
你有没有这种经历:花 30 分钟写完一个 Skill,然后花 3 小时让它正常跑起来?
这不是段子。我统计过自己开发 Skill 的时间分布:构思设计 20%,代码编写 20%,调试修复 60%。
问题出在哪?报错信息太模糊、排查路径太多、修完一个又冒一个。更崩溃的是,有时候根本不报错,就是输出不对,你完全不知道哪里出了问题。
这篇文章分享一个我折腾了一个多月做出来的系统:Skill Quality Loop。
读完你会获得:
- 一套结构化框架:理解「静态检测 + 动态验证」双阶段循环的设计逻辑
- 一种系统性思维:把「调试」从玄学变成工程,有输入、有输出、可追踪、可复现
- 一个可复刻的神器:文末有完整提示词,复制给 Claude Code 就能搭建你自己的质检系统
先说结论:规范先行 + Agent 自修复 = 调试效率提升 10 倍。
为什么 Skill 调试这么痛?
这个问题困扰我很久。直到我把所有踩过的坑分类整理,才发现一个规律。
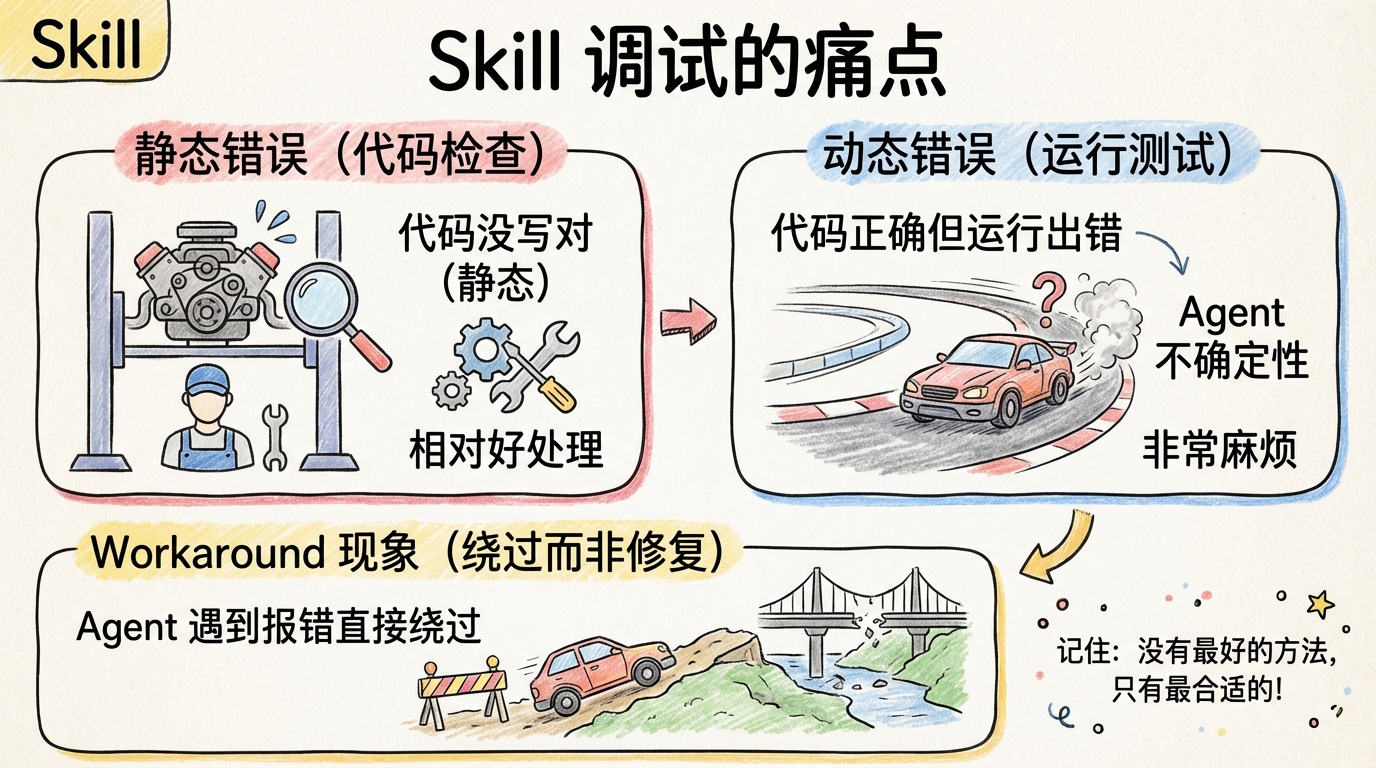
Skill 的错误可以分成两类:静态错误(代码没写对)和动态错误(运行没跑对)。
静态错误相对好处理。语法错误、文件缺失、字段漏写,IDE 或者 linter 能抓出来一部分。
但动态错误就麻烦了。你的代码语法完全正确,结构完全规范,但一跑起来就出问题。为什么?因为 Skill 是给 Agent 执行的,Agent 的行为有不确定性。
举个真实例子:我有个 Skill 负责生成 PPT。静态检查全部通过。但实际运行时,Agent 读错了配置文件路径,导致输出目录不对。这种问题你盯着代码看一万遍都发现不了,必须实际跑一遍才知道。
更要命的是 Workaround 现象:Agent 遇到脚本报错时,不是修复脚本,而是直接绕过。比如脚本该生成的文件,它用 Write 工具自己创建了一个。表面上流程走通了,实际上埋了雷。
🎯 打个比方:把 Skill 调试想象成修车。静态检测是「车停着检查」,发动机、轮胎、刹车,逐项排查。动态检测是「开上路测试」,起步、转弯、急刹,看实际表现。两种检查缺一不可,光看不跑永远发现不了路上才暴露的问题。
无规矩不成方圆
在设计 Quality Loop 之前,我走了很多弯路。
最开始我尝试让 AI「自由发挥」:给它日志,让它自己分析问题。结果?同一个问题,它每次的判断都不一样。今天说是路径问题,明天说是权限问题,后天又说是配置问题。
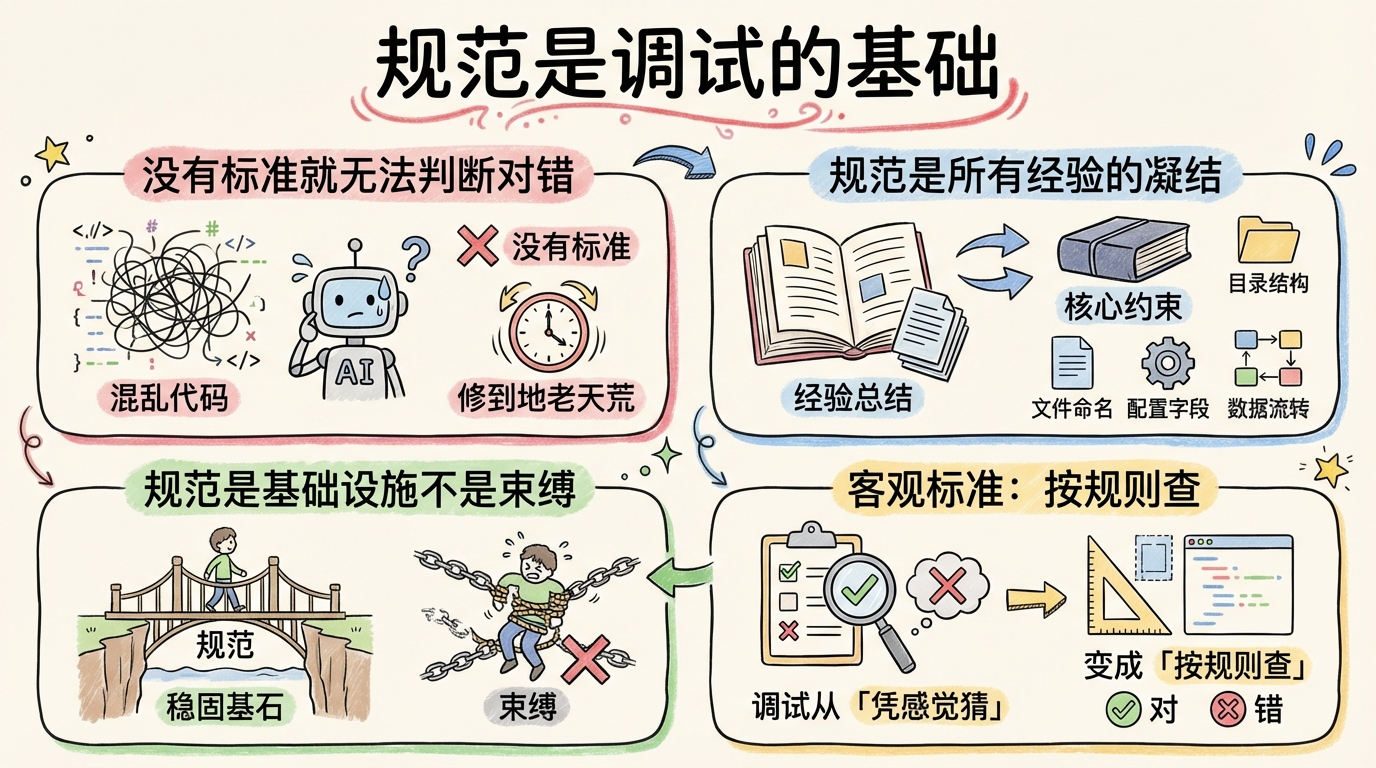
问题的根源是:没有统一的判断标准。
什么是「正确」?什么算「错误」?这些问题必须有明确的定义。否则 AI 修到地老天荒也修不好,因为它不知道什么才叫「好」。
于是我做了第一件事:建立 Skill 规范。
规范定义了核心约束:目录结构应该怎么组织、文件命名要遵循什么规则、配置字段哪些是必填的、数据流应该怎么流转。有了这份规范,「对」和「错」就有了客观标准。
Claude Code 官方文档也提到这一点:「Claude 在能验证自己工作时表现显著更好,运行测试、比较截图、验证输出。没有明确的成功标准,可能产出看起来对但实际不工作的东西。」
规范就是这个「成功标准」。它不是束缚,是解放。有了它,调试才能从「凭感觉猜」变成「按规则查」。
📝 记住这个:规范是所有 Skill 开发经验的凝结。你踩过的坑、别人踩过的坑、未来可能踩的坑,全部用规则的形式固化下来。规范越完善,调试越轻松。
双阶段循环设计
有了规范作为判断依据,下一步是设计检测流程。
我把检测分成两个阶段:静态阶段和动态阶段。
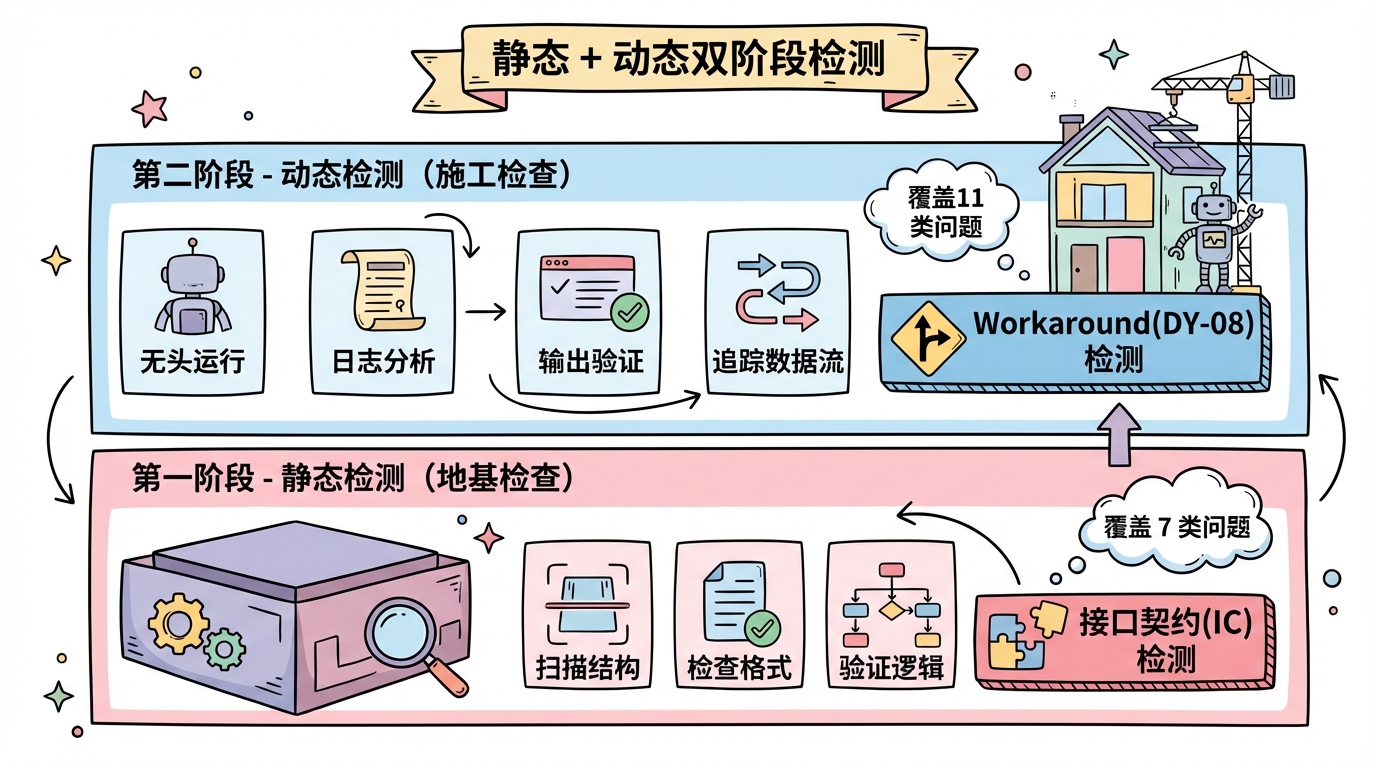
静态阶段的核心检查:
- 扫描结构:目录是否完整、必要文件是否存在
- 检查格式:命名是否规范、编号是否正确
- 验证逻辑:引用是否有效、依赖是否存在
静态检测覆盖 7 类问题:运行时错误(RT)、结构疏漏(ST)、格式不一致(FT)、逻辑矛盾(LG)、Bug缺陷(BG)、索引错误(IX)、接口契约(IC)。
其中接口契约(IC)检测是我花最多时间设计的。Skill 里经常有脚本和配置的交互,脚本期望某个字段,配置里没有;脚本输出到 A 目录,下游从 B 目录读。这种「接口不匹配」是最常见也最难发现的 bug。
动态阶段的核心检查:
- 无头运行:用 Claude Agent SDK 真实执行 Skill
- 日志分析:解析运行日志,识别异常模式
- 输出验证:检查预期文件是否生成、内容是否有效
- 数据流追踪:验证上游输出是否被下游正确消费
动态检测覆盖 11 类问题:从启动失败(DY-01)到关键步骤缺失(DY-11),涵盖了我踩过的所有坑。
特别要提Workaround 检测(DY-08)。这个检测专门抓「Agent 绕过脚本错误」的情况。比如日志里出现「脚本执行失败,我来手动创建文件」,就会被标记为 DY-08。因为这意味着脚本有问题,必须修复。
🔬 底层原理:为什么要分两阶段?因为错误有层次。静态错误是「地基问题」,动态错误是「施工问题」。地基不稳就开工,盖到一半才发现歪了,返工成本极高。先把地基检查好(静态),再检查施工质量(动态),效率最高。
四重验证让 Bug 无处可逃
检测到问题只是第一步。真正的难点是:怎么确认问题真的被修好了?
我见过太多「假修复」:
- 修完一个 bug,引入两个新 bug
- 问题消失了,但是用了 workaround
- 输出文件生成了,但内容是空的
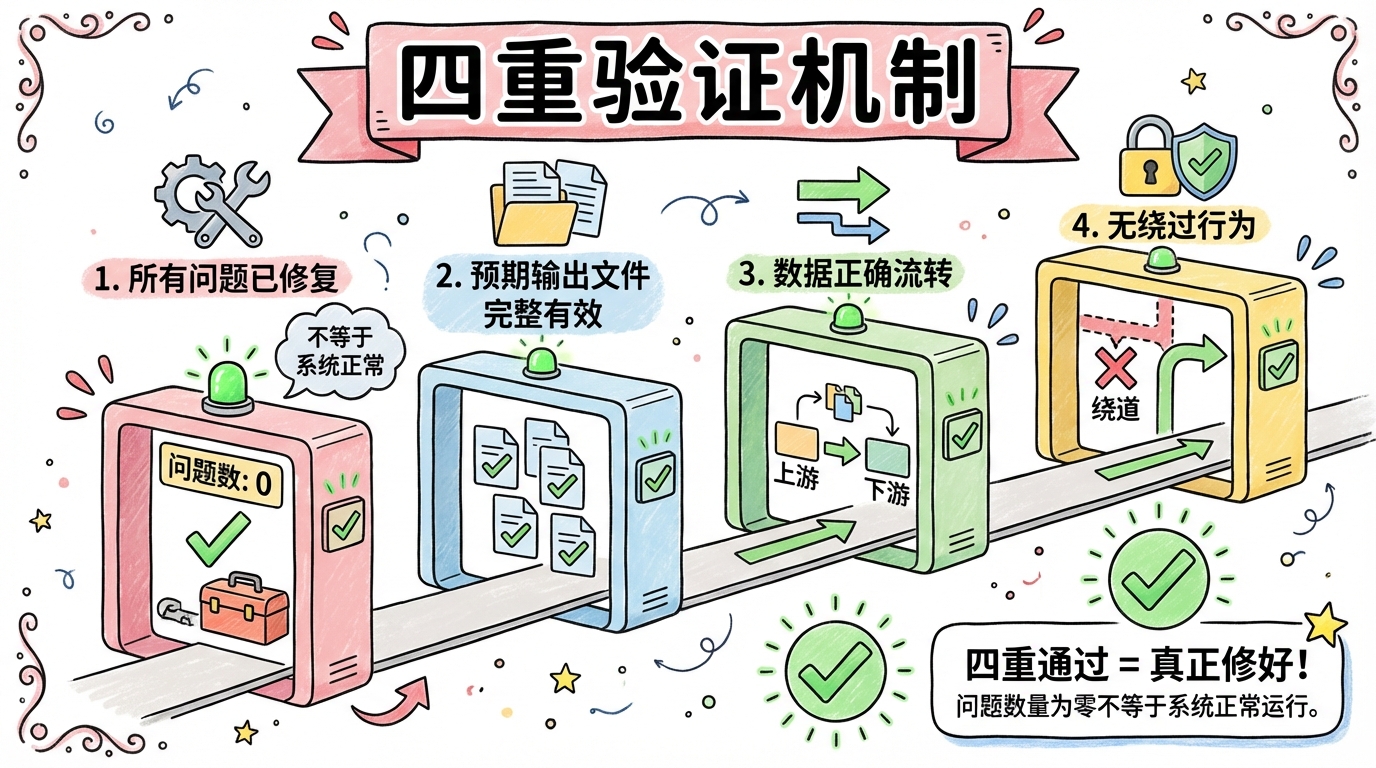
为了杜绝这些情况,我设计了四重验证机制:
- Issues 清零:所有检测到的问题都已修复
- Output 完整:预期的所有输出文件都生成了,且内容有效
- Dataflow 畅通:数据从上游正确流转到下游
- Workarounds 归零:没有任何「绕过」行为
四重验证全部通过,才算真正修好。任何一项不通过,继续循环。
这个设计来自一个惨痛教训:我曾经以为「Issues 清零」就够了。结果上线后发现输出文件虽然存在,但内容全是乱码。原因是脚本崩溃了,Agent「好心」帮我创建了空文件。从那以后我才明白:问题数量为零 ≠ 系统正常运行。
🏗️ 设计洞见:单点验证永远不够。系统有多少出口,就要有多少检查点。Quality Loop 的四重验证不是过度设计,是血泪教训的产物。
Agent 自修复
检测出问题后,谁来修?
最初我是自己手动修。看报告、定位问题、改代码、重新跑。效率极低。
后来我想:检测能自动化,修复为什么不能?
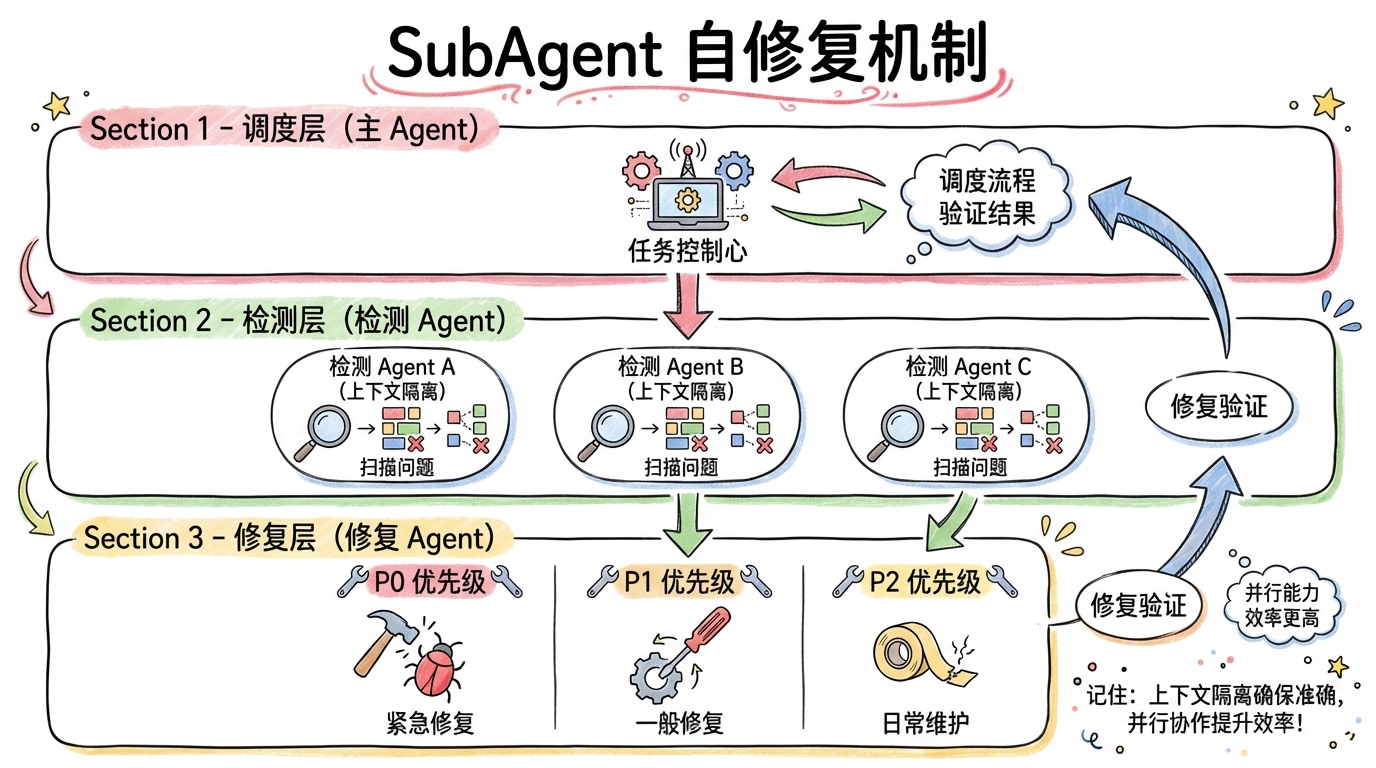
于是我引入了自修复机制:SubAgent 负责修复。
工作流是这样的:
- 主 Agent 调度整体流程
- 检测 Agent(SubAgent)扫描问题
- 修复 Agent(SubAgent)执行修复
- 主 Agent 验证结果,决定是否继续循环
为什么用 SubAgent 而不是主 Agent 直接修?两个原因。
第一是上下文隔离。每轮修复都用全新的 SubAgent,避免之前的错误信息污染后续判断。这个设计参考了微软的研究:「每个任务是原子工作单元,每次代码审查是质量门禁,问题立即捕获,防止技术债务。」
第二是并行能力。检测和修复可以分开优化。检测 Agent 专注扫描,修复 Agent 专注改代码,各司其职效率更高。
修复也有策略。不是所有问题都要修:
- P0 问题(阻塞执行):必须修
- P1 问题(影响质量):应该修
- P2 问题(建议改进):可选修
优先修 P0,再修 P1。避免在小问题上浪费算力。
🧩 结构拆解:整个系统分三层:调度层(主 Agent)、检测层(检测 SubAgent)、修复层(修复 SubAgent)。调度层决定「做什么」,检测层负责「发现问题」,修复层负责「解决问题」。层层分离,各司其职。
智能退出
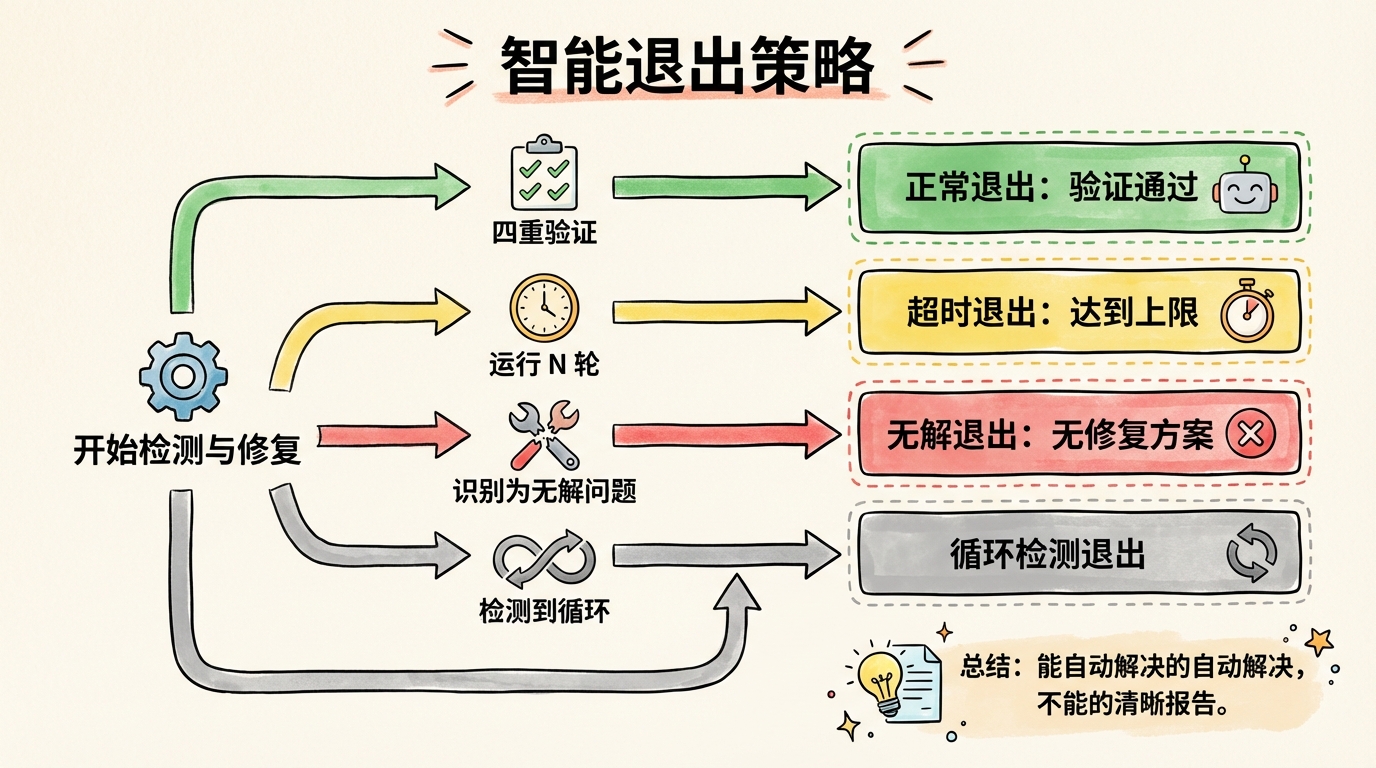
循环不能无限转下去。需要明确的退出条件。
正常退出:四重验证全部通过。问题清零、输出完整、数据流畅通、无 workaround。这是最理想的结果。
达到上限退出:跑了 N 轮还没修好。这时候输出报告,列出剩余问题,供人工判断。
无法修复退出:某些问题没有修复方案。比如依赖了一个不存在的外部 API,这种问题 Agent 修不了,只能报告。
循环检测退出:连续两轮的问题列表完全相同。说明修复陷入循环,再跑也没用,及时止损。
退出条件的设计原则是:能自动解决的自动解决,不能自动解决的清晰报告。
我日常使用的配置是「静态 0 轮 + 动态 1 轮」。为什么?因为大多数问题在动态阶段暴露。跑一轮动态测试,拿到完整日志,然后人工分析。这比盲目跑 5 轮循环效率高得多。
⚡ 三秒版:退出逻辑:修好了就停、修不好就报、陷入循环就撤。
实战效果
用 Quality Loop 检测过的 Skill 超过 20 个。分享几个典型案例。
案例 1:Twitter 自动发布 Skill
问题:脚本期望配置里有 weight 字段,但配置文件里没有。
这是典型的 IC-01(接口契约-配置字段缺失)问题。静态检测第一轮就抓出来了,自动修复加上了字段,问题解决。
如果没有 Quality Loop,这个问题会在运行时才暴露,表现为「脚本莫名其妙崩溃」,排查难度极大。
案例 2:文章翻译 Skill
问题:上游步骤输出到 drafts/,下游步骤从 output/ 读取。
这是典型的 DY-10(数据流断裂)问题。静态检测发现不了(因为两边代码都没语法错误),动态检测才抓出来,上游有输出,下游读取失败。
修复方案:统一输出路径。Quality Loop 自动执行了这个修复。
案例 3:PPT 生成 Skill
问题:脚本崩溃后,Agent 手动创建了空的 PPT 文件。
这是典型的 DY-08(Workaround 模式)+ DY-09(输出内容无效)问题。如果只检查「文件是否存在」,会漏掉这个问题。四重验证机制抓出了它,文件存在但内容无效,且存在 workaround 行为。
修复方案:修复脚本本身的崩溃问题,而不是接受 workaround。
从这个系统里我学到什么
规范是基础设施。没有规范就没有标准,没有标准就无法自动化。花时间写规范,是投资不是成本。
分层思维很重要。静态检测、动态检测、修复、验证,每一层解决一类问题。试图用一个万能方案解决所有问题,只会制造更大的混乱。
退出条件要明确。无限循环是系统设计的大忌。什么时候停、为什么停、停了之后怎么办,都要想清楚。
Agent 能力有边界。不是所有问题都能自动修复。清晰地划分「能自动解决」和「需要人工介入」的边界,比盲目追求全自动更务实。
🚀 一键复刻
复制这段提示词给 Claude Code,从零构建完整的 Skill 质检系统:
「你是高级系统架构师,任务是从零构建一个 Skill 质量循环检测系统(Quality Loop)。
系统目标:自动检测并修复 Claude Code Skill 中的问题,通过静态+动态双阶段循环验证,直到符合规范或达到轮数上限。
核心架构(三层):
- 调度层(主 Agent):控制整体流程,管理状态,决定循环/退出
- 检测层(SubAgent):静态检测(7 类问题)+ 动态检测(11 类问题)
- 修复层(SubAgent):按优先级修复问题,每轮全新上下文
静态检测维度(7 类):
- RT: 运行时错误(语法、导入、权限)
- ST: 结构疏漏(缺失文件/字段/目录)
- FT: 格式不一致(命名不规范、编号错误)
- LG: 逻辑矛盾(引用不存在、循环依赖)
- BG: Bug/缺陷(路径写死、变量未定义)
- IX: 索引错误(链接失效、索引过时)
- IC: 接口契约(脚本与配置不匹配)
动态检测维度(11 类):
- DY-01: 启动失败
- DY-02: 文件未找到
- DY-03: 权限错误
- DY-04: API/SDK 错误
- DY-05: 流程中断
- DY-06: 输出缺失
- DY-07: 逻辑错误
- DY-08: Workaround 模式(Agent 绕过脚本失败)
- DY-09: 输出内容无效
- DY-10: 数据流断裂
- DY-11: 关键步骤缺失
四重验证(全部通过才算成功):
- Issues == 0(所有问题已修复)
- Output Complete(预期输出全部生成且有效)
- Dataflow OK(数据正确流转)
- No Workarounds(无绕过行为)
退出条件:
- 四重验证通过 → 成功退出
- 达到最大轮数 → 输出报告退出
- 问题无法修复 → 报告退出
- 连续两轮相同 → 循环检测退出
实现要求:
- 规范驱动:从外部规范目录读取检查标准
- 进度持久化:支持断点恢复
- SubAgent 隔离:每轮检测/修复用全新 Agent
- 日志完整:所有步骤可追溯
- 报告清晰:最终输出包含问题清单、修复记录、剩余遗留
请按这个架构,生成完整的 Skill 目录结构和核心文件(SKILL.md、workflow 步骤文件、检测 prompt、修复 prompt、报告模板)。」
如何让 Skill 自己修 Bug?
你有没有这种经历:花 30 分钟写完一个 Skill,然后花 3 小时让它正常跑起来?
这不是段子。我统计过自己开发 Skill 的时间分布:构思设计 20%,代码编写 20%,调试修复 60%。
问题出在哪?报错信息太模糊、排查路径太多、修完一个又冒一个。更崩溃的是,有时候根本不报错,就是输出不对,你完全不知道哪里出了问题。
这篇文章分享一个我折腾了一个多月做出来的系统:Skill Quality Loop。
读完你会获得:
- 一套结构化框架:理解「静态检测 + 动态验证」双阶段循环的设计逻辑
- 一种系统性思维:把「调试」从玄学变成工程,有输入、有输出、可追踪、可复现
- 一个可复刻的神器:文末有完整提示词,复制给 Claude Code 就能搭建你自己的质检系统
先说结论:规范先行 + Agent 自修复 = 调试效率提升 10 倍。
为什么 Skill 调试这么痛?
这个问题困扰我很久。直到我把所有踩过的坑分类整理,才发现一个规律。
Skill 的错误可以分成两类:静态错误(代码没写对)和动态错误(运行没跑对)。
静态错误相对好处理。语法错误、文件缺失、字段漏写,IDE 或者 linter 能抓出来一部分。
但动态错误就麻烦了。你的代码语法完全正确,结构完全规范,但一跑起来就出问题。为什么?因为 Skill 是给 Agent 执行的,Agent 的行为有不确定性。
举个真实例子:我有个 Skill 负责生成 PPT。静态检查全部通过。但实际运行时,Agent 读错了配置文件路径,导致输出目录不对。这种问题你盯着代码看一万遍都发现不了,必须实际跑一遍才知道。
更要命的是 Workaround 现象:Agent 遇到脚本报错时,不是修复脚本,而是直接绕过。比如脚本该生成的文件,它用 Write 工具自己创建了一个。表面上流程走通了,实际上埋了雷。
🎯 打个比方:把 Skill 调试想象成修车。静态检测是「车停着检查」,发动机、轮胎、刹车,逐项排查。动态检测是「开上路测试」,起步、转弯、急刹,看实际表现。两种检查缺一不可,光看不跑永远发现不了路上才暴露的问题。
无规矩不成方圆
在设计 Quality Loop 之前,我走了很多弯路。
最开始我尝试让 AI「自由发挥」:给它日志,让它自己分析问题。结果?同一个问题,它每次的判断都不一样。今天说是路径问题,明天说是权限问题,后天又说是配置问题。
问题的根源是:没有统一的判断标准。
什么是「正确」?什么算「错误」?这些问题必须有明确的定义。否则 AI 修到地老天荒也修不好,因为它不知道什么才叫「好」。
于是我做了第一件事:建立 Skill 规范。
规范定义了核心约束:目录结构应该怎么组织、文件命名要遵循什么规则、配置字段哪些是必填的、数据流应该怎么流转。有了这份规范,「对」和「错」就有了客观标准。
Claude Code 官方文档也提到这一点:「Claude 在能验证自己工作时表现显著更好,运行测试、比较截图、验证输出。没有明确的成功标准,可能产出看起来对但实际不工作的东西。」
规范就是这个「成功标准」。它不是束缚,是解放。有了它,调试才能从「凭感觉猜」变成「按规则查」。
📝 记住这个:规范是所有 Skill 开发经验的凝结。你踩过的坑、别人踩过的坑、未来可能踩的坑,全部用规则的形式固化下来。规范越完善,调试越轻松。
双阶段循环设计
有了规范作为判断依据,下一步是设计检测流程。
我把检测分成两个阶段:静态阶段和动态阶段。
静态阶段的核心检查:
- 扫描结构:目录是否完整、必要文件是否存在
- 检查格式:命名是否规范、编号是否正确
- 验证逻辑:引用是否有效、依赖是否存在
静态检测覆盖 7 类问题:运行时错误(RT)、结构疏漏(ST)、格式不一致(FT)、逻辑矛盾(LG)、Bug缺陷(BG)、索引错误(IX)、接口契约(IC)。
其中接口契约(IC)检测是我花最多时间设计的。Skill 里经常有脚本和配置的交互,脚本期望某个字段,配置里没有;脚本输出到 A 目录,下游从 B 目录读。这种「接口不匹配」是最常见也最难发现的 bug。
动态阶段的核心检查:
- 无头运行:用 Claude Agent SDK 真实执行 Skill
- 日志分析:解析运行日志,识别异常模式
- 输出验证:检查预期文件是否生成、内容是否有效
- 数据流追踪:验证上游输出是否被下游正确消费
动态检测覆盖 11 类问题:从启动失败(DY-01)到关键步骤缺失(DY-11),涵盖了我踩过的所有坑。
特别要提Workaround 检测(DY-08)。这个检测专门抓「Agent 绕过脚本错误」的情况。比如日志里出现「脚本执行失败,我来手动创建文件」,就会被标记为 DY-08。因为这意味着脚本有问题,必须修复。
🔬 底层原理:为什么要分两阶段?因为错误有层次。静态错误是「地基问题」,动态错误是「施工问题」。地基不稳就开工,盖到一半才发现歪了,返工成本极高。先把地基检查好(静态),再检查施工质量(动态),效率最高。
四重验证让 Bug 无处可逃
检测到问题只是第一步。真正的难点是:怎么确认问题真的被修好了?
我见过太多「假修复」:
- 修完一个 bug,引入两个新 bug
- 问题消失了,但是用了 workaround
- 输出文件生成了,但内容是空的
为了杜绝这些情况,我设计了四重验证机制:
- Issues 清零:所有检测到的问题都已修复
- Output 完整:预期的所有输出文件都生成了,且内容有效
- Dataflow 畅通:数据从上游正确流转到下游
- Workarounds 归零:没有任何「绕过」行为
四重验证全部通过,才算真正修好。任何一项不通过,继续循环。
这个设计来自一个惨痛教训:我曾经以为「Issues 清零」就够了。结果上线后发现输出文件虽然存在,但内容全是乱码。原因是脚本崩溃了,Agent「好心」帮我创建了空文件。从那以后我才明白:问题数量为零 ≠ 系统正常运行。
🏗️ 设计洞见:单点验证永远不够。系统有多少出口,就要有多少检查点。Quality Loop 的四重验证不是过度设计,是血泪教训的产物。
Agent 自修复
检测出问题后,谁来修?
最初我是自己手动修。看报告、定位问题、改代码、重新跑。效率极低。
后来我想:检测能自动化,修复为什么不能?
于是我引入了自修复机制:SubAgent 负责修复。
工作流是这样的:
- 主 Agent 调度整体流程
- 检测 Agent(SubAgent)扫描问题
- 修复 Agent(SubAgent)执行修复
- 主 Agent 验证结果,决定是否继续循环
为什么用 SubAgent 而不是主 Agent 直接修?两个原因。
第一是上下文隔离。每轮修复都用全新的 SubAgent,避免之前的错误信息污染后续判断。这个设计参考了微软的研究:「每个任务是原子工作单元,每次代码审查是质量门禁,问题立即捕获,防止技术债务。」
第二是并行能力。检测和修复可以分开优化。检测 Agent 专注扫描,修复 Agent 专注改代码,各司其职效率更高。
修复也有策略。不是所有问题都要修:
- P0 问题(阻塞执行):必须修
- P1 问题(影响质量):应该修
- P2 问题(建议改进):可选修
优先修 P0,再修 P1。避免在小问题上浪费算力。
🧩 结构拆解:整个系统分三层:调度层(主 Agent)、检测层(检测 SubAgent)、修复层(修复 SubAgent)。调度层决定「做什么」,检测层负责「发现问题」,修复层负责「解决问题」。层层分离,各司其职。
智能退出
循环不能无限转下去。需要明确的退出条件。
正常退出:四重验证全部通过。问题清零、输出完整、数据流畅通、无 workaround。这是最理想的结果。
达到上限退出:跑了 N 轮还没修好。这时候输出报告,列出剩余问题,供人工判断。
无法修复退出:某些问题没有修复方案。比如依赖了一个不存在的外部 API,这种问题 Agent 修不了,只能报告。
循环检测退出:连续两轮的问题列表完全相同。说明修复陷入循环,再跑也没用,及时止损。
退出条件的设计原则是:能自动解决的自动解决,不能自动解决的清晰报告。
我日常使用的配置是「静态 0 轮 + 动态 1 轮」。为什么?因为大多数问题在动态阶段暴露。跑一轮动态测试,拿到完整日志,然后人工分析。这比盲目跑 5 轮循环效率高得多。
实战效果
用 Quality Loop 检测过的 Skill 超过 20 个。分享几个典型案例。
案例 1:Twitter 自动发布 Skill
问题:脚本期望配置里有 weight 字段,但配置文件里没有。
这是典型的 IC-01(接口契约-配置字段缺失)问题。静态检测第一轮就抓出来了,自动修复加上了字段,问题解决。
如果没有 Quality Loop,这个问题会在运行时才暴露,表现为「脚本莫名其妙崩溃」,排查难度极大。
案例 2:文章翻译 Skill
问题:上游步骤输出到 drafts/,下游步骤从 output/ 读取。
这是典型的 DY-10(数据流断裂)问题。静态检测发现不了(因为两边代码都没语法错误),动态检测才抓出来,上游有输出,下游读取失败。
修复方案:统一输出路径。Quality Loop 自动执行了这个修复。
案例 3:PPT 生成 Skill
问题:脚本崩溃后,Agent 手动创建了空的 PPT 文件。
这是典型的 DY-08(Workaround 模式)+ DY-09(输出内容无效)问题。如果只检查「文件是否存在」,会漏掉这个问题。四重验证机制抓出了它,文件存在但内容无效,且存在 workaround 行为。
修复方案:修复脚本本身的崩溃问题,而不是接受 workaround。
从这个系统里我学到什么
规范是基础设施。没有规范就没有标准,没有标准就无法自动化。花时间写规范,是投资不是成本。
分层思维很重要。静态检测、动态检测、修复、验证,每一层解决一类问题。试图用一个万能方案解决所有问题,只会制造更大的混乱。
退出条件要明确。无限循环是系统设计的大忌。什么时候停、为什么停、停了之后怎么办,都要想清楚。
Agent 能力有边界。不是所有问题都能自动修复。清晰地划分「能自动解决」和「需要人工介入」的边界,比盲目追求全自动更务实。
🚀 一键复刻
复制这段提示词给 Claude Code,从零构建完整的 Skill 质检系统:
「你是高级系统架构师,任务是从零构建一个 Skill 质量循环检测系统(Quality Loop)。
系统目标:自动检测并修复 Claude Code Skill 中的问题,通过静态+动态双阶段循环验证,直到符合规范或达到轮数上限。
核心架构(三层):
- 调度层(主 Agent):控制整体流程,管理状态,决定循环/退出
- 检测层(SubAgent):静态检测(7 类问题)+ 动态检测(11 类问题)
- 修复层(SubAgent):按优先级修复问题,每轮全新上下文
静态检测维度(7 类):
- RT: 运行时错误(语法、导入、权限)
- ST: 结构疏漏(缺失文件/字段/目录)
- FT: 格式不一致(命名不规范、编号错误)
- LG: 逻辑矛盾(引用不存在、循环依赖)
- BG: Bug/缺陷(路径写死、变量未定义)
- IX: 索引错误(链接失效、索引过时)
- IC: 接口契约(脚本与配置不匹配)
动态检测维度(11 类):
- DY-01: 启动失败
- DY-02: 文件未找到
- DY-03: 权限错误
- DY-04: API/SDK 错误
- DY-05: 流程中断
- DY-06: 输出缺失
- DY-07: 逻辑错误
- DY-08: Workaround 模式(Agent 绕过脚本失败)
- DY-09: 输出内容无效
- DY-10: 数据流断裂
- DY-11: 关键步骤缺失
四重验证(全部通过才算成功):
- Issues == 0(所有问题已修复)
- Output Complete(预期输出全部生成且有效)
- Dataflow OK(数据正确流转)
- No Workarounds(无绕过行为)
退出条件:
- 四重验证通过 → 成功退出
- 达到最大轮数 → 输出报告退出
- 问题无法修复 → 报告退出
- 连续两轮相同 → 循环检测退出
实现要求:
- 规范驱动:从外部规范目录读取检查标准
- 进度持久化:支持断点恢复
- SubAgent 隔离:每轮检测/修复用全新 Agent
- 日志完整:所有步骤可追溯
- 报告清晰:最终输出包含问题清单、修复记录、剩余遗留
请按这个架构,生成完整的 Skill 目录结构和核心文件(SKILL.md、workflow 步骤文件、检测 prompt、修复 prompt、报告模板)。」







