引言
最近,翔宇在研究Google Cloud的Gemini模型微调技术时,发现很多朋友都在问:怎么才能让AI模型更贴合自己的业务需求?基础模型虽然强大,但总感觉差点意思,怎么办?

这篇文章就是为了解决这个问题而写的。翔宇会把Google Cloud官方博客上的Gemini微调最佳实践,用最通俗易懂的方式讲给你听。
这篇文章适合谁看?
- 想要优化AI模型性能的开发者
- 对Gemini模型微调感兴趣的技术人员
- 想了解如何准备训练数据的AI从业者
- 希望提升模型准确率的项目负责人
读完这篇文章,你能收获什么?
- 学会如何选择合适的Gemini模型
- 掌握数据准备的关键技巧
- 了解超参数设置的最佳实践
- 学会评估微调后的模型效果
好,废话不多说,咱们直接开始!
第一步:建立基准线并选择模型
在开始微调之前,翔宇建议你先做一件事:测试一下基础模型的表现。
为什么要这么做呢?打个比方,这就像你想改造一辆车,得先试驾一下原车,看看哪里不满意,对吧?
如何建立基准线?
- 用现成的模型跑一遍数据:看看Gemini基础模型在你的任务上表现如何
- 记录关键指标:准确率、响应速度、错误类型等
- 找出痛点:哪些场景下模型表现不好?
选择哪个Gemini模型?
Google提供了两个主要选择:
Gemini 2.5 Pro
- 适合场景:对性能要求高,预算相对充足
- 特点:综合能力最强,处理复杂任务表现更好
Gemini 2.5 Flash
- 适合场景:需要快速响应,成本敏感型项目
- 特点:响应速度快,成本低,性价比高
翔宇的建议是:根据你的具体需求选择。如果你的应用对延迟要求高(比如实时对话机器人),选Flash;如果需要处理复杂推理任务,选Pro。
第二步:数据准备——质量比数量更重要
这一步是整个微调过程的核心,翔宇要特别强调一点:别追求数据量,追求数据质量。
什么样的数据才算好数据?
翔宇总结了三个关键要素:
1. 相关性 数据必须和你的实际应用场景紧密相关。举个例子,如果你要做客服机器人,那训练数据就应该是真实的客服对话,而不是网上随便找的聊天记录。
2. 多样性 覆盖各种可能的场景和边界情况。就像开车考试,不能只练直线,转弯、倒车、停车都得会。
3. 准确性 标注必须正确。错误的标注会把模型“带歪”,这就像请了个不靠谱的老师,越学越偏。
数据预处理的关键技巧
去重是第一要务
想象一下,如果你学英语,老师让你把同一个句子抄100遍,有用吗?没用,反而浪费时间。训练数据也是一样。
去重的几种方法:
- 精确匹配:完全相同的数据直接删除
- 模糊匹配:相似度很高的数据也要考虑去掉
- 聚类分析:把相似的数据分组,每组保留代表性样本
数据增强技巧
如果数据量确实不够怎么办?可以适当做一些数据增强:
- 改写同义表达
- 调整句子结构
- 添加合理的变体
但要注意:增强的数据也要保证质量,别为了凑数量而降低质量。
第三步:添加指令——让模型明白你的意图
这一步很多人容易忽略,但其实很重要。你需要明确告诉模型:你希望它做什么。
两种添加指令的方式
1. 系统指令(System Instructions)
这是全局性的指导,适用于所有训练样本。
比如:
你是一个专业的客服助手,需要用礼貌、简洁的语言回答用户问题。
2. 实例级指令(Instance-level Instructions)
这是针对具体样本的指导。
比如:
根据以下客户评论,判断情感是正面、负面还是中性。
翔宇的建议:两种方式结合使用效果最好。系统指令定义整体风格,实例指令处理具体任务。
第四步:超参数设置——找到最佳配置
超参数听起来很专业,其实就是一些控制训练过程的“旋钮”。翔宇把Google官方推荐的设置整理成了通俗易懂的版本。
Gemini 2.5 Pro 推荐设置
数据量少于1000条时:
- 训练轮数(Epochs):20轮
- 理解:让模型把数据“看”20遍
- 学习率倍数(Learning Rate Multiplier):10
- 理解:学习速度调快10倍
- 适配器大小(Adapter Size):4
- 理解:模型调整的“精细度”设为4
数据量大于等于1000条时:
- 训练轮数:10轮
- 理解:数据多了,看10遍就够了
- 学习率倍数:默认值或5
- 理解:数据多时不用学太快
- 适配器大小:4
Gemini 2.5 Flash 推荐设置
数据量少于1000条时:
- 训练轮数:默认值
- 学习率倍数:10
- 适配器大小:4
数据量大于等于1000条时:
- 训练轮数:默认值
- 学习率倍数:默认值
- 适配器大小:8(注意这里Flash用8,Pro用4)
如何判断训练效果?
翔宇建议重点关注两个指标:
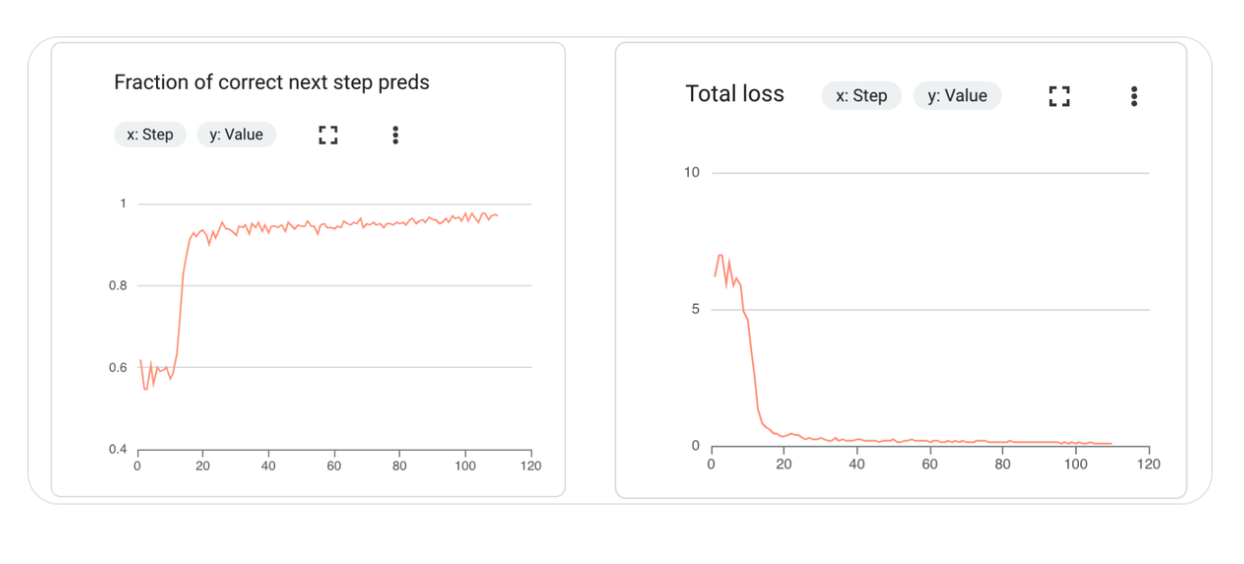
1. 总损失(Total Loss)
- 理解:模型的“错误程度”
- 规律:这个数字应该随着训练逐渐下降
- 警惕:如果突然上升或不再下降,说明有问题
2. 预测正确率(Fraction of Correct Predictions)
- 理解:模型答对的比例
- 规律:应该随着训练逐渐上升
- 警惕:如果训练集很高但验证集很低,说明过拟合了
常见问题及解决方法
问题1:性能不理想
- 可能原因:数据量太少或质量不够
- 解决方法:增加高质量数据,或调整学习率
问题2:过拟合
- 表现:训练集表现好,验证集表现差
- 解决方法:减少训练轮数,增加数据多样性
问题3:数据问题
- 表现:损失不下降或波动很大
- 解决方法:检查数据质量,去除异常样本
第五步:模型评估——全面检验效果
训练完成后,别急着上线,先好好评估一下效果。翔宇推荐三种评估方法:
1. 自动指标评估
这是最基础的评估方式,就像学生考试看分数。
常用指标:
- 准确率:答对的比例
- 召回率:找出相关内容的能力
- F1分数:准确率和召回率的平衡
2. 模型评估模型
用另一个AI模型来评估你的模型,有点像“找个专家来审核”。
优点:
- 比人工评估快
- 可以发现一些隐藏问题
3. 人工评估
这是最可靠但也最耗时的方法。
翔宇的建议:
- 抽样评估:不用全部评估,抽取代表性样本
- 关注边界情况:重点看模型容易出错的场景
- 真实场景测试:用实际业务数据测试
实战建议:翔宇的经验总结
在文章最后,翔宇想分享几条实战经验:
1. 从小数据集开始 别一上来就准备几万条数据,先用100条左右试试水,快速迭代。
2. 关注困难样本 把基础模型经常答错的案例作为训练重点,这样提升最明显。
3. 训练数据要贴近生产环境 用户实际会怎么提问,训练数据就应该怎么准备。
4. 持续监控和优化 上线后也要持续收集反馈,定期更新训练数据。
5. 做好版本管理 每次微调都保存好配置和数据,方便后续对比和回溯。
总结
Gemini模型微调并不复杂,关键是要掌握正确的方法:
- 先测试基础模型,找准优化方向
- 精心准备数据,质量远比数量重要
- 合理设置超参数,根据数据量选择配置
- 全面评估效果,确保真正满足需求
翔宇相信,只要按照这个流程走,你一定能微调出满意的模型。记住:AI微调是个迭代的过程,不要期望一次就完美,持续优化才是王道。
如果你在实践中遇到问题,欢迎在评论区留言,翔宇会尽力帮助大家!
参考资料
来源:Google Cloud官方博客
原文作者:Erwin Huizenga(AI工程与布道经理)、Bethany Wang(Google Cloud高级软件工程师)