分析?因为每轮分析的输出是下一轮的输入。4.3 的「机会识别」必须基于 4.1 的竞争者洞察和 4.2 的用户意图。这就像写论文,你不能在没有文献综述的情况下直接写结论。
这里有个关键的上下文管理策略:每轮分析完成后,必须执行/compact压缩上下文。否则,4 轮分析累积的内容会撑爆 Token 限制。
我知道你在想什么——「这也太麻烦了吧?」
是的,第一次配置确实需要花时间。但我们这群人不都是这样吗?宁愿花 8 小时搭系统,也不愿意花 2 小时重复劳动。
因为我们清楚:系统是一次性投入,重复劳动是永久成本。
AI 4 轮链式分析流程
最后阶段包含 Step 5-6,把分析结果转化为可交付的成果。
把 4 份分析文档整合成一份 6 Part 的战略报告:
把报告转化成 Bento Grid 风格的交互式仪表盘,可以直接在浏览器里打开查看。
说人话 报告是「给人看的」,但 HTML 仪表盘是「给人用的」。一个让决策者快速抓住重点,一个让执行者深入探索细节。
我用这套工作流调研了 "bluetooth earphones" 这个关键词,整个流程从启动到输出报告,大概 5 分钟。
输出包括:
如果手动做这些,保守估计需要 4-6 小时。
效率提升 50 倍。
但这不是重点。重点是:你可以把这套流程复用到任何关键词,质量完全一致。
现在回到开头的问题:为什么 n8n 工作流可以转化为 Skill?
答案藏在两者的底层架构里。
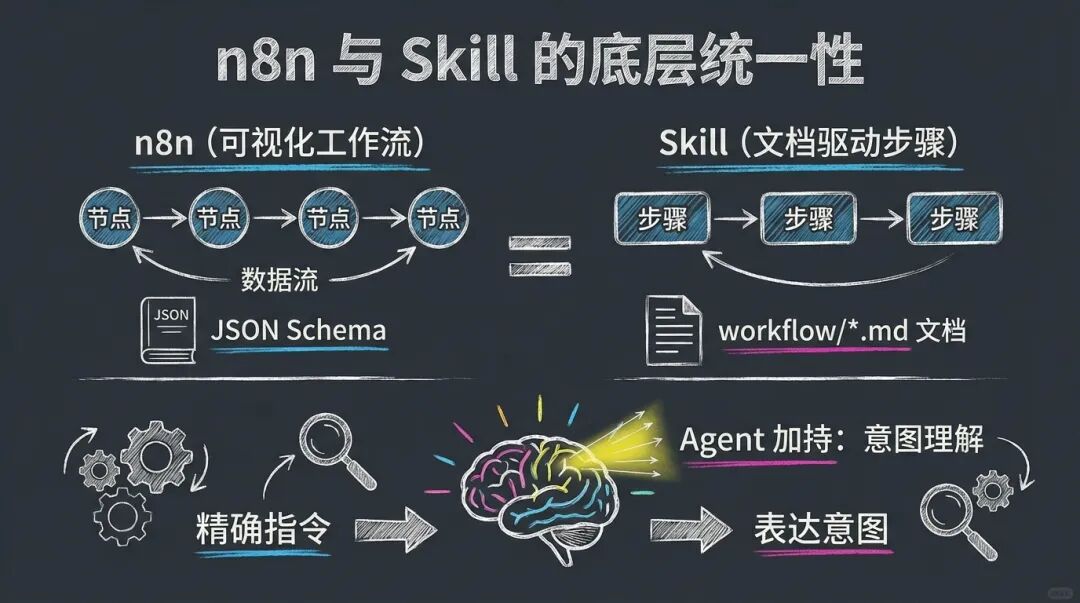
我之前也以为 n8n 和 Skill 是完全不同的东西——一个是可视化拖拽,一个是文档驱动。直到我画出两者的结构图,才发现一个惊人的事实:
它们是同一个范式的两种表达。
| n8n | Skill |
|---|---|
| 节点(Node) | 步骤(Step) |
| 连接(Connection) | 数据流(File) |
| JSON Schema | workflow/*.md |
| 看到这张表的瞬间,我脑子里有什么东西「咔」地一声接通了。 | |
| 等等。 | |
| 如果节点就是步骤,连接就是数据流,那我之前学的所有 n8n 知识—— | |
| 全都能直接用。 | |
| 不是「如何把 n8n 转成 Skill」,而是「它们本来就是一回事」。 | |
| 这个发现让我兴奋了整整一周。 | |
| 但 Skill 有个 n8n 没有的能力:Agent 步骤 。 | |
| 在 n8n 里,如果你想让 AI 分析数据,你需要配置 OpenAI 节点、设计 Prompt、处理响应格式。这需要技术背景。 | |
| 在 Skill 里,你只需要在 workflow/step04-ai-analysis.md 里写清楚「你要分析什么」「输出什么格式」,Agent 会自动完成。 | |
| 这就像从「手动挡」升级到「自动挡」。 | |
| 但「自动挡」只是表象。更深层的变化是:你从「写精确指令」变成了「表达意图」。 | |
| 传统编程:你告诉机器「如何做」(How) Agent 协作:你告诉 AI「做什么」(What) | |
| 这是人机协作范式的根本转变——从「指令执行」到「意图理解」。 | |
| 这意味着什么? | |
| 意味着你之前在 n8n 积累的所有工作流,都可以升级为带 AI 加持的 Skill。你不需要重新学习一套新系统,只需要把「节点」翻译成「步骤」,把「连接」翻译成「数据流」。 | |
| 你过去的积累,不是沉没成本,是可迁移的资产。 |
n8n 与 Skill 的底层统一性
如果你有一个 n8n 工作流想转化为 Skill,可以按这个框架操作:
把 n8n 的节点分成两类:
画出数据如何从一个步骤流向下一个步骤:
为每个步骤创建一个文档,包含:
在主文档里定义:
记住这个 Skill 的核心是「文档驱动」。你不是在写代码,而是在写「执行手册」。Agent 读取手册,按手册执行。手册写得越清晰,执行越准确。
「数据采集 → AI 分析 → 报告生成」这个三阶段架构,不止适用于 SEO 调研。
它是纳瓦尔所说的「代码杠杆」的具体实现——一旦你把流程固化成 Skill,它就能无限次执行,边际成本趋近于零。
这不是工具转化,是把「个人能力」升级成「可复用资产」。
竞品分析
采集竞品官网、App Store 评价、社交媒体提及 → AI 分析定位差异和用户痛点 → 生成竞品情报报告
市场调研
采集行业报告、新闻、专利数据 → AI 分析市场趋势和机会点 → 生成调研报告
设计洞见 这三阶段架构的核心是「数据与智能的分离」。数据采集用脚本(快、稳、便宜),智能分析用 Agent(深、准、灵活)。两者协作,发挥各自优势。
今天分享了一个 SEO 关键词调研工作流的完整设计原理:
如果你也相信「效率不是懒,是把时间留给真正重要的事」——
那 Skill 就是你的下一个武器。
一键复刻
复制这段提示词给 Claude Code,从零复刻完整系统 :
「你是一位高级系统架构师,专精于 AI 驱动的自动化工作流设计。现在,请帮我从零构建一个 SEO 关键词深度调研 Skill。
系统定位 : 这是一个基于 Claude Code Skill 规范的自动化工作流,通过 DataForSEO API 采集关键词数据,结合 AI 链式分析,生成策略规划 + 内容创作指南的综合报告。
核心架构(三阶段六步骤) :
阶段一:数据采集
阶段二:AI 分析
4. Step 04 - AI 链式分析 :启动 4 个顺序执行的 SubAgent,每轮完成后 /compact 压缩上下文
- 4.1 竞争者分析:分析 Meta 趋势、大纲模式、差异化策略
- 4.2 用户意图分析:识别主次意图、用户画像、买家旅程阶段
- 4.3 机会识别:发现内容缺口、长尾机会、差异化切入点
- 4.4 内容大纲:生成推荐标题结构和内容建议
阶段三:报告生成
5. Step 05 - 综合报告 :整合 4 份分析文档,生成 6 Part 报告(执行摘要、关键词策略、竞争格局、用户意图、内容指南、数据附录)
6. Step 06 - HTML 可视化 :将报告转化为 Bento Grid 风格的交互式仪表盘
目录结构 :
关键约束 :
请按上述规范,生成完整的 SKILL.md 和所有 workflow/*.md 文档,确保每个步骤的输入输出清晰定义,数据流完整可追溯。」
📚 更多 Skill 内容:如果你想系统化学习 Skill 的开发、调试、串联和变现,这篇指南串联了全部教程:Claude Code Skill 开发指南:从入门到变现的完整路线图。
📚 更多 n8n 自动化内容:n8n 自动化工作流完全指南
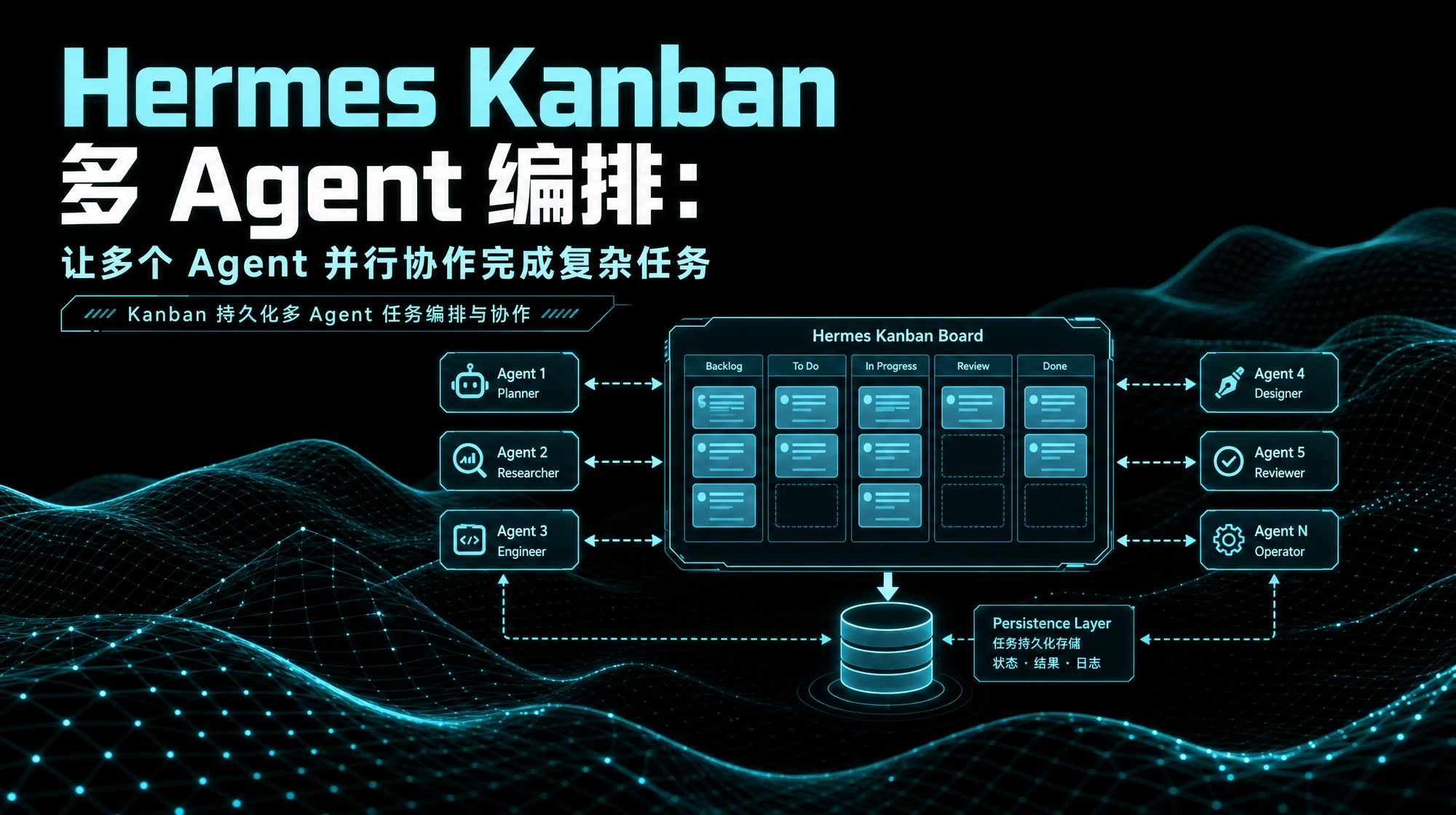
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
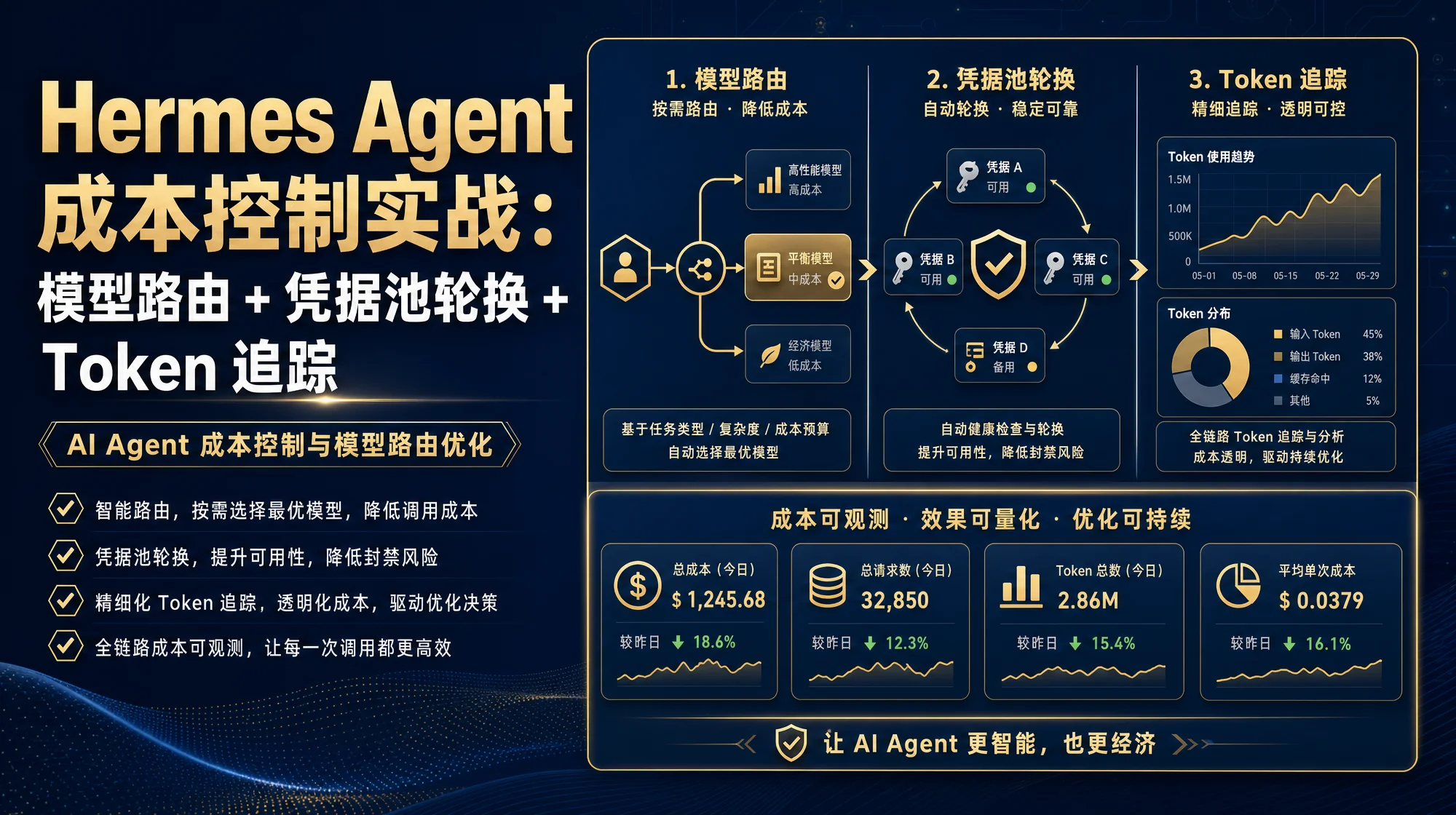
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
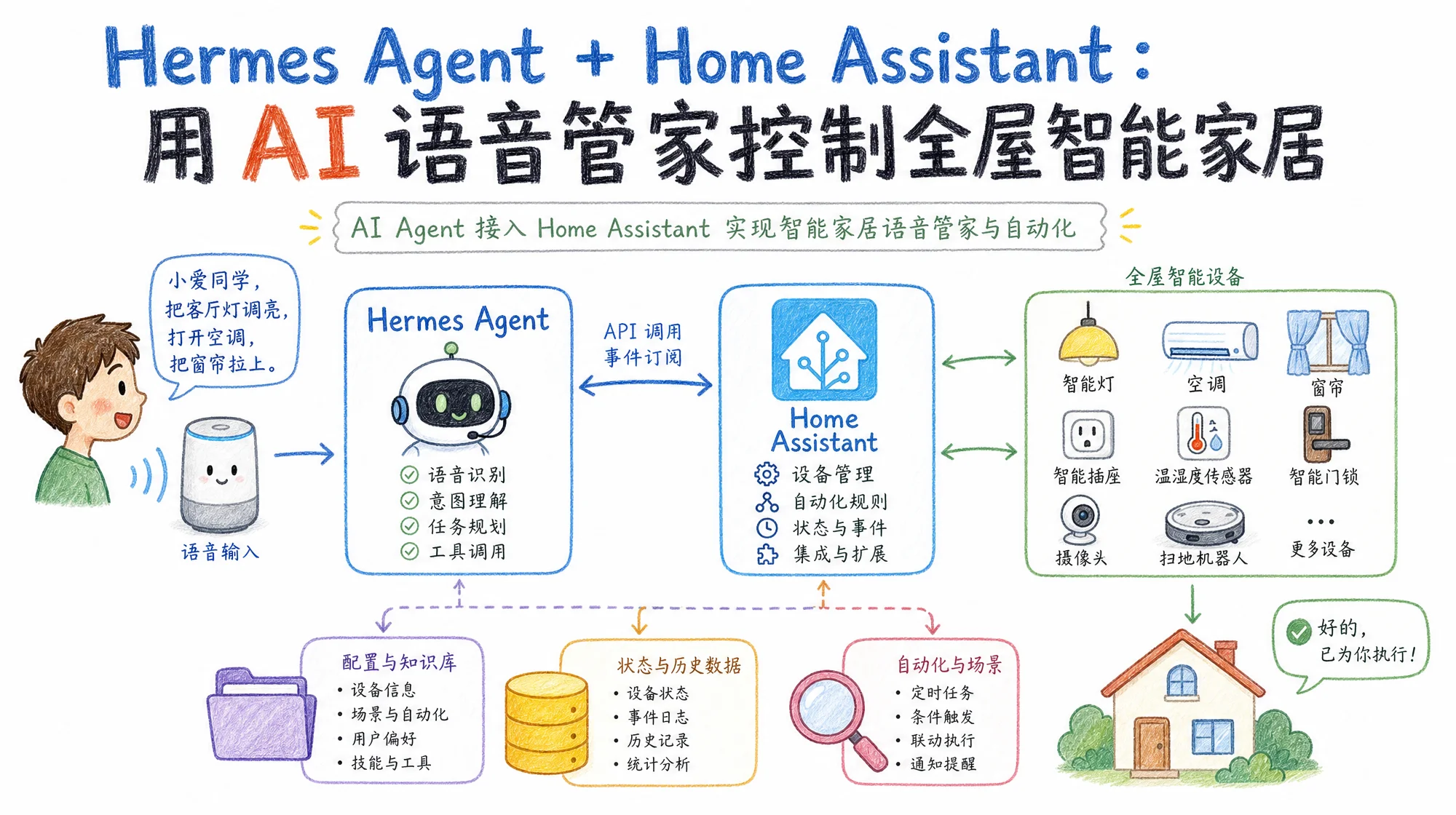
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 的三层记忆系统——SOUL.md 定义身份、MEMORY.md 记录环境事实、USER.md 刻画用户画像——合计约 1,300 Token 的永久记忆预算,在会话启动时冻结注入系统提示词。本文深度拆解 10 层提示词拼装顺序、9 种外部记忆提供商对比、记忆安全扫描机制,附翔宇指针架构实战全文与 SOUL.md 调优四步法。
每周精选 AI 编程与自动化实战内容,直达你的邮箱