AI 知识库最佳实践:用纯文件系统构建 Agent 可用的知识库
向量数据库太重、RAG 管线太脆——用 CLAUDE.md 多级路由 + 纯文件系统,从零搭建一个 AI Agent 能直接读懂的知识库。本文拆解 1000+ 文件规模的真实架构,给你一套可直接抄作业的方案。
向量数据库太重、RAG 管线太脆——用 CLAUDE.md 多级路由 + 纯文件系统,从零搭建一个 AI Agent 能直接读懂的知识库。本文拆解 1000+ 文件规模的真实架构,给你一套可直接抄作业的方案。
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
8 大 AI Agent 全维度对比:从 GitHub Stars 到安全记录,从月度成本到真实场景——Hermes 自我进化、OpenClaw 网关编排、Claude Code 编码天花板,附决策树和双修方案。
写博客最消耗人的往往不是写作,而是调研、SEO、配图、上传和发布这些机械流程。这篇拆解我如何把博客创作做成 AI 工作流:三阶段十步骤,从选题到草稿上线。

翔宇工作流原创100个Skill: 第 4 期
我让 AI 替我写博客,结果比自己写更好
给厌倦手动发文的独立开发者和技术博主
如果你是独立开发者、技术博主或内容创业者——
这篇文章就是写给你的。
你一定有过这种体验:
想运营一个 WordPress 博客,但每次发文都要重复「写稿 → SEO → 配图 → 上传 → 发布」这套流程。一篇文章折腾下来,光是机械劳动就占了一半时间。
写作本身可能只要 2 小时,但整套流程走完往往要半天。
更要命的是——第一篇你觉得新鲜,第十篇开始厌倦,第一百篇就想放弃。
我曾经也是这样。
有人选择妥协——降低发文频率,接受「内容不够持续」的现实。
我选择升级——让 AI 接管机械流程,把注意力留给创作本身。
今天分享的,就是这套升级方案。
一条命令触发,从话题研究到文章上线全程无需人工干预。这不是玩具,是真正能跑通生产环境的工作流。
读完这篇,你将获得:
先说痛点。
传统 WordPress 发文流程是这样的:
每一步都需要人工操作,切换工具,等待响应。
🎯 打个比方
传统发文就像手工组装一台电脑:每次都要自己接线、装系统、配环境。而自动化工作流是流水线生产:你只需要下单,成品自动送到手上。
传统发文流程的痛点
这套系统的核心设计理念是渐进式披露 :把整个流程分成三个阶段,每个阶段有明确的输入输出边界。
这个阶段的目标是「收集原材料」。
Step 01:初始化
执行者是主 Agent。通过交互式问答收集运行参数:
收集完成后,系统自动从话题中提取 3-5 个搜索关键词,创建运行目录,写入配置文件。
Step 02:广度检索
执行者是 Python 脚本。根据关键词调用搜索引擎 API,获取候选文章 URL 列表。
这一步的设计要点是多引擎降级 :如果 Brave Search 失败,自动切换到 Exa,再失败切换到 Firecrawl。确保不会因为单点故障中断流程。
Step 03:深度抓取
执行者还是 Python 脚本。从候选列表中取 TOP N 个 URL,用 Firecrawl 抓取全文内容,转换为 Markdown 格式存储。
📝 记住这个
阶段一全程由脚本执行,不消耗 Agent 上下文。这是刻意设计的——
把「数据搬运」和「智力劳动」分开,让 Agent 的 token 用在刀刃上。
这就是架构设计的魅力:
你以为 AI 能力有限?不,是你没找到正确的使用方式。
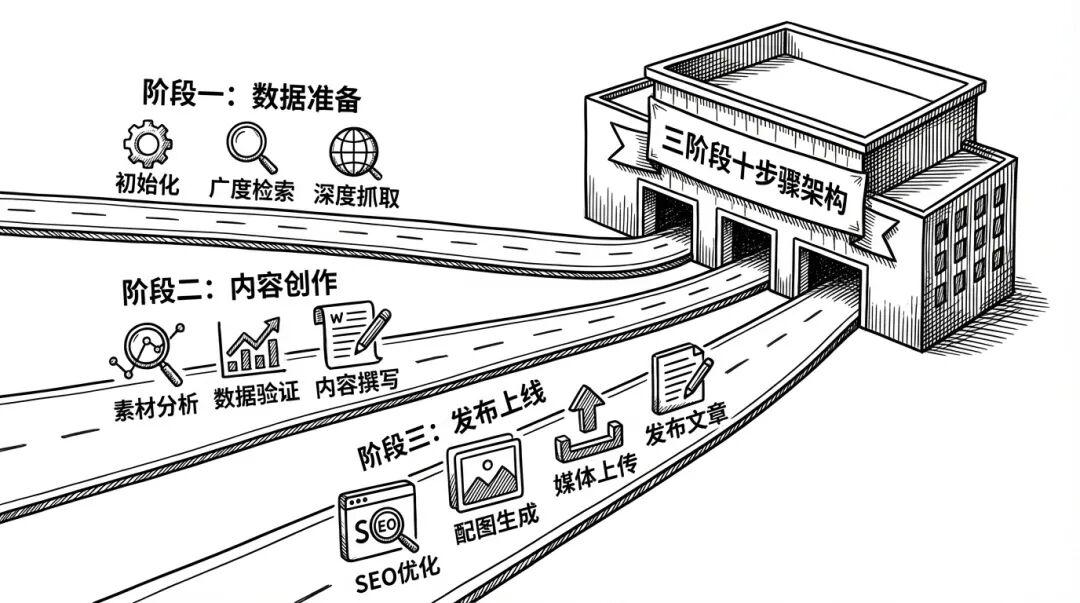
三阶段十步骤架构
这个阶段的目标是「把原材料变成成品」。
Step 04:素材分析
执行者是 SubAgent。读取抓取的全文,生成结构化研究报告:
这份报告是后续写作的「弹药库」。
Step 05:数据验证
执行者是 SubAgent。对研究报告做事实核查:
验证通过的内容才进入写作环节。
Step 06:内容撰写
执行者是 SubAgent。这是整个系统最核心的一步。
系统会加载预设的「写作人格」,一份详细的风格指南,定义了语言调性、结构规范、禁用词表等。Agent 按照人格配置,结合素材报告,生成初版文章。
💡 说人话
「写作人格」就是给 AI 的「人设说明书」。你想让它写成什么风格,就写一份什么样的说明书。换人设 = 换说明书,不用改代码。
我还记得第一次看到文章自动生成的那一刻。
从空白到 3000 字,连标题、配图建议都有了——整个过程不到 5 分钟。
那种感觉,只有经历过的人才懂。
这个阶段的目标是「让成品上架」。
Step 07:SEO 优化
执行者是 SubAgent。基于文章内容生成 SEO 元数据:
Step 08:配图生成
执行者是 SubAgent + 脚本协作。
这个设计让配图风格可控,同时避免调用昂贵的图像生成 API。
Step 09:媒体上传
执行者是 Python 脚本。把生成的 PNG 图片上传到 WordPress 媒体库,拿回媒体 ID。
Step 10:发布文章
执行者是 Python 脚本。整合所有输出:
调用 WordPress REST API 创建文章,默认保存为草稿。你可以在后台预览确认后再正式发布。
🏗️ 设计洞见
为什么默认保存草稿而不是直接发布?因为自动化的边界是「减少机械劳动」,不是「取代人类判断」。最终发布这一下,应该由人来点。
理解了每一步做什么,再来看数据如何在步骤间流动。
用一句话概括:
前一步的输出,是后一步的输入。环环相扣,无缝流转。
这就是「流水线」的本质——每个工位只做一件事,但连起来就是完整的产品。
config.json(Step 01)config.json → search-results.json(Step 02)search-results.json → full-articles/*.md(Step 03)full-articles/*.md → research.md(Step 04)research.md → verified.json(Step 05)research.md + verified.json → article-v1.md(Step 06)article-v1.md → seo.json(Step 07)article-v1.md + seo.json → png/*.png(Step 08)png/*.png → media-ids.json(Step 09)publish-result.json(Step 10)每个步骤的输出都是独立文件,存储在对应的目录下。这意味着:
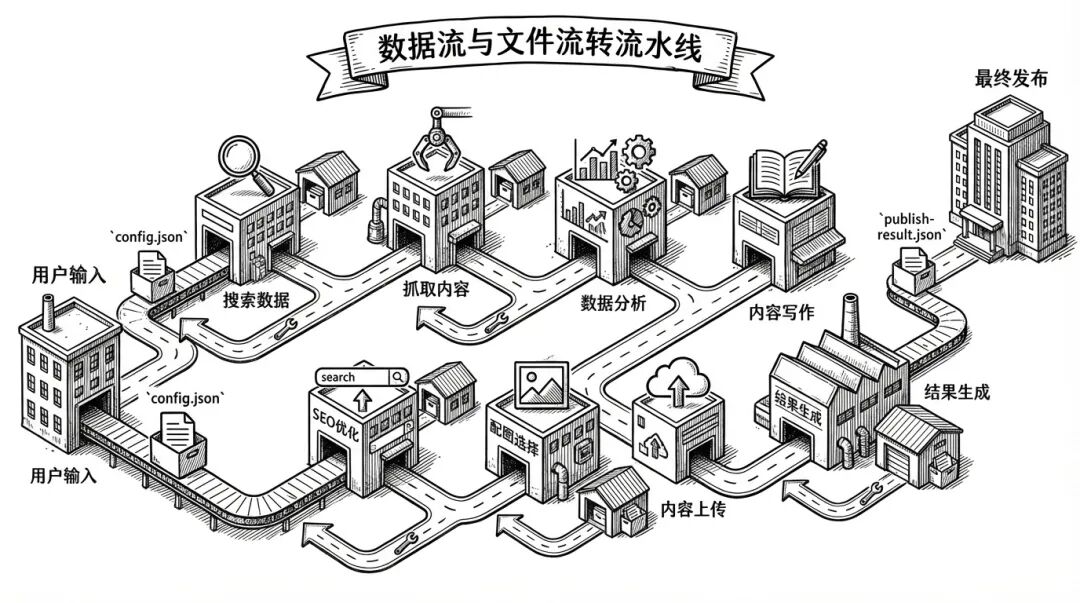
数据流与文件流转
看到这里你可能会问:这么多步骤,怎么保证不出错?
答案是多重防护机制 。
每个步骤都有明确的「验证检查点」,定义了什么叫「通过」:
config.json 存在且包含 topic/keywordspost.id 存在检查点不通过,流程就停在那一步,不会继续往下跑。
注意看每一步的「执行者」,有的是主 Agent,有的是 SubAgent,有的是脚本。
脚本不会「发挥」,只会按规则执行。Agent 有创造力,但被限定在特定边界内。
长流程最怕的是「上下文爆炸」,前面的信息太多,后面的 Agent 记不住。
这套系统的策略是阶段隔离 :
每个 SubAgent 启动时,只看到它需要的信息,不会被无关内容干扰。
🔬 底层原理
这其实是「分治思想」在 AI 工作流中的应用:把大问题拆成小问题,让每个 Agent 只解决自己那一块。全局协调交给流程编排,而不是某个「超级 Agent」。
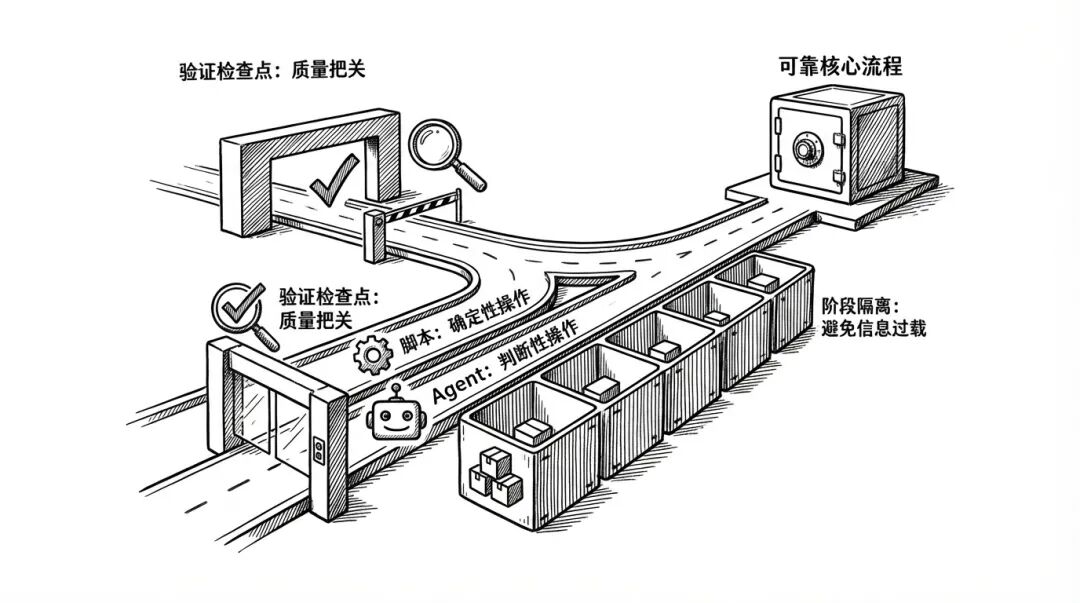
三重防护机制
技术细节之外,我想分享几个更底层的洞见。
纳瓦尔说过:「代码是无边际成本的杠杆。写一次,复用无限次。」
这套自动化系统,本质上就是一根杠杆——用一次构建的成本,撬动无限次发文的效率。
不是所有事情都应该自动化。这套系统自动化的是「机械重复」的部分:搜索、抓取、上传、发布。而「需要判断」的部分,话题选择、最终审核,仍然留给人。
好的自动化不是「取代人」。
是让人专注于人该做的事。
这是效率主义者的胜利——用系统的确定性,对抗人力的不确定性。
10 个步骤听起来很多,但被「三阶段」框架组织后就清晰了。每个阶段有独立的目标和边界,阶段内的步骤紧密相关,阶段间松耦合。
这是所有复杂系统的设计模式:分层 + 接口 。层内高内聚,层间低耦合。
你以为自动化是为了省时间?
不。是为了省注意力。
时间可以加班补,注意力用完就没了。
在 AI 工作流中,可观测性比传统软件更重要——因为 AI 的行为不确定,你必须能看到它每一步做了什么。
每一步都输出独立文件,每一步都有验证检查点。出了问题,你能看到「哪一步出了什么问题」,而不是对着一个黑盒干瞪眼。
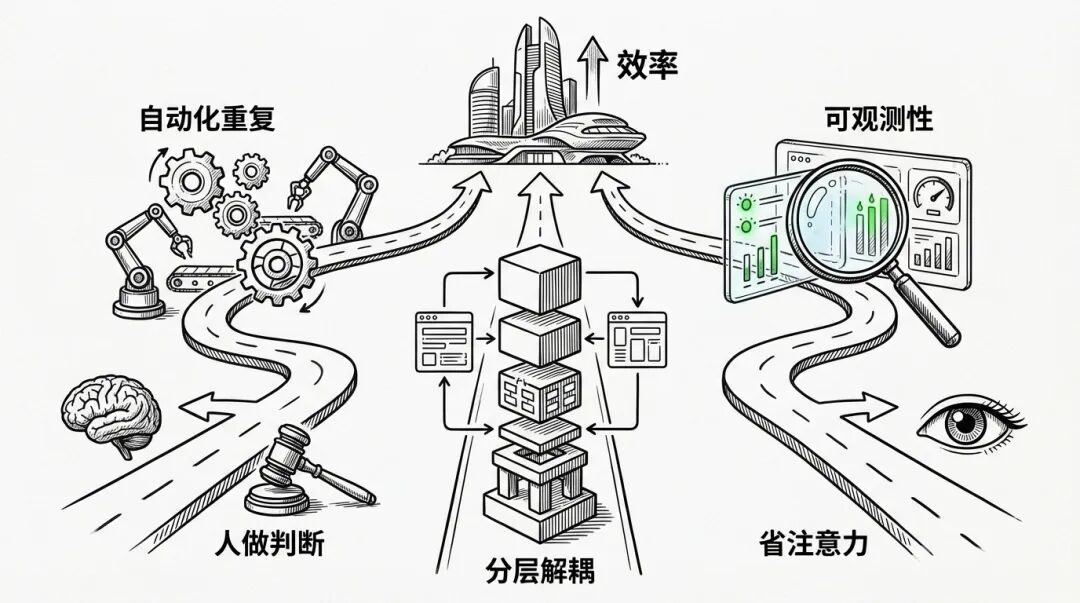
底层洞见与设计哲学
今天分享的这套系统,证明了一件事:Agent 流程编排可以实现 WordPress 的自动化运营 。
但每个步骤还可以继续深化:
今天的 Skill 是 1.0 版本,跑通了完整流程。未来的迭代,是在这个骨架上持续优化每一块肌肉。
复制这段提示词给 Claude Code,从零复刻完整系统:
「你是高级系统架构师,专精 AI Agent 工作流编排与 WordPress 自动化。
现在请为我构建一个完整的 WordPress 博客全自动发布系统。这是一个 Claude Code Skill,用户触发后自动执行从话题研究到文章发布的完整流程。
系统目标 :实现「一条命令 → WordPress 草稿」的全自动化体验。
架构设计 :
采用「三阶段十步骤」渐进式披露架构:
目录结构 :
关键实现要点 :
约束条件 :
请按照上述架构完整实现这个 Skill,包括所有 workflow 文档、脚本代码和配置文件。」
即刻行动 :复制上面的提示词,打开 Claude Code,30 分钟内你就能看到第一篇自动生成的文章。
📚 更多 Agent 工作流内容:Agent 工作流实战指南:从单个 Agent 到十人团队的完整搭建路径
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
8 大 AI Agent 全维度对比:从 GitHub Stars 到安全记录,从月度成本到真实场景——Hermes 自我进化、OpenClaw 网关编排、Claude Code 编码天花板,附决策树和双修方案。
全网极少数同时在生产跑 Cursor、Claude Code、Codex 三大工具的实战横评。六大主力工具十维评分卡、精确定价表、隐藏成本案例、场景决策矩阵、省钱策略——一篇看完不用再翻别的。

全网最深度的 Claude Code 中文教程。覆盖 6 种安装方式、60+ 命令速查、CLAUDE.md 知识架构、Hooks/Skills/MCP 实战、成本控制 5 技巧、25 个常见报错解决方案,附可复制提示词。
每周精选 AI 编程与自动化实战内容,直达你的邮箱