Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
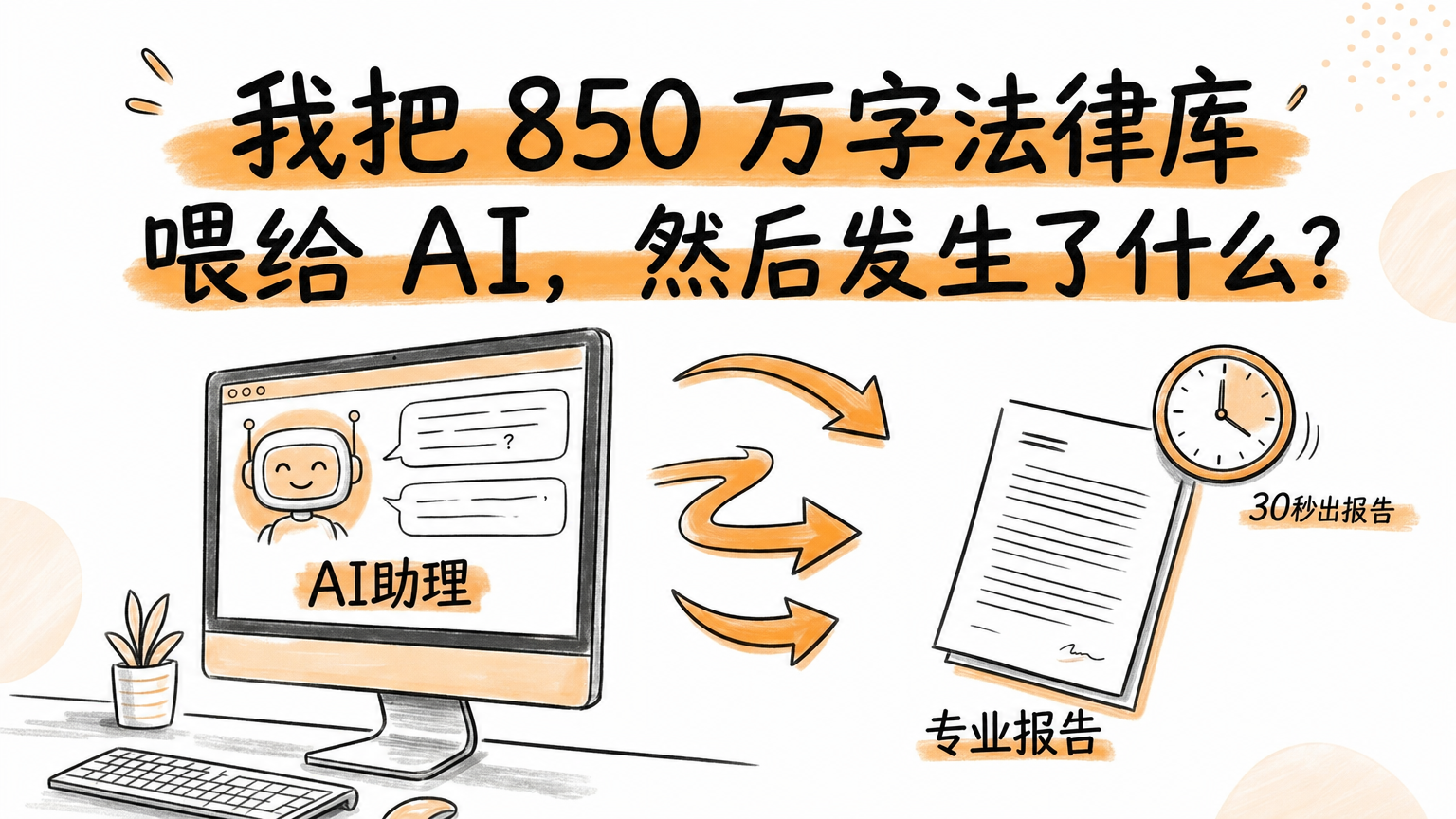
一份 PDF 丢进去,AI 生成争议焦点、适用法规、类似案例、诉讼策略和赔偿测算。这篇拆解我如何用 Claude Code Skill 搭建一个 850 万字法律知识库助理。
翔宇工作流100个原创 Skill 第 6 期
你敢信吗?
一份 PDF 丢进去,30 秒后,18000 字法律咨询报告出来了。
争议焦点、适用法规、类似判例、诉讼策略、赔偿计算——一个不少。
这不是律所的收费服务。
这是我用 Claude Code Skill 搭建的 AI 律师助理。
今天,我把 850 万字法律知识库 + 8 步自动化工作流完整分享。读完这篇文章,你将获得:
先叠个甲:这套系统是「法律助理」,不是「法律替代」。它帮你快速搞清楚「我的案子是什么类型」「有没有过诉讼时效」「大概能赔多少钱」,但最终的专业判断,还是得找执业律师。
如果你是程序员、产品经理、或者任何一个「技术人」——
你一定懂这种感觉:
出了交通事故,对方全责,你躺医院三个月。出院后想索赔,打开百度搜「交通事故赔偿」,跳出来几百万条结果。
你想知道的很简单:
但搜出来的文章要么是律师事务所的广告,要么是法条原文——看完还是不知道自己的情况该怎么办。
找律师咨询?300-500 一小时起步。更关键的是,你连自己的案子属于什么类型都不清楚,去了不知道问什么。
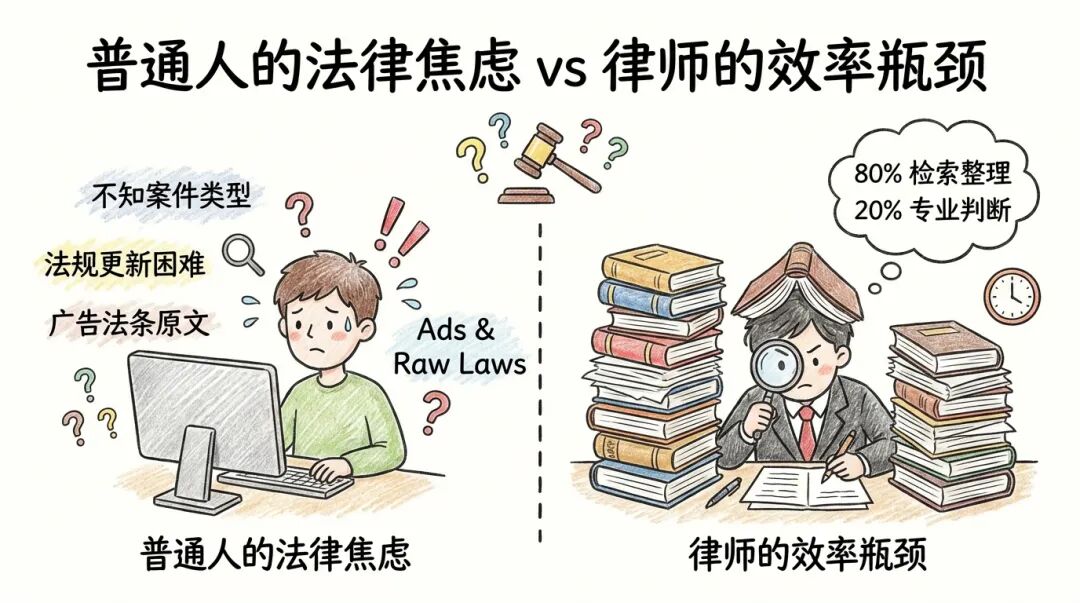
这就是普通人的法律焦虑:
不是不想主张权利,是不知道从哪开始。
🌉 用生活理解技术
这种焦虑就像没学过做菜的人翻菜谱。菜谱写「盐少许」「火候适中」——到底是多少?什么叫适中?你需要的不是菜谱,是有人告诉你「这道菜加 3 克盐,中火炒 2 分钟」。
换个角度。如果你是律师呢?
一个劳动纠纷案子接进来,你需要:
这套流程,一个熟练律师也要花 2-3 天。
问题在于:
「80% 的时间花在检索和整理上,只有 20% 用于真正的专业判断。」
你工作中是不是也有类似的感受?
更要命的是,法规在更新,司法解释在出台,你查的法条可能已经被修订了,你引用的案例可能已经无效了。
Thomson Reuters 调研发现,AI 工具对律师最大的价值是「节省时间」。美国律师协会(ABA)直接说 RAG(检索增强生成)是律师的「game-changer」。
但这些工具大多是英文的、付费的、需要复杂配置的。
我想做一个中文的、开箱即用的 。
普通人的法律焦虑 vs 律师的效率瓶颈
先回答一个基础问题:Skill 是什么?
Claude Code 是 Anthropic 出品的 AI 编程工具。它最强大的能力是:你可以用自然语言定义一套工作流,让 AI 按照你设计的步骤自动执行 。
这套自定义工作流,就叫 Skill。
💡 说人话
Skill 就像你教会 AI 一套「标准作业流程」。以后只要说一声「执行这个流程」,AI 就会按部就班地完成,不需要你每次都重复指挥。
法律咨询非常适合用 Skill 实现。关键原因如下:
1. 流程标准化程度高
无论什么案件,咨询流程都是类似的:
这套流程可以被拆解成明确的步骤,而明确的步骤正是 Skill 的强项。
2. 知识库边界清晰
法律知识不是无限的。现行有效的法律法规,全部整理出来也就几千万字。
这和通用问答不一样——通用问答的知识边界是整个互联网,而法律咨询的知识边界是法律法规数据库。边界清晰,意味着可以做到「全覆盖」。
3. 输出格式固定
法律咨询的输出物是什么?法律意见书、咨询报告、诉讼策略建议。
这些文书有固定的格式和结构,AI 只需要按模板填充内容。格式固定,意味着输出质量可控。
🏗️ 设计洞见
判断一个场景适不适合用 AI 自动化,看三点:流程是否可拆解、知识是否有边界、输出是否可验证。法律咨询三条全中,所以是个好赛道。
你可能会问:ChatGPT 不是也能回答法律问题吗?
确实可以。但有两个关键区别:
1. 幻觉问题
ChatGPT 可能会「编造」法条。它告诉你「根据民法典第 XXX 条」,但那条可能根本不存在。
专业知识系统不会。因为它只从你预先整理的知识库中检索,检索不到就告诉你「未找到相关法规」。
2. 可溯源性
ChatGPT 的回答没有来源。你不知道它是从哪学的、是否过时。
专业知识系统的每一条输出都有出处:「《民法典》第 1213 条,来自 laws/civil.md 第 542 行」。
一句话总结 :ChatGPT 是「看起来懂」,专业知识系统是「真的懂」。
塔勒布在《反脆弱》里提过一个概念叫「杠铃策略」:
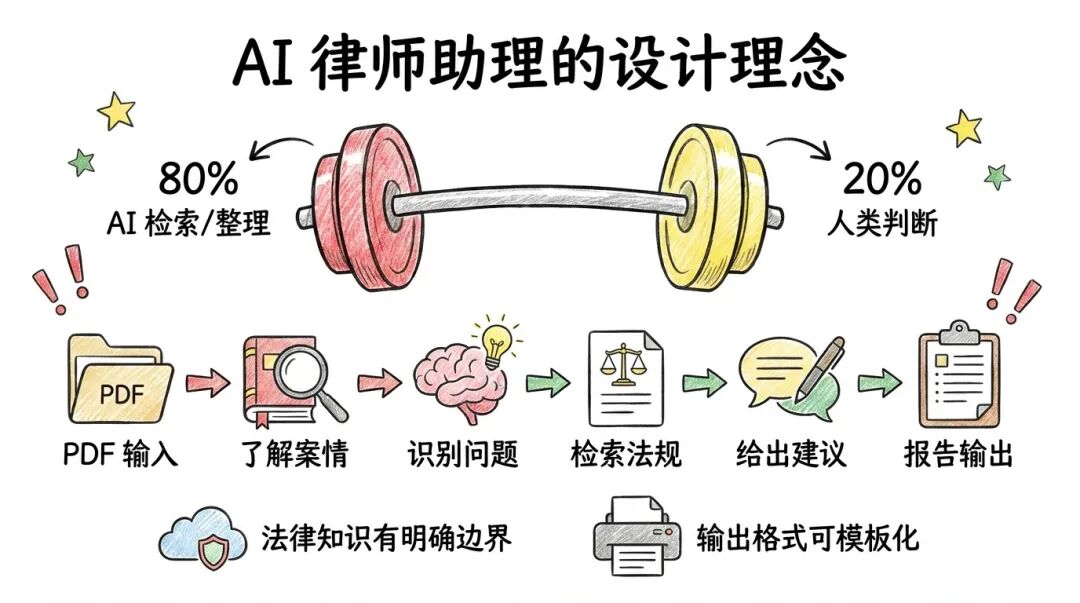
把风险分成两端——80% 放在极度保守的地方,20% 放在高风险高回报的地方。
法律咨询也是这个逻辑:
AI 不是来抢律师饭碗的。它是来帮律师把 80% 的苦力活干了,让律师专注于那 20% 真正需要人类智慧的部分。
同样的逻辑,也适用于你。
在继续之前,我要再强调一次这个系统的定位:
它是「法律助理」,不是「法律替代」 。
它能帮你做的事:
它不能帮你做的事:
把它想象成「法律版的 114 查号台」:它帮你找到方向,但走哪条路还得你自己决定。
这套系统帮我在 30 秒内完成了律师 3 天的工作。
不是夸张。后面我会详细拆解怎么做到的。
AI 律师助理的设计理念
一个 AI 助理的能力上限,取决于它背后的知识库。
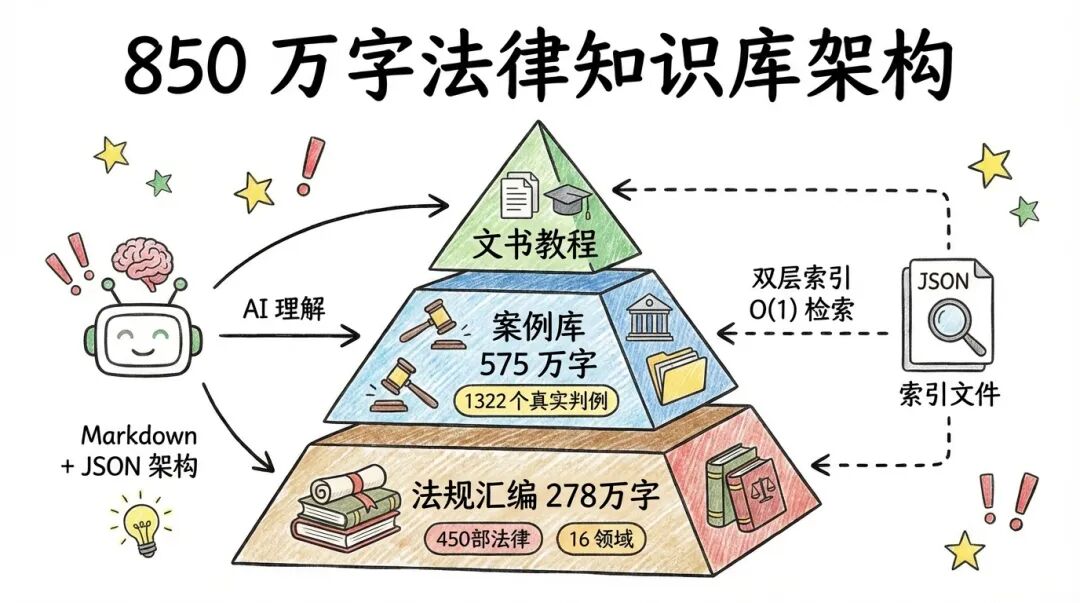
我的法律知识库包含三大模块:
法规汇编 :450 部法律、13,011 条款、278 万字,覆盖法考大纲全部领域
法院案例 :1,322 个案例、23 大类、575 万字
文书教程 :5 本书、23 门课程,覆盖起诉状等全流程
合计:853.7 万字。
📝 记住这个
这 16 个文件覆盖了法考大纲的全部范围。如果你是法律专业学生,这套知识库本身就是一个学习资料库。
读到这里,你可能觉得:「16 个领域、450 部法律,整理起来得多久?」
说实话,整理知识库花了我 3 周。
但这 3 周的投入,换来的是以后每次咨询只需要 30 秒 。
这就是「一次性投入,永久复利」的威力。
案例库的数据来自案例研究院出版的年度案例汇编,包含:
民事纠纷(18 类) :
刑事案例(4 类) :
有了数据还不够,关键是怎么让 AI 快速找到它需要的内容。
我设计了一套「双层索引」系统:
第一层:JSON 索引文件
比如,当 AI 需要查找「劳动合同法第四十七条」时,它的执行路径是:
整个过程不需要全文扫描,检索复杂度是 O(1)。
第二层:Markdown 语义结构
法规文件本身也有结构化设计。每部法律用 H2 标题,每章用 H3 标题,每条用粗体标记。这样即使没有索引,AI 也能通过正则表达式快速定位。
🧩 结构拆解
为什么要双层索引?因为 AI 的上下文窗口有限。如果每次检索都要读取全部 850 万字,不仅慢,还可能超出长度限制。双层索引让 AI 可以「精确打击」,只读取需要的部分。
850 万字法律知识库架构
有了知识库,接下来是工作流设计。
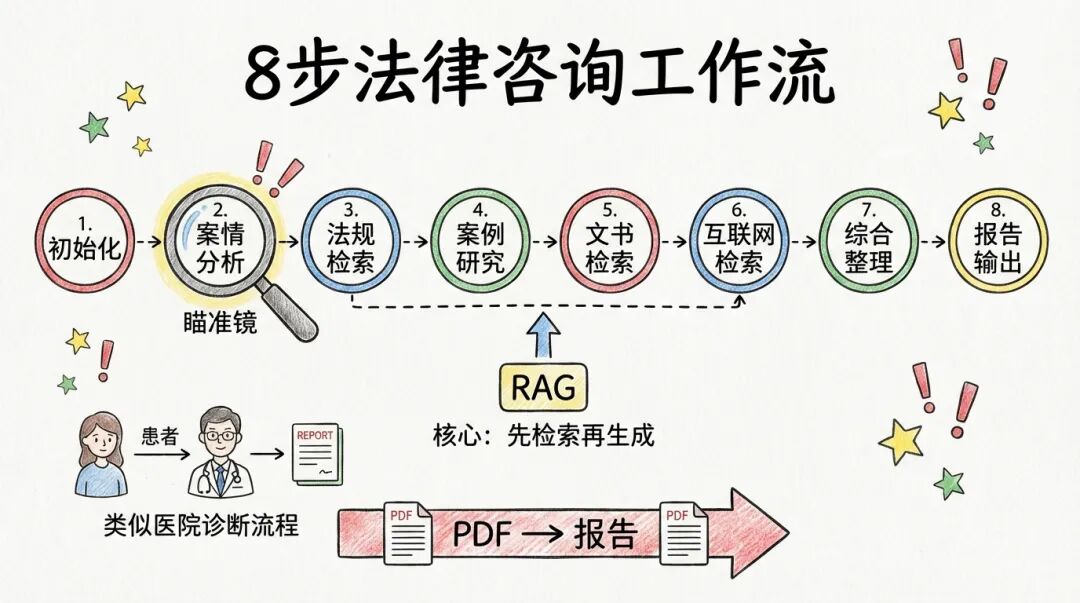
我把法律咨询拆解成 8 个步骤,每个步骤职责单一、输入输出明确:
Step 01 初始化 :收集用户输入,创建运行目录 → 输出 config.json
Step 02 案情分析 :提炼法律问题,分析时效管辖 → 输出 analysis.json
Step 03 法规检索 :定位适用法条 → 输出 laws.md
Step 04 案例研究 :查找类似判例 → 输出 cases.md
到这里,暂停一下。
前 4 步完成了什么?从一份混乱的案情描述,变成了「法律问题 + 法规 + 案例」的结构化素材 。
这就是 RAG(检索增强生成)的核心:先检索,再生成 。
继续。
Step 05 文书检索 :获取文书写作指导 → 输出 docs.md
Step 06 互联网检索 :补充最新信息 → 输出 web.md
Step 07 综合整理 :合并所有信息 → 输出 answers.md
Step 08 报告输出 :生成最终报告 → 输出 report.md
用户触发 Skill 后,系统会问三个问题:
然后创建一个运行目录,把所有配置保存到 config.json。
支持的文档格式 :PDF、Markdown、纯文本。PDF 会自动转成文本。
这是整个工作流的核心步骤。
如果说知识库是「弹药库」,案情分析就是「瞄准镜」——方向对了,后面每一步都有意义。
AI 会从案情中提炼出:
1. 法律问题清单
把复杂的案情拆解成 2-5 个具体的法律问题,每个问题包含:
2. 诉讼时效分析
判断案件有没有超过法定期限:
3. 管辖权分析
确定案件应该去哪个机构:
❓ 你可能会问
为什么要先分析时效和管辖?因为这两项决定了案件能不能立案。如果时效已过,你准备再多材料也没用。如果管辖错误,会被直接驳回。这是「门槛问题」,必须先确认。
根据 Step 02 提炼的法律问题,在知识库中检索适用的法规。
检索策略:
比如,对于「超载导致的交通事故」,系统会检索到:
在 1,322 个案例中查找与当前案件相似的判例。
检索维度:
输出格式:
根据案件类型,检索相关的法律文书写作指导。
比如交通事故案件,系统会检索:
用 brave_web_search 工具补充最新信息。
为什么需要这一步?因为:
互联网检索是对本地知识库的补充,确保信息时效性。
把前面所有步骤的输出整合起来,按法律问题逐一回答。
整合原则:
把综合整理的结果转化为可读的咨询报告。
报告结构:
🎯 打个比方
这 8 步就像医院的诊断流程:挂号(初始化)→ 问诊(案情分析)→ 验血验尿(法规/案例检索)→ 影像检查(互联网补充)→ 会诊(综合整理)→ 开诊断报告(报告输出)。每一步都有明确的输入输出,步步有章法。
8 步法律咨询工作流
理论讲完了,看个真实案例。
一份交通事故 PDF 文档,内容大意是:
2024 年 11 月 15 日,王某驾驶物流公司的新能源货车(核载 2 吨,实载 4.8 吨,超载 140%),在下坡弯道制动失灵,撞伤行人李某。
交警认定王某全责。李某经鉴定为九级伤残,误工 180 天,护理 90 天,后续治疗费约 3.5 万元。
车辆投保了交强险和商业三者险(100 万元),保险合同约定「违反安全装载规定的,增加免赔率 10%」。
李某想知道:能赔多少钱?找谁赔?
Step 02 案情分析后,系统识别出 4 个法律问题:
Q1:商业三者险 10% 免赔条款是否有效?
这是保险合同纠纷的常见争议。保险公司会说「你超载了,合同约定免赔 10%」。但法律规定,免责条款必须「提示 + 明确说明」,否则不生效。
Q2:物流公司是否承担用人单位责任?
王某是给物流公司开车的,出了事故,公司要不要负责?关键看王某和公司是什么关系:劳动关系?劳务关系?临时聘用?
Q3:赔偿责任如何在各被告之间划分?
涉及保险公司、物流公司、驾驶员三方,赔偿顺序是什么?
Q4:赔偿金额如何计算?
九级伤残能赔多少?误工费怎么算?护理费怎么算?
针对 Q1,系统检索到:
针对 Q2,系统检索到:
针对 Q3,系统检索到:
针对 Q4,系统检索到:
系统找到 5 个高相关案例,其中最有参考价值的是:
(2022)鲁 08 民终 7287 号
济宁中院认定:保险合同中看似「适用条件」的条款,如果实质上减轻保险人责任、限制被保险人权利,应认定为免责条款。保险公司未用加粗加黑方式提示的,该条款不生效。
(2023)京 02 民终 14432 号
北京二中院认定:判断用人单位用「从属性」标准——谁下达工作指令、谁监督工作、谁承担经营风险。即使没有书面劳动合同,事实上完成公司工作任务的,也构成用人关系。
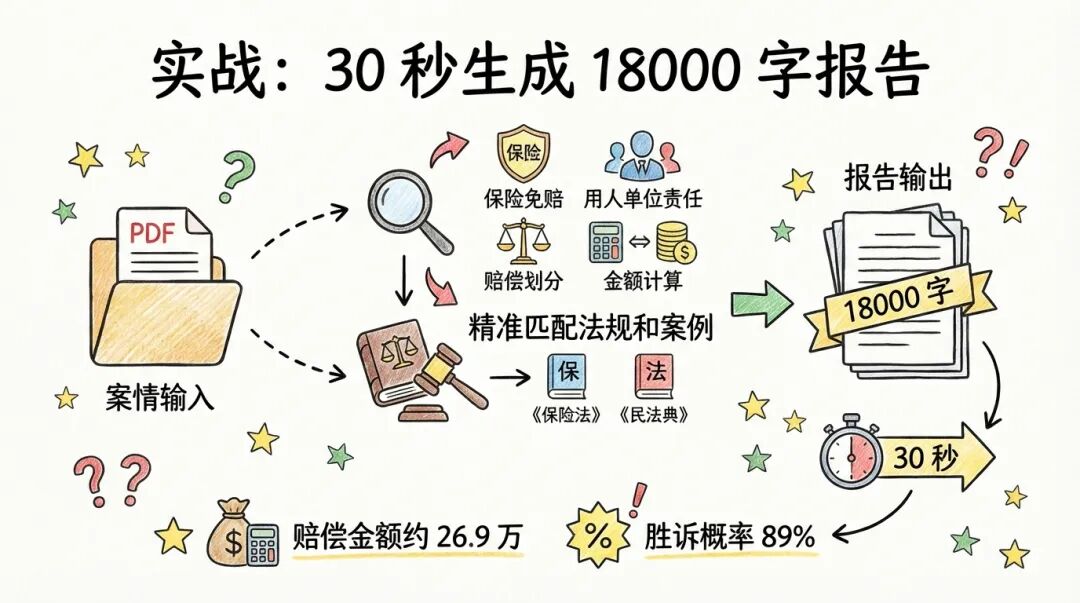
最终输出的报告长达 18000 字,包含以下核心结论:
诉讼时效 :3 年,截止 2027 年 11 月 15 日,风险等级「低」
Q1 结论 :10% 免赔条款大概率无效。保险公司难以证明已尽提示说明义务,参考案例支持。
Q2 结论 :物流公司应承担用人单位责任。王某称「按公司调度指令装货」,构成职务行为。
Q3 赔偿顺序 :
Q4 赔偿计算 (预估):
胜诉概率评估 :89/100,A 级(高),预估胜诉率 80%-90%
从 PDF 输入到 18000 字报告输出,全程约 30 秒。
这 30 秒里,系统完成了:案情解析、时效计算、法规检索、案例匹配、赔偿估算、报告生成。
换成人工,这是 2-3 天的工作量。
想象一下:
你拿着这份报告走进律师事务所。
律师翻了两页,抬头看你的眼神变了——「你这准备工作做得比大部分当事人都专业。」
这不是想象。这是 AI 给你的底气。
实战:30 秒生成 18000 字报告
讲完用法,讲讲底层技术。
法律文档用 Markdown 存储有三个好处:
1. 原生支持层级结构
法律文件天然有层级:篇 → 章 → 节 → 条 → 款 → 项。Markdown 的标题层级(# ## ### ####)正好对应。
2. 纯文本便于版本控制
用 Git 管理,每次法规修订都有记录。想回溯历史版本?git log 就行。
3. AI 友好
Markdown 是 AI 最容易理解的文档格式。不需要解析 Word 的 XML,不需要处理 PDF 的编码,直接读取、直接理解。
如果你是程序员,你一定懂这种设计哲学:
用最简单的工具,做最复杂的事情。
Markdown + JSON + Git,都是程序员的「老朋友」。用熟悉的工具链,做不熟悉的领域,学习成本降到最低。
Markdown 解决了存储问题,JSON 解决了检索问题。
场景 1:模糊检索
用户说「劳动法」,到底指《劳动法》还是《劳动合同法》?
JSON 索引里的 alias-map.json 记录了所有简称到正式名称的映射,让 AI 能处理简称、别名、口语化表达。
场景 2:精确定位
用户要查「民法典第 1213 条」,不需要扫描整个民法篇文件。
article-index.json 记录了每个条款在哪个文件的哪一行,AI 直接用 Read 工具的 offset 参数跳到那几行。
场景 3:案例联想
用户的案件是「交通事故 + 超载 + 保险免赔」,应该查哪些案例?
case-index.json 记录了关键词到文件的映射,让 AI 能做快速联想。
🔬 底层原理
这套设计的本质是「空间换时间」。预先建立索引,检索时直接查表,把 O(n) 的全文扫描变成 O(1) 的索引查找。这是数据库的基本原理,我们只是把它应用到 AI 知识库。
每次运行都会创建一个目录,所有中间结果写入文件:
目录结构 :
为什么要这样设计?
1. 断点续跑
万一中途出错,从 progress.json 读取进度,从断点继续。
2. 结果可审计
每一步的输出都保留,方便回溯和调试。
3. 模块独立
每个 Step 只依赖前序输出文件,不依赖全局状态,可以单独测试。
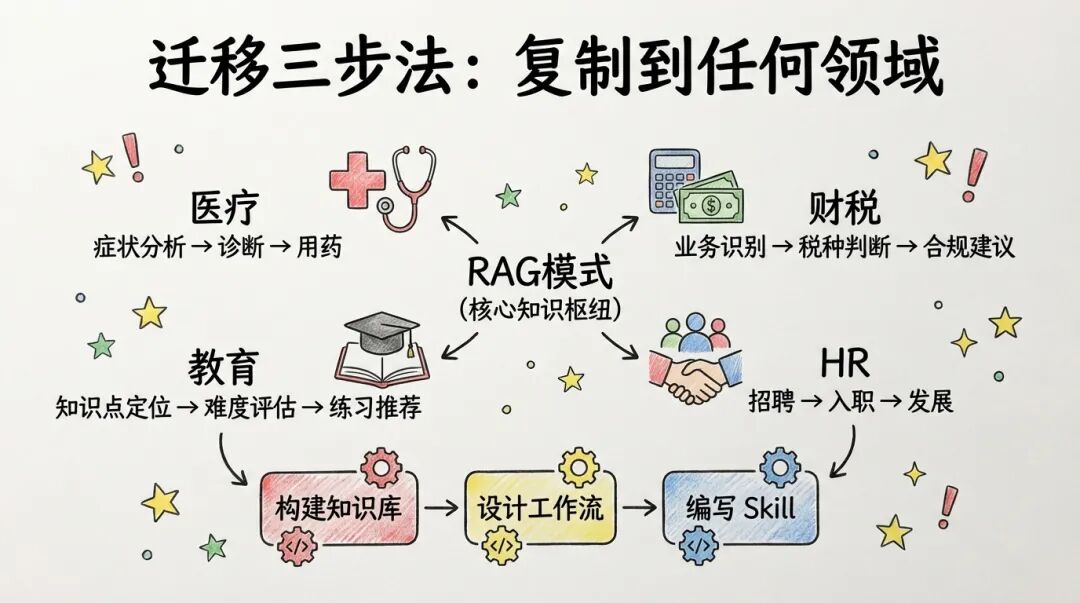
这套系统的价值不仅是「法律咨询」,而是提供了一种「结构化知识 + 自动化检索」的通用模式。
这种模式可以迁移到任何垂直领域:
知识库:
工作流:
知识库:
工作流:
知识库:
工作流:
Step 1:构建知识库
把领域知识整理成 Markdown 文件,建立 JSON 索引。
关键点:
Step 2:设计工作流
把业务流程拆解成步骤,定义每一步的输入输出。
关键点:
Step 3:编写 Skill
用 Markdown 描述工作流逻辑,让 Claude Code 按流程执行。
关键点:
🧩 结构拆解
迁移的核心是三件事:知识结构化、流程标准化、输出模板化。只要你的领域满足这三点,就可以套用这种模式。
迁移三步法:复制到任何领域
真正的复利,不是重复劳动,是重复使用已经打磨好的系统。
下面这段提示词,就是我花 3 周打磨出来的「系统」。你可以直接拿去用。
读到这里,先做一件事 :
把下面这段提示词复制到备忘录,或者直接保存这篇文章。
然后,下次遇到法律问题——或者医疗、财税、任何专业领域的问题——你就有底气了。
复制下方提示词给 Claude Code,从零构建你自己的「领域知识助理」:
你是一位高级系统架构师,专精于 AI 驱动的知识管理系统设计。我需要你帮我从零构建一个「垂直领域知识助理」,参考法律咨询 Skill 的设计模式。
核心目标 : 构建一个基于 RAG(检索增强生成)理念的领域知识助理,实现「知识结构化 + 检索自动化 + 报告生成」的全链路自动化。
系统架构 :
技术规格 :
实现步骤 :
约束条件 :
请先询问我要构建哪个领域的知识助理,然后一步步引导我完成构建。
这套法律咨询 Skill 只是「垂直领域知识系统」的一个实战案例。在课程中,你还会学到跨境电商数据获取、SEO 实战、微信公众号自动化、小红书内容创作、PPT 批量生成、视频剪辑工作流等多个实战项目。
如果你想获取完整资源、系统学习 AI 编程工作流,欢迎加入 翔宇工作流:AI 编程实操课 。
写到这里,我想起一件事。
几年前,我一个朋友遇到劳动纠纷,被公司拖欠了 3 个月工资。他不知道怎么办,在网上查了一周,越查越焦虑,最后放弃了。
如果当时有这套系统,30 秒就能告诉他:劳动仲裁、劳动合同法第 30 条、追诉时效 1 年、预期回收 100%。
很多人不是不想主张权利,是被信息差困住了。
回到开头那个问题:普通人遇到法律问题怎么办?
以前的答案是:要么硬着头皮自己查,要么花钱请律师。
现在多了一个选项:用 AI 做初步诊断 。
它不会替代律师,但它能帮你:
这就像去医院之前先用丁香医生查查症状——不是为了自己开药,是为了和医生沟通时不至于一问三不知。
三个核心洞见,再说一遍:
普通人对抗专业壁垒的唯一武器,就是工具。
850 万字知识库 + 8 步工作流 = 一份 PDF 进去,18000 字专业报告出来。
这就是 AI 带给普通人的法律信息普惠。
如果你是那种「不愿被信息差困住」的人——
如果你相信「工具能放大能力」——
那这套系统,就是为你准备的。
如果觉得有用:
📚 更多知识库内容:AI 知识库构建指南
📚 更多 Agent 工作流内容:Agent 工作流实战指南:从单个 Agent 到十人团队的完整搭建路径
AI 编程实操课:Claude Code + Codex + Agent 工作流,覆盖一人公司、自媒体自动化、AI 副业全场景。实战教程 + 最佳实践 + 源码包,跟着做就出成果。国内版-FlowUS | 国际版-BMC
国内版和国际版内容完全相同,根据你的支付渠道自行选择即可。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
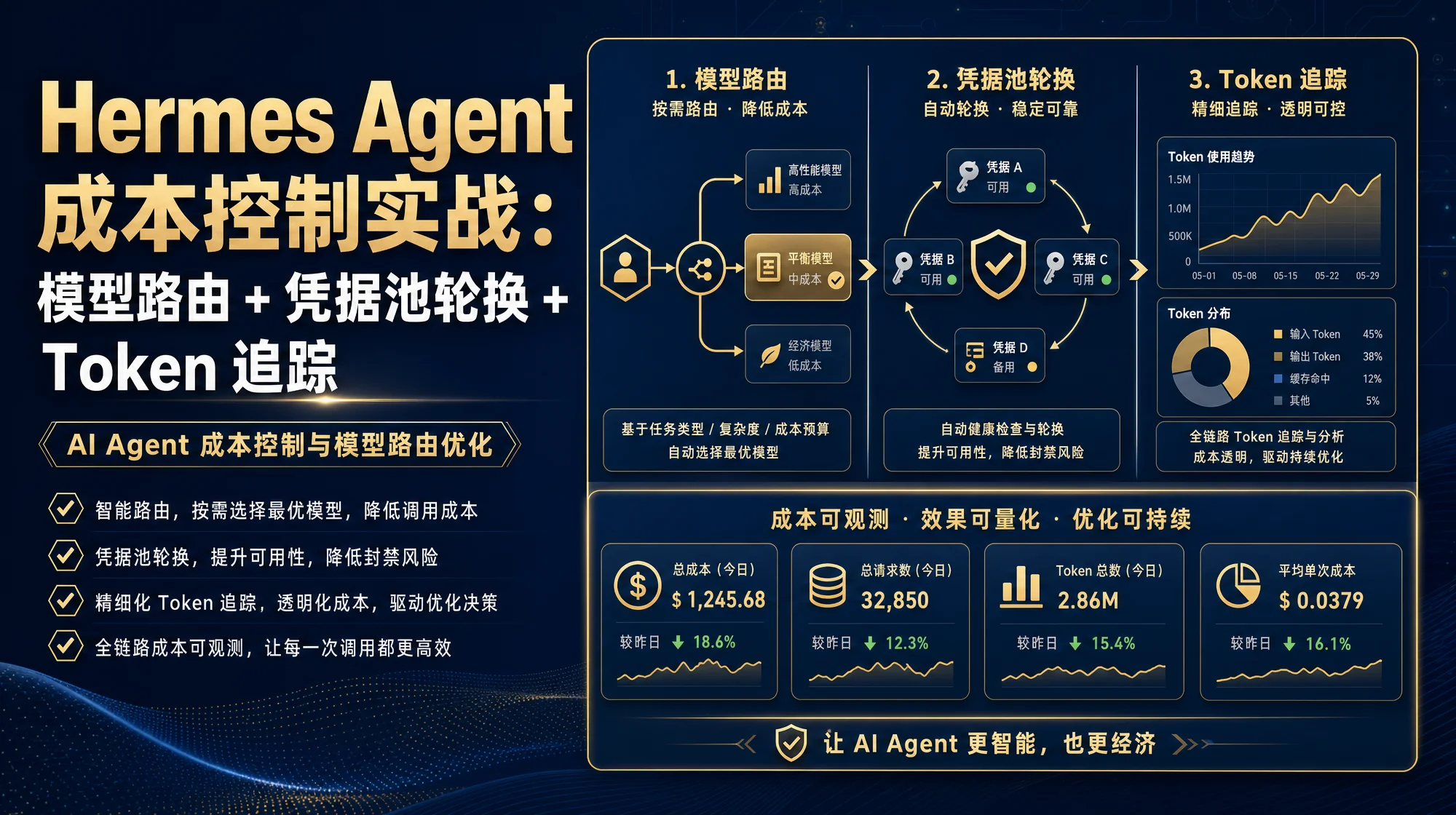
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
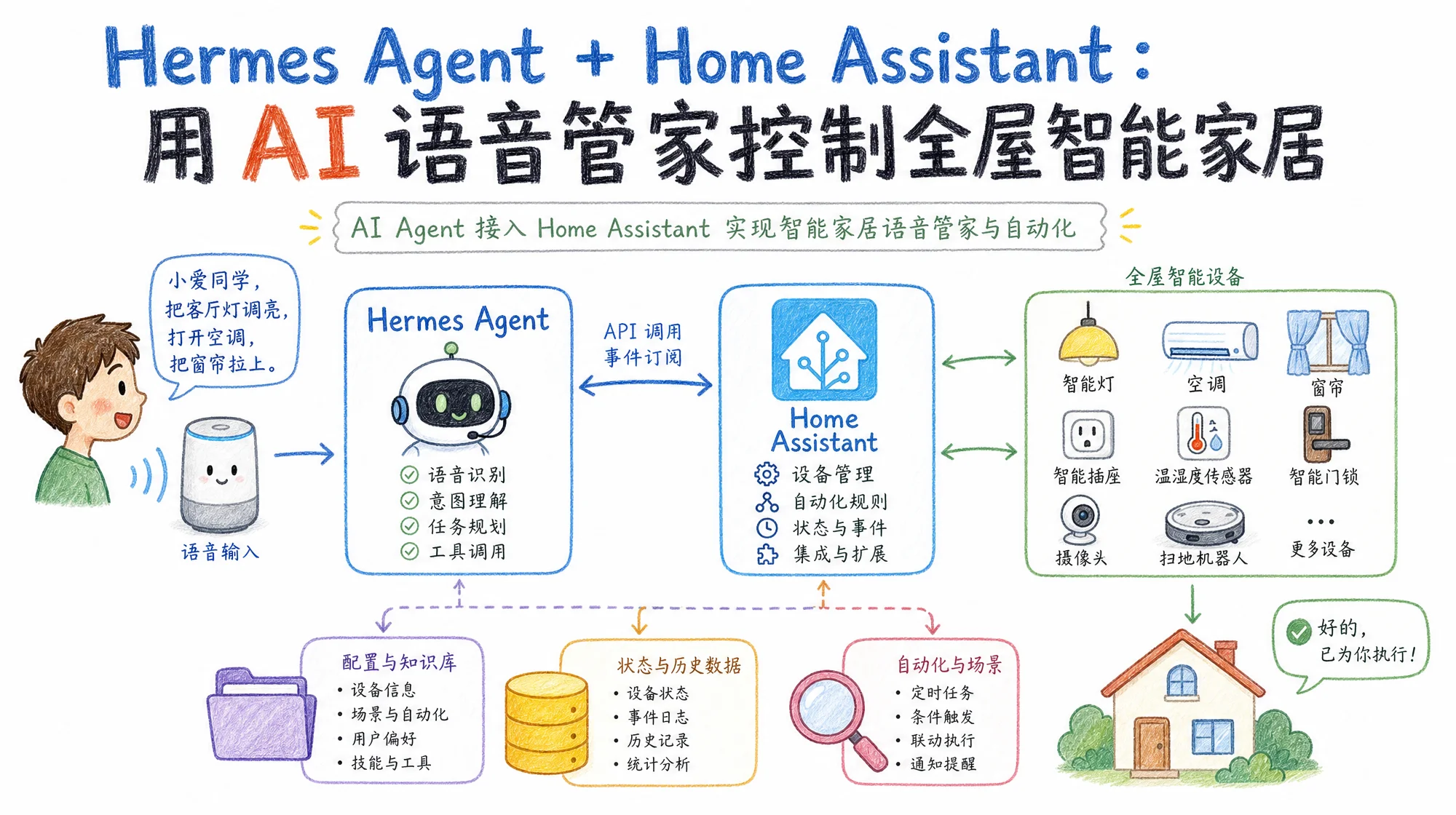
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 支持三种本地推理后端:Ollama 一键启动、LM Studio 可视化管理、vLLM 生产级吞吐。本文覆盖完整接入配置、64K 上下文铁律、模型选型矩阵(按硬件/任务/语言推荐)、社区高频痛点解决方案,以及翔宇 GLM→DeepSeek→Gemini 三模型实战策略。
每周精选 AI 编程与自动化实战内容,直达你的邮箱