Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
拆解 Karpathy 22 万星四原则、Anthropic 官方案例、Dan Abramov 的真实 CLAUDE.md。给出前端开发、后端开发、独立开发者、写作者、数据分析师、学生初学者 6 套完整可复制模板,附官方包含排除清单和反模式检查表。

Claude Code 装好了,打开项目根目录,看到一个 CLAUDE.md。点进去——空的。或者更糟,是 /init 自动生成的一堆"请在此描述你的项目架构"。
问题从来不是该不该写这个文件,而是往里面写什么才真的管用。
我系统梳理了 GitHub 上各类项目的 CLAUDE.md——从 Karpathy 那个 22 万星的四原则,到 Anthropic 官方团队自己写的项目配置,到 React 核心开发者 Dan Abramov 对提交信息的强约束。看完之后有一个很清楚的判断:大多数人的 CLAUDE.md 要么规则过多导致 Claude 选择性忽略,要么写了大量 Claude 读代码就能推断出来的冗余信息。
这篇文章做两件事。先拆解这些真实案例里到底写了什么、为什么有效。然后给出 6 套完整的 CLAUDE.md——前端、后端、独立开发者、写作者、数据分析师、初学者——你找到自己的场景,整段复制过去,改几个名字就能用。
要点速览
Claude Code 每次打开都是一张白纸。上次聊到一半的技术方案、你花了一小时纠正的代码风格、项目里那些只有你知道的坑——全部归零。
CLAUDE.md 是唯一一个每次会话都会自动加载的文件。你写的每一条规则,在你不说话的时候也在替你工作。
HumanLayer 创始人 Kyle 有一个很形象的说法——CLAUDE.md 里的一行坏指令,像多米诺骨牌一样往下推:
一行写错了
→ 后面的调研全跟着偏
→ 基于错误调研做的方案也偏
→ 写出来的代码就更偏了
反过来也成立。一行写对了,每次会话、每个任务里都在帮你省时间。
💡 通俗讲:你可以把 CLAUDE.md 想成给新来同事写的入职须知。写得好,他上手快、犯错少。写得太长或太模糊,他干脆不看,效果还不如没写。
动手之前,有几件事值得搞清楚。以下来自 Anthropic 官方文档。
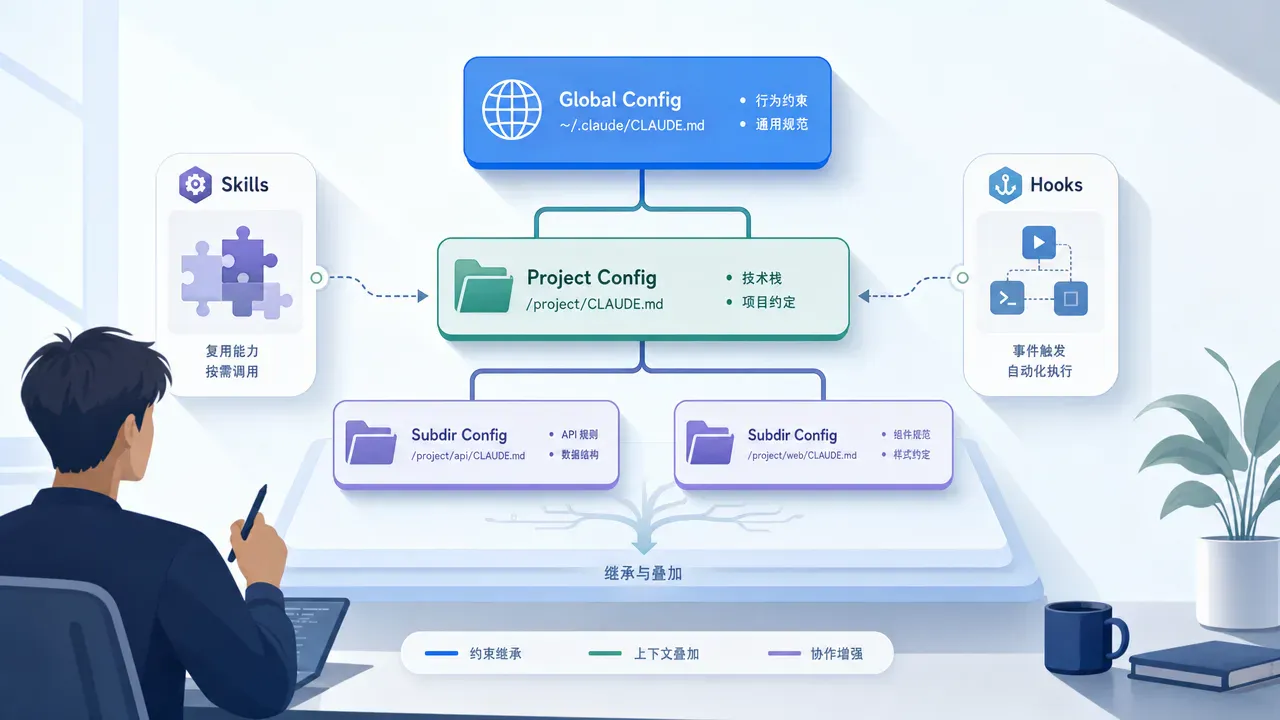
很多人以为 CLAUDE.md 就是项目根目录那一个文件。其实它是一个分层体系,Claude Code 启动时按顺序加载四层:
| 层级 | 位置 | 谁用 |
|---|---|---|
| 托管策略 | /Library/Application Support/ClaudeCode/CLAUDE.md(macOS) |
整个组织 |
| 用户指令 | ~/.claude/CLAUDE.md |
你自己,跨所有项目 |
| 项目指令 | ./CLAUDE.md 或 ./.claude/CLAUDE.md |
团队共享,签入 Git |
| 本地指令 | ./CLAUDE.local.md |
你自己,仅当前项目,不签入 Git |
四层的内容是叠加的,不是后面覆盖前面。子目录里的 CLAUDE.md 更聪明一些——只在 Claude 读到那个目录的文件时才会加载进来。
这是很多人不知道的:CLAUDE.md 并不是一道硬性命令,而是作为"用户消息"注入到对话里的。注入的时候,Claude Code 还会附带一句系统提醒,大意是:
"这些上下文不一定和你当前的任务相关,只在确实相关时才参考。"
换句话说,Claude 会自己判断哪些指令跟当前任务有关。文件越长、无关内容越多,有用的规则被忽略的概率就越高。
⚠️ 常见踩坑:你在 CLAUDE.md 里写了一整套数据库设计规范,结果 Claude 改前端代码的时候完全不看。这不是 bug——Claude 判断那些规则跟当前任务无关,就跳过了。解决办法:只和特定目录相关的规则,放到
.claude/rules/下面,用paths:字段限定生效范围。
Anthropic 的最佳实践文档列了一份很实用的清单:
该写的:
pnpm test:e2e --filter=@app/web)不该写的:
tsconfig.json,不用再写"本项目用 TypeScript"🔍 深入一步:如果某条规则特别重要,可以在前面加
IMPORTANT或YOU MUST来加重语气。但别滥用——每条都加 IMPORTANT,等于没有 IMPORTANT。
原则讲完了,下面直接看原文。以下五份 CLAUDE.md 全部来自公开仓库,附完整内容和逐段分析。
Andrej Karpathy——前特斯拉 AI 总监、OpenAI 联合创始人。他的 CLAUDE.md 在 GitHub 上拿了超过 22 万个星,是目前传播最广的单个 CLAUDE.md 文件。没有任何项目信息,通篇只做一件事:约束 AI 的行为模式。
以下是根据原文提炼的生成提示词,涵盖了四条原则的全部要点:
提示词:生成 Karpathy 四原则风格的全局 CLAUDE.md
请帮我生成一份全局 ~/.claude/CLAUDE.md,用于约束 AI 编程助手的行为模式(不包含任何项目信息)。要求覆盖以下四条核心原则:
结尾加三个检验信号:diff 多余改动变少、过度设计返工减少、澄清性提问出现在动手之前。
取舍说明写在开头:这些准则偏向谨慎而非速度,简单任务可自行判断。
整体控制在 65 行以内,适合放在全局 ~/.claude/CLAUDE.md,让所有项目自动生效。
🔍 深入一步:这四条原则适合放在全局的
~/.claude/CLAUDE.md里,让所有项目自动生效。它和项目级 CLAUDE.md 是互补关系——全局管思维习惯,项目级管具体上下文。
Anthropic 给 claude-code-action 写的 CLAUDE.md,是官方团队自用的真实配置。以下提示词包含了原文的全部关键信息:
提示词:生成 GitHub Action 类项目的 CLAUDE.md
请帮我为一个 GitHub Action 项目生成 CLAUDE.md。项目信息如下:
bun test(测试)、bun run typecheck(类型检查)、bun run format(格式化)、bun run format:check(格式检查)src/entrypoints/run.ts 统筹一切(认证→权限→触发检查→分支和评论创建→安装 CLI→执行→清理)。base-action/ 独立发布为 npm 包,从 INPUT_ 前缀环境变量读取配置控制在 55 行左右,重点突出"会坑你的事"段落。
这份 CLAUDE.md 最值得关注的是 "会坑你的事" 段落——六个踩坑点全部来自真实开发经验,不是预想出来的抽象规则。
React 核心开发者 Dan Abramov 给个人博客 overreacted.io 写的 CLAUDE.md,以下提示词覆盖了原文的全部结构要素:
提示词:生成静态博客项目的 CLAUDE.md(Dan Abramov 风格)
请帮我为一个基于 Next.js App Router 的静态博客项目生成 CLAUDE.md。项目信息如下:
npm run dev(开发服务器)、npm run build(生产构建)、npm start(生产服务器)、npm run lint(代码检查)、npm run postinstall(依赖变更后应用补丁)output: "export" 导出为静态站点/public/[slug]/index.md,frontmatter 含 title/date/spoiler/youtube。每个文章目录可含 components.js(文章专属 React 组件)和资源文件app/posts.js 读文章目录 → gray-matter 解析 frontmatter → 按日期排序 → app/[slug]/page.js 用 next-mdx-remote-client 渲染app/[slug]/mdx.js);文章专属组件从 components.js 导入;代码高亮用 Shiki(主题 Overnight Slumber);支持标题自动链接、GFM、智能引号/(首页)、/[slug]/(文章页)、/atom.xml 和 /rss.xml(订阅源)控制在 52 行左右,列出关键文件路径。
这份 CLAUDE.md 的独特之处在于对提交信息的强约束——不只管代码怎么写,还管 Claude 怎么表达。正反示例的对比非常具体,直接到文件名级别。
Vercel 官方给 next-devtools-mcp 写的 CLAUDE.md 是大公司工程规范的代表。由于篇幅较长(118 行),这里展示最核心的段落——项目概述、架构和常见开发模式(完整文件见 GitHub 仓库):
提示词:生成 MCP 服务器项目的 CLAUDE.md(Vercel 风格)
请帮我为一个 MCP 服务器项目生成 CLAUDE.md。项目信息如下:
pnpm install、pnpm build(测试前必须先构建)、pnpm dev、pnpm build && pnpm test、pnpm typechecksrc/index.ts,使用 stdio 传输,手动注册三类组件——工具(src/tools/,可调用的自动化函数)、提示词(src/prompts/,预配置提示词)、资源(src/resources/,知识库文章和文档)src/tools/ 创建文件(导出 inputSchema/metadata/handler)→ 在 src/index.ts 的 tools 数组注册 → 构建并测试src/resources/ 创建 Markdown 和处理器文件 → 注册 → 构建脚本自动复制 .md 到 dist/resources/src/prompts/ 创建文件 → 注册 → 构建并测试控制在 60 行左右,核心做法是把最常执行的操作固化成标准步骤。
这份 CLAUDE.md 的核心做法是把最常执行的操作固化成标准步骤。新增工具、新增资源、新增提示词——每类操作都有确定的步骤,Claude 不需要自己推断该改哪些文件。
Karpathy 自己的项目 llm-council 有一份详尽的项目级 CLAUDE.md,和四原则完全是两种写法。以下提示词涵盖了原文的完整架构和设计决策:
提示词:生成多模型协商系统项目的 CLAUDE.md(Karpathy llm-council 风格)
请帮我为一个三阶段多模型协商系统生成项目级 CLAUDE.md。项目信息如下:
backend/,Python + FastAPI):config.py:COUNCIL_MODELS 列表 + CHAIRMAN_MODEL + .env 读 API Key + 端口 8001(不是 8000)openrouter.py:query_model()(单模型异步查询)、query_models_parallel()(asyncio.gather 并行)、优雅降级(单模型失败返回 None 继续处理)council.py(核心):stage1_collect_responses()(并行查询)→ stage2_collect_rankings()(匿名化为 Response A/B/C → 创建 label_to_model 映射 → 严格格式评估排名 → 返回元组)→ stage3_synthesize_final()(主席模型综合);含 parse_ranking_from_text() 和 calculate_aggregate_rankings()storage.py:基于 JSON 的对话存储(data/conversations/),元数据不持久化只通过 API 返回main.py:FastAPI + CORS(localhost:5173 和 :3000),POST 端点额外返回元数据frontend/src/,React):App.jsx:管理对话列表和元数据存储(元数据只在界面状态中,不持久化)ChatInterface.jsx:多行文本域,Enter 发送,Shift+Enter 换行Stage1/2/3.jsx:标签页视图(Stage2 关键:匿名→模型名还原在客户端完成,附聚合排名).markdown-content 类,所有 ReactMarkdown 组件必须包裹在此类中from .config import ...),以 python -m backend.main 运行;改端口需同时更新 backend/main.py 和 frontend/src/api.js;模型在 config.py 硬编码,默认主席模型 Geminipython -m backend.main 运行;前端地址必须在 CORS 允许来源中;模型不遵循格式时回退正则提取;元数据是临时的不持久化控制在 130 行左右,按后端文件逐个说明关键函数,突出架构决策和常见陷阱。
这份 CLAUDE.md 和四原则形成了清晰的分工——四原则管思维方式(放全局),llm-council 的 CLAUDE.md 管项目的具体面貌(放项目级)。两种 Karpathy 都在用。
| 维度 | 行为约束派 | 项目上下文派 |
|---|---|---|
| 代表 | Karpathy 四原则 | Anthropic / Vercel / Dan Abramov |
| 放在哪 | ~/.claude/CLAUDE.md(全局) |
./CLAUDE.md(项目级) |
| 写什么 | 思考习惯、简洁原则、改动纪律 | 架构、命令、踩坑点、约定 |
| 多长 | 30-65 行 | 55-130 行 |
两种都有各自的价值,实践中建议两种结合使用。

前面拆解的五个案例以英文项目为主。中文开发者的 CLAUDE.md 写得怎么样?他们在实际项目里放了什么内容?以下是在 GitHub、X 和中文技术社区中检索到的最有参考价值的几份。
安正超是 EasyWeChat 的作者,PHP/Laravel 领域的知名开发者。他公开了一份纯中文的 CLAUDE.md,结构清晰,六个板块各解决一类问题。以下提示词包含了原文的全部规则和流程:
提示词:生成安全约束型 CLAUDE.md(安正超风格)
请帮我生成一份以安全约束和工作理念为核心的 CLAUDE.md。要求包含以下六个板块:
git reset/revert/rebase/restore 等回滚命令,只允许 git log/status/diff 等安全操作,禁止删除或修改 .git 目录,任何 git 操作前必须得到用户许可rm -rf,禁止删除目录,删除文件前必须告知用户并得到许可沟通语言:使用与用户相同的语言。控制在 70 行左右。
这份 CLAUDE.md 最值得注意的一点:每一条规则都对应一个具体的、已经发生过的问题。没有"本项目用 PHP"这类冗余声明,没有"请写高质量代码"这类不可验证的泛指令。"禁止删代码绕过编译错误"——这条规则的存在本身就说明 Claude 真的做过这件事。
claude-scholar 是一个 4200 星的学术研究助手项目,提供了中英双语对照的 CLAUDE.md。以下提示词覆盖了原文的全部板块(身份、沟通、写作纪律、计划、路由和交付格式):
提示词:生成学术研究助手项目的 CLAUDE.md(claude-scholar 风格)
请帮我为一个学术研究助手项目生成 CLAUDE.md。要求包含以下板块:
~/.claude/skills/expression-skill/SKILL.md 作为默认表达层。回答非简单请求前,用它约束方式:结论先行、以用户目标为中心、给出具体证据和路径、尽早说明风险和不确定性、对长任务给可见 roadmarks、准确说明改了什么没改什么、最后给最小有用下一步task_plan.md 记录 phases/status/decisions/blockers,notes.md 记录 findings/evidence);只在新证据改变任务时修改计划;范围大时用 P0/P1/P2 优先级排序控制在 90 行左右,核心特色是明确的身份边界、写作纪律的模糊词黑名单和固定交付格式。
这份 CLAUDE.md 的独特之处在于三点:一是明确的身份边界("不替代研究者判断"),二是写作纪律中的模糊词黑名单(禁用 align / close the loop 等 AI 套话),三是固定的交付格式——每次交付都按统一结构输出,不用猜 Claude 做到了哪一步。
React 官方文档站 的 CLAUDE.md 只有 42 行,是所有案例中最短的。以下提示词包含了原文的全部要素:
提示词:生成文档站项目的极简 CLAUDE.md(React.dev 风格)
请帮我为一个文档站项目生成极简的 CLAUDE.md(控制在 42 行左右)。项目信息如下:
yarn build(生产构建)、yarn lint / yarn lint:fix(代码检查)、yarn tsc(类型检查)、yarn check-all(一次性运行 Prettier + lint:fix + tsc + rss)src/ 下含 content/(MDX 文档:learn/ 教程、reference/ API 参考、blog/ 博客、community/ 社区)、components/、pages/、hooks/、utils/、styles/src/content/ 下文件时对应 Skill 自动推荐——learn/ 自动推荐教程页的结构和语气,reference/ 自动推荐参考文档页的结构和语气。MDX 组件(DeepDive/Pitfall/Note 等)通过 /docs-components 调用,Sandpack 代码示例通过 /docs-sandpack 调用。完整风格指南指向 .claude/docs/react-docs-patterns.md.prettierrc核心策略:CLAUDE.md 本身只做最薄的索引层,详细规则交给 Skill 和 slash command 承载。
这份 CLAUDE.md 代表了一种极端策略:CLAUDE.md 本身只做最薄的一层索引,把详细规则交给 Skill 和 slash command 来承载。教程页和参考文档页的语气差异不写在 CLAUDE.md 里,而是由 Skill 根据编辑的文件路径自动切换。如果你的项目配置体系足够完善,这种极简写法反而最好维护。
在 X 上的讨论中,中英文社区对 CLAUDE.md 形成了几个高度一致的共识:
"从空文件开始。" 陈成(@chenchengpro,610 赞)的建议是:别从模板开始,从空白文件开始。每次你对 Claude 说了同一句话两遍以上,就把那句话写进 CLAUDE.md。这样积累出来的文件,每一行都是实打实有用的。
"400 行砍到 150 行,一切都好了。" Axel Bitblaze(@Axel_bitblaze69,1900 赞)连续使用 Claude Code 两个月后的经验总结:他的 CLAUDE.md 一度扩展到 400 行,结果 Claude 开始随机忽略部分指令。精简到 150 行之后,指令遵循率明显回升。
Claude Code 之父的做法出乎意料地简单。 宝玉(@dotey,1200 赞)分享了 Boris Cherny(Claude Code 核心作者)的做法:整个团队维护一个 CLAUDE.md,提交到 Git,每周有人往里加内容。规则只有一条——"每次看到 Claude 做错了什么,就把'别这样做'写进去"。宝玉管这叫 "复利工程"——CLAUDE.md 越养越好,Claude 犯的错越来越少。
Apple 都在用 CLAUDE.md。 2026 年最大的新闻之一是 Apple 在 Support App 的更新包里意外泄露了内部 CLAUDE.md 文件(@aaronp613,13500 赞),证明 Apple 内部团队在用 Claude Code 开发应用。Apple 紧急发了一个补丁移除这些文件。有人评论说:"我们以前担心代码里泄露 API 密钥,现在还要担心泄露公司的 AI 工作方式。"
阶跃星辰(Step AI)在一份 2100 星的最佳实践文档里总结了四条 CLAUDE.md 反模式,每一条都很实际:
@ 引用不能无脑用。 盲目 @ 引用一个文件,每次会话都加载,浪费上下文。只写文件路径又没用,Claude 不会自己去看。正确做法是写清楚"什么时候该看这个文件、看了能得到什么"。看了这么多真实的 CLAUDE.md,有几件事变得很清楚:
好的 CLAUDE.md 都很短。 React.dev 52 行,Karpathy 65 行,Anthropic 官方 55 行,安正超那份也不到 100 行。没有一个超过 200 行的。
好的 CLAUDE.md 都是从实际遇到的问题中积累出来的。 Boris 的做法是每次 Claude 犯错就加一条规则。安正超的"禁止删代码绕过编译错误"明显对应一个真实发生过的场景。这些规则不是事先预想的,而是在使用中逐步沉淀的。
好的 CLAUDE.md 分两层写。 全局放思维方式(Karpathy 四原则),项目级放具体上下文(命令、架构、踩坑点)。两层各管各的,互不干扰。
好的 CLAUDE.md 不说废话。 不写 Claude 看代码就知道的事,不写标准编程约定,不写"请写高质量代码"。每一行的检验标准是:删掉这行,Claude 会不会犯错?不会就删。
如果你现在要开始写,最简单的路径是:
这种方式写出来的 CLAUDE.md,每一行都有来历,比任何模板都好用。
在给出我们自己的方案之前,有一件事值得先说。
调研中发现,几乎每个深度使用 Claude Code 的人都经历了同一条路径:先往 CLAUDE.md 里不断加东西,然后发现超过某个临界点之后效果反而变差,最终转向精简。
最典型的是 Pawel Jozefiak——用了 Claude Code 10 个月、跑了超过 1000 次会话之后,他的 CLAUDE.md 经历了四次重写:3 行 → 200 行(边缘情况清单)→ 471 行(把所有文档内联进来)→ 61 行(精简核心 + 外部参考文档按需加载)。
他总结的关键转折是:CLAUDE.md 不是百科全书,是路由层。它告诉 Claude"你是谁、怎么做决策、遇到具体问题去哪查",具体的操作细节放在外部文档里按需读取。
这和我们实际运营知识库的经验完全一致——我们的 CLAUDE.md 就是一个路由表:身份定位写在最前面,行为准则按主题分块(语言→工具→编码→交付),工具和导航占最大篇幅。禁令不是单独的开头段落,而是融在每条规则里——"包管理 uv(禁止 pip/poetry/conda)",做什么和不做什么写在同一句话里。
另一个被多个独立用户重复验证的规律叫复利效应——Pawel 叫它"指令设计"(instruction design),Matt Stockton 叫它"复合效应"(compounding effect),Boris(Claude Code 核心作者)的团队叫它"每次犯错就加一条"。核心是同一件事:CLAUDE.md 不是一次性写好的产品,而是一个持续积累的资产。它越养越好,Claude 犯的错越来越少。
理解了这两个规律——路由层思维和复利效应——下面的方案就容易理解了。
以下六份 CLAUDE.md 的结构都遵循同一个思路:先说你是谁和怎么做事,把禁令融进每条规则里,最后说交付标准。这不是随便排的——它反映了 CLAUDE.md 被读取时的实际优先级:Claude 先理解角色定位,再理解工作方式,最后才看具体约束。
内容创作最核心的问题不是"写不好",而是"写得不像同一个人"。换一个对话窗口,品牌声音就丢了。这份 CLAUDE.md 管的是创作的工作方式和品牌一致性——平台的具体参数放在各自的参考文档里。
提示词:生成内容创作者的 CLAUDE.md
请帮我生成一份内容创作场景的 CLAUDE.md。要求包含以下板块:
控制在 55 行左右,身份和禁用词部分留占位符让用户填自己的信息。
视频和文字是两套逻辑。写文章可以写长句、用括号注释、插脚注——视频不行,观众听一遍就过去了,听不懂不会倒回来。这份 CLAUDE.md 管的是"怎么用 Claude 管理视频项目"——从选题到脚本到发布的整个链条,不是某一个平台的参数。
提示词:生成视频创作者的 CLAUDE.md
请帮我生成一份视频创作场景的 CLAUDE.md。要求包含以下板块:
控制在 58 行左右。
一个人管整盘生意和在团队里只负责一块代码,CLAUDE.md 的写法完全不同。团队项目的 CLAUDE.md 通常只管代码——技术栈、架构、命令。一人公司的 CLAUDE.md 要管的是整个业务的运转逻辑:哪些产品、怎么部署、怎么决策、钱花在哪。Claude 需要看到全局,才不会在 A 产品的上下文里做出 B 产品的决定。
提示词:生成独立开发者/一人公司的 CLAUDE.md
请帮我生成一份一人公司场景的 CLAUDE.md,管理整盘业务的运转逻辑。要求包含以下板块:
git reset/revert/rebase/rm -rf 等不可逆操作禁止执行;密钥走环境变量或凭据管理不硬编码;生产数据库禁止命令行直连写操作;删除文件或目录先告知并得到确认;涉及付费操作(发邮件/调 API/部署生产)先确认控制在 53 行左右。
翻译项目的 CLAUDE.md 管的不是"某个词怎么翻"——那是术语表的事。它管的是翻译的工作原则、质量标准和协作流程:什么时候该问,什么时候不该猜,遇到不确定的术语怎么处理,翻完之后怎么自检。
提示词:生成翻译项目的 CLAUDE.md
请帮我生成一份翻译工作场景的 CLAUDE.md。要求包含以下板块:
glossary.md(格式:英文 | 中文 | 领域 | 备注);新术语先查表,没有就给译法同时加入表中;同一术语全文只用一个译法;专有名词保留英文首次括注中文;查询优先级:ISO/国标 → 行业通行译法 → 微软术语门户控制在 47 行左右。
数据分析的 CLAUDE.md 不应该是一份 matplotlib 参数手册——那些参数放在一个 Python 初始化脚本里就行了。它应该管的是分析的工作方法:先做什么后做什么、怎么选择统计方法、结果怎么呈现、怎么保证别人能复现你的分析。
提示词:生成数据分析师的 CLAUDE.md
请帮我生成一份数据分析场景的 CLAUDE.md。要求包含以下板块:
data/raw/(只读不动);处理结果 data/processed/;每步处理记录在 data/processing_log.md(做了什么、影响多少行、缺失值策略和理由);变量命名 snake_case 自解释(user_age 不是 ua);参数走 config/ 配置文件不硬编码;路径全部用相对路径config/plot_style.py,脚本引用不单独设。科研柱状图含误差线(标注 SD 或 SEM)。每张图必须有标题、坐标轴标签(含单位)、图例M = 3.45, SD = 1.23, t(58) = 2.41, p = .019, d = 0.82);描述方向("A 组显著高于 B 组"不是"差异显著");小数全文统一 2 位,百分比 1 位;图标题在图下方,表标题在表上方pyproject.toml 用 uv 管理;任何人跑 uv run python scripts/{name}.py 得到相同结果;探索用 Jupyter Notebook,正式产出写 .py 脚本控制在 59 行左右。
回过头看,这六份和前面拆解的 Karpathy、安正超、Anthropic 那些案例遵循同一套底层逻辑。结构都是这个顺序:
关键在第三点——把约束融进规则里,而不是单独拎出来放最前面。如果 CLAUDE.md 一打开就是一长串"禁止 A、禁止 B、禁止 C",Claude 看到的第一印象就是"这个用户很在意我不要犯错",而不是"这个项目需要我做什么"。先理解角色和做事方式,约束自然跟在后面,更符合 Claude 处理上下文的方式。
另一个值得注意的点:平台的具体参数不放在 CLAUDE.md 里。公众号排版多少像素、小红书封面多大尺寸、YouTube 标签要几个——这些信息当然有用,但它们变化快、只在特定场景下用到。放在 docs/ 目录的参考文档里,CLAUDE.md 用 @docs/wechat-rules.md 按需引用就好。CLAUDE.md 本身只管不变的工作原则。
这套结构适用于任何场景——不管你写公众号还是做数据分析,CLAUDE.md 的职责都是同一个:把你脑子里的工作方式写成 Claude 能理解和执行的规则。
到目前为止看到的所有案例,其实分成了两种截然不同的设计模式。小项目和大项目的 CLAUDE.md 写法完全不同——搞清楚你该用哪种模式,比纠结具体写什么更重要。
把所有规则直接写在 CLAUDE.md 里,一个文件解决一切。
项目根目录/
└── CLAUDE.md ← 身份 + 工作方式 + 约束 + 交付标准,全在这里
前面展示的 Karpathy 四原则、Dan Abramov 的 overreacted.io、React.dev 官方都是这种模式——一个文件,几十行,读完就知道怎么干活。
适合的场景:
优点:简单、直观、维护成本低。打开一个文件就能看到全部。
缺点:项目复杂度上升之后,文件会越来越长。超过 200 行 Claude 的遵循率明显下降(前面 Pawel 和 Axel 的经验都验证了这一点)。
CLAUDE.md 本身只做索引和路由,真正的内容分散在各层级的子文件里,Claude 按需加载。
~/.claude/CLAUDE.md ← 全局层:身份 + 跨项目的思维方式
项目根目录/
├── CLAUDE.md ← 项目层:全景 + 行为准则 + 工具路由表
├── .claude/rules/
│ ├── frontend.md ← 按路径懒加载:只处理前端文件时生效
│ └── backend.md ← 按路径懒加载:只处理后端文件时生效
├── docs/
│ ├── architecture.md ← 被 @import 引用的参考文档
│ └── platform-rules/
│ ├── wechat.md ← 公众号具体规则
│ └── youtube.md ← YouTube 具体规则
├── 子目录A/CLAUDE.md ← 子模块自己的规则(按需加载)
└── 子目录B/CLAUDE.md ← 子模块自己的规则(按需加载)
这是我们实际在用的方式。我们的知识库有 100 多个子目录,每个目录都有自己的 CLAUDE.md,根目录的 CLAUDE.md 是一张路由表——列出所有子目录的触发词和入口路径,Claude 根据当前任务自动找到该读哪个子目录的规则。
适合的场景:
优点:
.claude/rules/ 的 paths: 机制做按路径懒加载——前端规则只在编辑前端文件时生效,后端规则同理缺点:初始设计成本高,需要提前规划层级结构。小项目用这种模式是杀鸡用牛刀。
如果你决定用路由式,有几个实际操作中的关键点:
第一,根 CLAUDE.md 只放三类信息:身份定位、行为准则、导航路由。 不放具体的技术细节。比如"用 TypeScript strict 模式"这种规则放在对应子目录的 CLAUDE.md 或 .claude/rules/ 里,根 CLAUDE.md 只负责告诉 Claude "你是谁、怎么做事、遇到 X 话题去哪个目录找详细规则"。
第二,用触发词做路由。 在根 CLAUDE.md 里列一张触发词表:
| 触发词 | 去哪读 |
|--------|--------|
| 前端、组件、页面 | src/frontend/CLAUDE.md |
| 后端、API、数据库 | src/backend/CLAUDE.md |
| 部署、运维、监控 | docs/ops.md |
| 写文章、内容创作 | docs/content-rules.md |
Claude 看到你说"帮我改一下前端组件",就知道该去 src/frontend/CLAUDE.md 读具体规则。
第三,用 @import 引用而不是复制。
# 项目 CLAUDE.md
## 架构
@docs/architecture.md
## 编码标准
@docs/coding-standards.md
被引用的文件独立维护,CLAUDE.md 始终只是一个索引。最大支持 4 层嵌套。
第四,.claude/rules/ 做条件加载。 这是路由式最强的机制——规则文件加上 paths: 前置数据之后,只在 Claude 读到匹配路径的文件时才生效:
# .claude/rules/frontend-components.md
---
paths:
- "src/components/**/*.tsx"
---
组件用 forwardRef 包裹。
Props 接口必须导出。
样式用 Tailwind,不用内联。
Claude 编辑后端代码时,这些前端规则根本不会出现在上下文里。
实际上很多人是混合使用的。比如:
~/.claude/CLAUDE.md:内嵌式,放 Karpathy 四原则这种通用行为约束./CLAUDE.md:路由式,做索引和导航./src/CLAUDE.md:内嵌式,该模块的具体规则直接写Karpathy 本人就是这么做的——全局放四原则(内嵌式),llm-council 项目放详细架构和踩坑点(内嵌式,因为项目不大),两层各管各的。
选哪种模式取决于一件事:你的规则加起来超过 200 行了吗? 没超过,内嵌式就够了。超过了,开始往路由式迁移——把不常用的、只对特定模块生效的规则拆出去。
Claude Code 还有 Skills 和 Hooks,三个各管一件事:
| 机制 | 放什么 | 触发方式 |
|---|---|---|
| CLAUDE.md | 事实性规则("始终用 2 空格缩进") | 每次会话自动加载 |
Skills(.claude/skills/) |
多步骤流程("部署到生产环境的 5 步操作") | 手动触发(/skill-name)或自动匹配 |
Hooks(.claude/settings.json) |
确定性门控("每次写文件后自动运行 Prettier") | 工具调用前后自动执行 |
三者的关系是:CLAUDE.md 管"你应该怎么做",Skill 管"具体按什么步骤做",Hook 管"不管你怎么想,这件事一定会自动发生"。
🔍 深入一步:如果 Claude 反复忘记某件事(比如写完代码不跑格式化),在 CLAUDE.md 里加十遍强调也没用——换成 Hook。Hook 是脚本,写文件后自动执行,不存在"忽略"的可能。CLAUDE.md 是软约束,Hook 是硬约束。
如果你现在还没有 CLAUDE.md,或者只有 /init 生成的默认版本,按这个节奏来:
第一天:从空文件开始,只写三行
# [你的项目名]
交互语言:简体中文
就这些。然后正常用 Claude Code 干活。不要试图一次写完。
前三天:每次被 Claude 气到,就加一条
Claude 给你写了 class 组件?加一条"只用函数组件 + hooks"。Claude 用了 npm?加一条"包管理用 pnpm"。Claude 写了一个 500 行的大函数?加一条"函数不超过 30 行"。
每条规则的来历都很清楚——它不是你预想出来的,是 Claude 实际犯的错让你补上去的。
第一周结束:回头整理一遍
这时候你的 CLAUDE.md 大概有 20-40 行,全是实战中积累的规则。做一次整理:
一个月后:判断需不需要升级到路由式
如果你的 CLAUDE.md 还在 100 行以内,保持内嵌式就好。如果已经超过 200 行,开始把不常用的规则拆到 .claude/rules/ 或 docs/ 里,CLAUDE.md 只留索引。
持续维护:复利积累
每次代码审查发现 Claude 本该知道的信息、每次你在新会话里重复说了同样的纠正——都是往 CLAUDE.md 里加一条的信号。反过来,每次你加了规则但 Claude 的行为没有改善——考虑这条规则是不是太模糊了,或者太长了被淹没了。
这就是前面提到的复利效应:CLAUDE.md 越养越好,Claude 犯的错越来越少。
来看一份真实的 before/after 对比,体会"差的 CLAUDE.md"和"好的 CLAUDE.md"之间的具体差距。
改写前(常见的初始版本):
# CLAUDE.md
This is a Next.js project with TypeScript and Tailwind CSS.
Please write clean, maintainable code.
Follow best practices for React development.
Use functional components.
Make sure the code is well-tested.
Don't use any deprecated APIs.
Keep the code DRY.
Write meaningful commit messages.
这份 CLAUDE.md 有七个问题:
next.config.js 就知道了,等于没写改写后:
提示词:生成前端项目的 CLAUDE.md(改写后的好版本)
请帮我为一个前端项目生成 CLAUDE.md,交互语言简体中文。要求包含以下板块:
pnpm dev(开发)、pnpm build(构建)、pnpm test(测试)、pnpm typecheck && pnpm lint(类型检查+lint,提交前必跑){组件名}Props;named export(page.tsx / layout.tsx 例外);提交信息写改了什么文件和为什么,不写"refactor for better maintainability"src/lib/auth.ts 的 session 逻辑看起来能简化但不要动——它处理了三种边界情况去掉任何一个线上出问题;数据库迁移文件一旦提交就不能修改只能新建迁移控制在 32 行左右。每一条都要具体、可验证,"会坑你的事"段落预判 Claude 会在哪里犯错并提前堵住。
改写后每一条都是具体的、可验证的。"禁止 Redux"比"follow best practices"管用得多。"提交前必跑 pnpm typecheck && pnpm lint"比"make sure the code is well-tested"清楚得多。最后的"会坑你的事"段落是从 Anthropic 官方学来的——预判 Claude 会在哪里犯错,提前堵住。
写到 300 行以上,Claude 开始随机丢规则。不是它不想遵守,是上下文窗口被无关内容挤满了,有用的指令被埋掉了。定期回头删——每条规则先问自己:删了它,Claude 的输出真的会变差吗?拿不准就先删掉,观察一周。
缩进用几个空格、字符串用单引号还是双引号——这些事有 ESLint、Prettier、Ruff 负责,比 Claude 又快又准。你在 CLAUDE.md 里写一遍等于花高价请 AI 干 Linter 就能干的活。把格式化交给工具,用 Hook 自动运行就好。
一处写"用 default export",另一处写"禁止 default export"。两条规则矛盾,Claude 随机挑一条遵守。结果就是行为不可预测,你还以为是 Claude 的问题。一个规则只在一个地方声明,定期检查有没有自相矛盾的。
CLAUDE.md 还写着"Next.js 13 的 app 目录",项目早升到 15 了。Claude 按过时信息写代码,出的问题比没写还难排查。解决办法:CLAUDE.md 和代码一起签入 Git,升级依赖的时候顺手过一遍。
/init 生成的 CLAUDE.md 是万金油——什么项目都能用的东西,约等于什么项目都用不好。可以拿它当起点,但生成完必须逐条过,删废话,补你项目特有的上下文。
在 CLAUDE.md 里写了三段话解释"为什么选 FastAPI 而不是 Flask"的历史渊源。Claude 不在乎你的故事,它只需要一句"用 FastAPI,禁止 Flask"。长段解释放 docs/ 目录里,CLAUDE.md 里给一个链接就够了。
写完 CLAUDE.md 后,对照这份清单检查一遍:
和 Cursor 的 .cursorrules 什么关系?
各管各的。CLAUDE.md 是 Claude Code 的,.cursorrules 是 Cursor 的,两边互不认。如果你两个工具都用,得各写一份。
写了规则 Claude 还是不听怎么办?
三种可能:文件太长规则被淹没了(精简到 200 行以内);规则太模糊 Claude 不知道怎么执行("写好代码"→ 改成"函数不超过 30 行");规则跟当前任务无关 Claude 自动跳过了(拆到 .claude/rules/ 用 paths 限定作用范围)。如果是必须遵守的硬性要求,换成 Hook。
多人协作时 CLAUDE.md 怎么管?
项目级 CLAUDE.md 签入 Git,团队共同维护。个人偏好放 CLAUDE.local.md(在 .gitignore 里),不影响其他人。Boris(Claude Code 核心作者)的团队做法是:每周有人往里加内容,代码审查时通过 @.claude 让 Claude 自动把新规则写入 CLAUDE.md。
CLAUDE.md 和 AGENTS.md 什么关系?
CLAUDE.md 是 Claude Code 专用的。AGENTS.md 是 OpenAI Codex 用的,格式和作用类似。很多项目用 symlink 让两个文件指向同一份内容(CLAUDE.md → AGENTS.md),实现跨工具兼容。
支持中文吗?
完全支持。CLAUDE.md 是标准 Markdown 文件,语言不限。在开头写一句"交互语言:简体中文"即可。
这篇文章覆盖了从官方文档到真实案例到实操步骤的完整链路。但最重要的一件事只有你自己能做——打开你的项目,创建一个空的 CLAUDE.md,开始用 Claude Code 干活,每次被它做错了什么就加一条。一周之后回头看,你会发现这份文件比任何模板都管用,因为每一行都是你自己的实战经验。
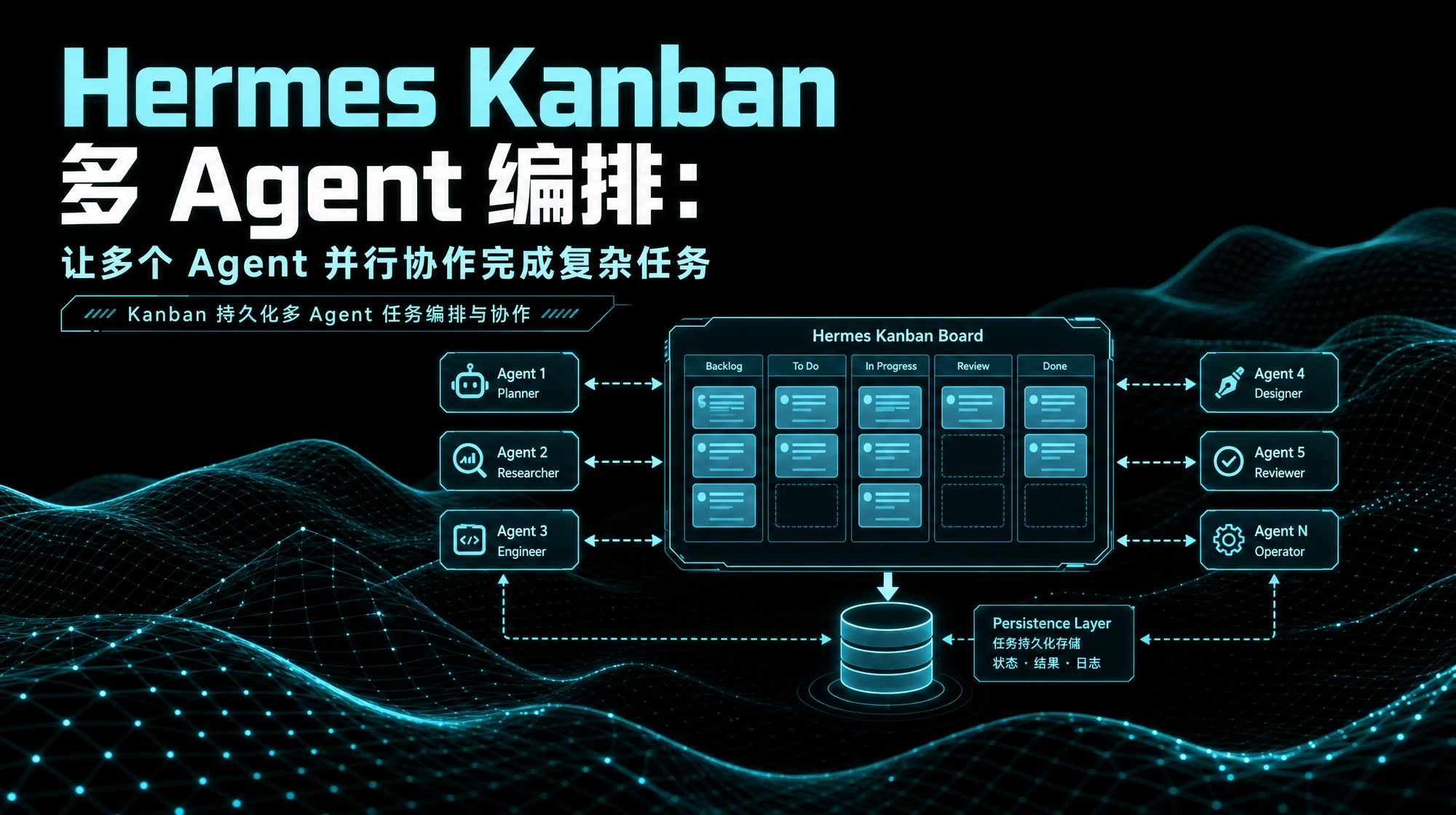
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
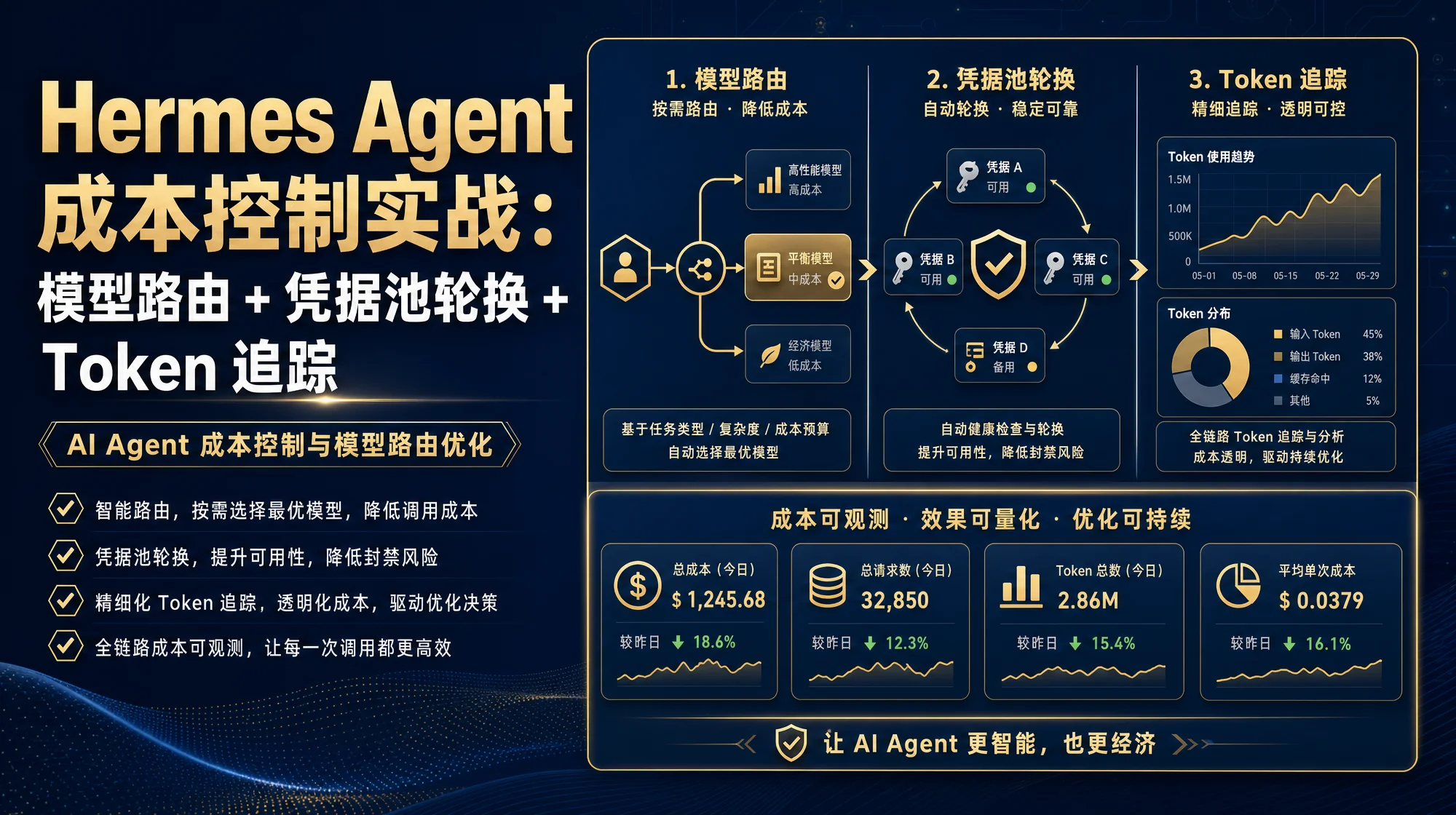
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
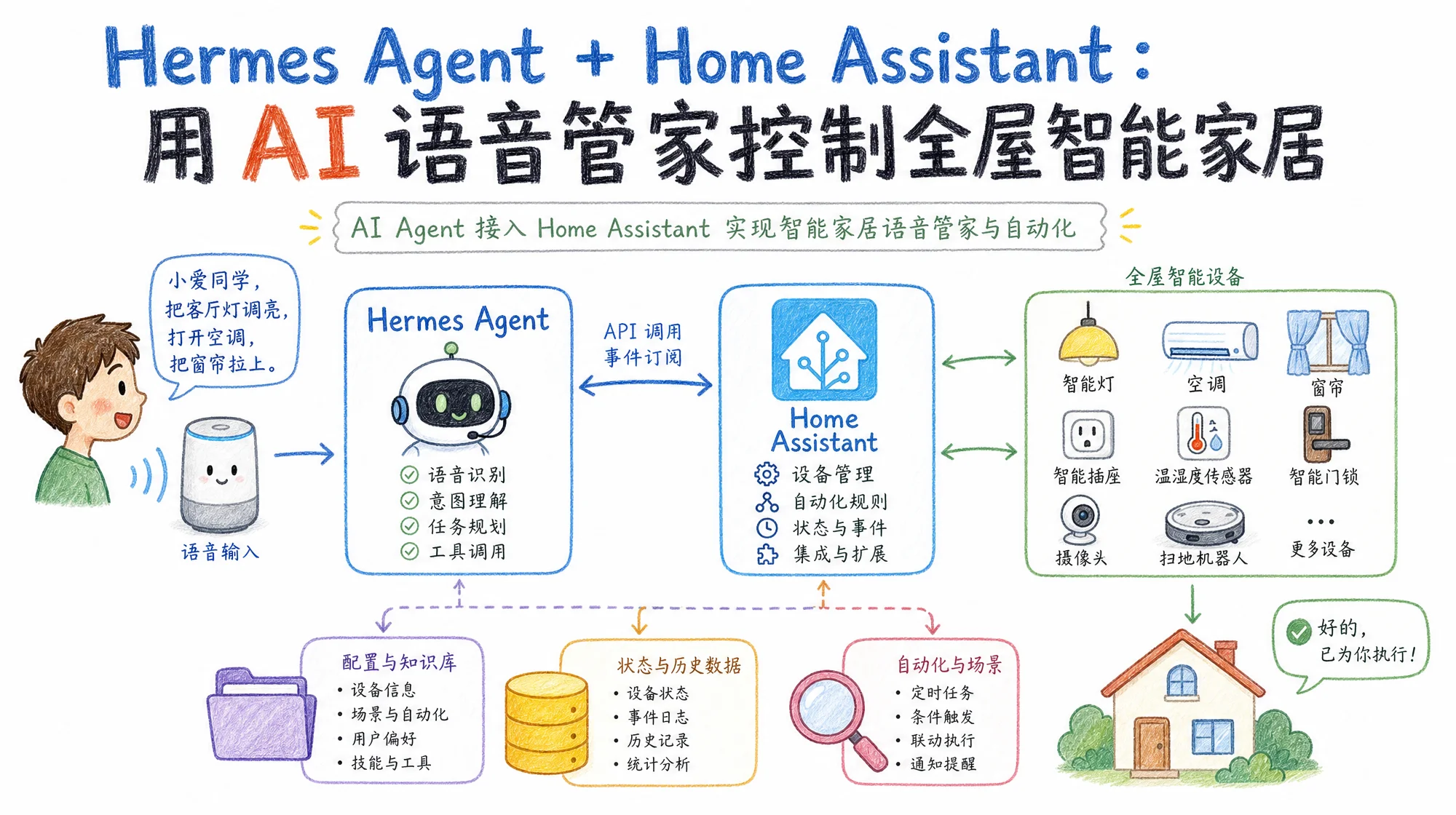
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 支持三种本地推理后端:Ollama 一键启动、LM Studio 可视化管理、vLLM 生产级吞吐。本文覆盖完整接入配置、64K 上下文铁律、模型选型矩阵(按硬件/任务/语言推荐)、社区高频痛点解决方案,以及翔宇 GLM→DeepSeek→Gemini 三模型实战策略。
每周精选 AI 编程与自动化实战内容,直达你的邮箱