Agent 知识库实战:让 Claude Code 拥有持久记忆与一人公司 AI 生产线
Agent 知识库完整搭建教程:8 层通用架构 + 22 万字规范体系 + 100+ CLI 与 Skill。翔宇花 3 个月研究 31 个知识管理理论,蒸馏出让 Claude Code 拥有持久记忆、自我进化能力的通用架构。从每次从零开始变成越用越懂你,一套架构适配所有行业。
Agent 知识库完整搭建教程:8 层通用架构 + 22 万字规范体系 + 100+ CLI 与 Skill。翔宇花 3 个月研究 31 个知识管理理论,蒸馏出让 Claude Code 拥有持久记忆、自我进化能力的通用架构。从每次从零开始变成越用越懂你,一套架构适配所有行业。
翔宇做了一个小工具,叫 brain-mcp。名字很直白——brain 是大脑,MCP 是 AI 工具连接外部数据的标准协议。合在一起就是:把你的知识库变成 AI 的第二大脑。
用开源框架 OpenClaw 部署 10 个 AI Agent,像公司部门一样 24 小时自动协作。完整架构选型、三级通信体系、6 种多 Agent 模式对比,附渐进式上手路径。
Agent 知识库完整搭建教程:8 层通用架构 + 22 万字规范体系 + 100+ CLI 与 Skill。翔宇花 3 个月研究 31 个知识管理理论,蒸馏出让 Claude Code 拥有持久记忆、自我进化能力的通用架构。从每次从零开始变成越用越懂你,一套架构适配所有行业。

你可能已经在用 Claude Code 了,但每次打开新会话都要重新告诉它你是谁、上次教的经验存不到哪里、写作风格每次随机——翔宇也被这个问题折磨了三个月。直到有一天翔宇意识到:问题不在模型也不在工具,而在于大家都在卷工具,却没有人把「上下文」当成一个工程问题来设计。
于是翔宇用三个月蒸馏出一套通用的 Agent 知识库:8 层架构 + 22 万字规范 + 100+ CLI 与 Skill,同时支持 Claude Code / Codex / Gemini CLI / OpenClaw 四框架同步。这篇文章是配套 YouTube 视频的文字延伸版——视频看演示,文章查参数、读方法论、抄提示词。读完你不仅能照着搭一套自己的,更重要的是会理解为什么要这么设计。
本教程配套视频已发布在 YouTube,建议搭配视频一起学习效果更佳。视频包含完整的双行业实战演示和所有操作细节,本文是方法论和参数参考文档。
Agent 知识库解决的核心问题是「AI Agent 每次打开都要从零开始介绍自己」。翔宇把这个问题拆成两个层面来看:工具端和上下文端。
左边是工具端——2026 年 AI 工具爆发,OpenClaw 四个月拿下 25 万 GitHub 星标,Gemini CLI(谷歌命令行助手)、Codex(OpenAI 编程助手)、OpenCode 每周都有新版本。根据最新数据,62% 的开发者已经在用 AI 编码工具。翔宇追了半年,核心产出没增加多少。
右边是上下文端——你的知识、经验、判断标准。这些永远属于你,换工具不会消失。
打个比方:工具是发动机,上下文是导航加驾驶习惯。发动机再好,没有导航也是空转。
所以翔宇的第一个认识是回归本我:与其追工具,不如回到你自己的内容。知识库就是把你的上下文固化下来,让 AI 能读到。你可能听过市面上的 AI 记忆方案——Mem0、Zep、Letta 这些框架,2026 年很火,但它们解决的是让 AI 记住对话历史的问题。翔宇要解决的问题更大:不只是记住聊过什么,而是让 AI 在开口之前就知道你是谁、你怎么做事、你的标准是什么。这不是一个记忆框架,这是一个人的完整工作系统的数字化。
💡 核心结论
AI Agent 运行靠两样东西:上下文和工具。大家都在卷工具,却没有人把「上下文」当成一个工程问题来设计——这是一人公司时代最大的认知差。
翔宇查了 31 个理论框架之后做的第一个关键决策:格式选 Markdown。
主流方案走的是向量数据库 + 知识图谱的路线——需要运维、需要云服务、还绑定特定框架。翔宇反其道而行。五个理由:
| 维度 | Markdown | 向量数据库 |
|---|---|---|
| 可读性 | 人 + AI 双向可读 | 只有 AI 可读 |
| 追溯 | Git 原生版本管理 | 需要额外版本方案 |
| 依赖 | 零依赖,文本即数据 | 需要服务 + 运维 |
| 跨框架 | 任何 AI 工具都能读 | 绑定特定框架 |
| 扩展 | 加字段不用改结构 | 改 Schema 要迁移 |
翔宇的经验是:对个人和一人公司来说,Markdown 比数据库更好。加字段不用改结构、不需要运维、搜索只要一条命令。你不需要为了管理知识去学数据库。简单的东西才能持久,持久的东西才能复利。
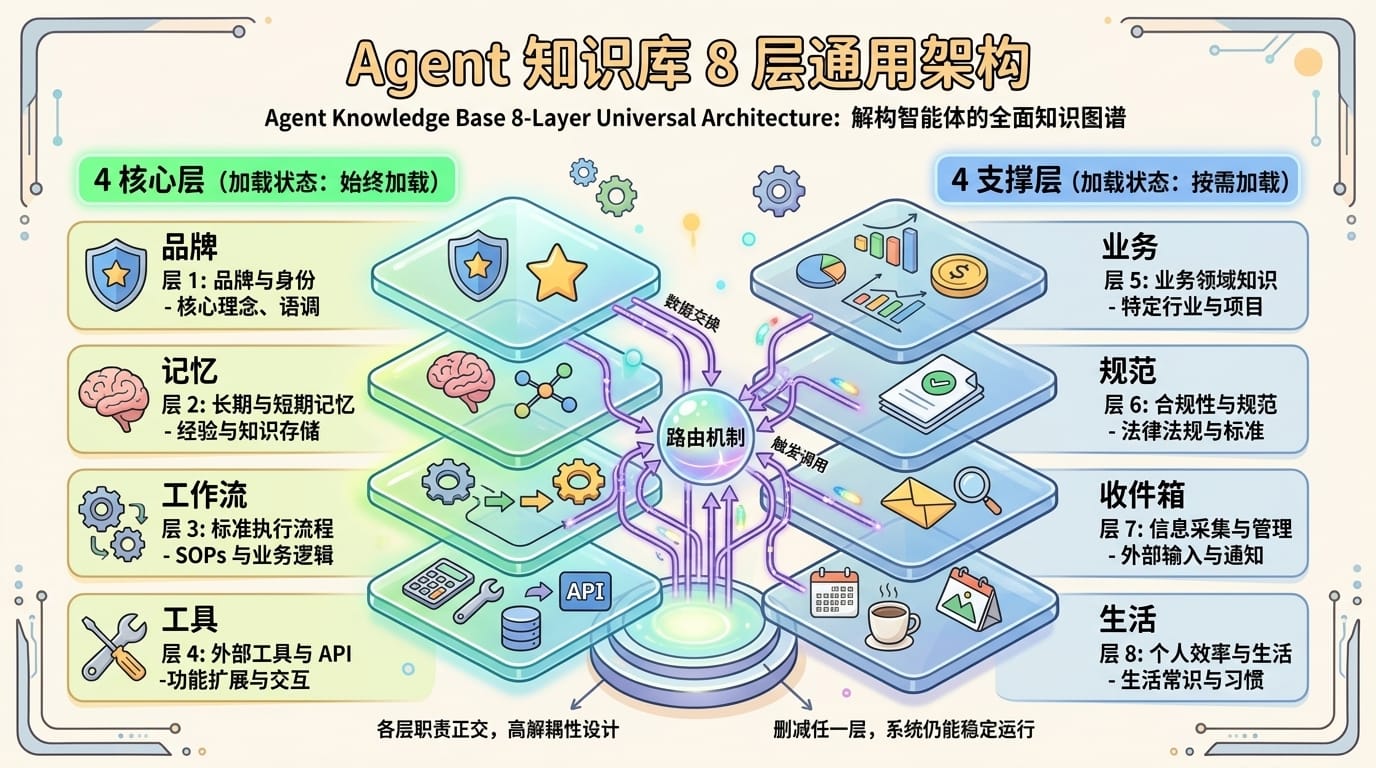
不管你做什么行业——自媒体、电商、律师、教师——做事都绕不开 8 个核心问题。翔宇把这 8 个问题映射成 8 层架构:
| 层 | 对应问题 | 职责 | 加载策略 |
|---|---|---|---|
| 品牌层 | 我是谁? | 定位、表达风格、受众、专长 | 始终加载 |
| 记忆层 | 学到了什么? | 规则、偏差记录、踩坑复盘 | 始终加载 |
| 工作流层 | 怎么做? | SOP、步骤拆解、组合编排 | 按触发词 |
| 工具层 | 用什么工具? | CLI、Skill、MCP、凭证 | 按触发词 |
| 业务层 | 正在做什么? | 项目、产品、素材、运营 | 按触发词 |
| 规范层 | 质量标准是什么? | 元规范 + 写作 / 工具 / Skill 规范 | 按触发词 |
| 收件箱 | 新信息怎么来? | 外部信息唯一入口 + 四阶段管线 | 按触发词 |
| 生活层 | 工作之外呢? | 健康、财务、关系、休闲 | 按触发词 |
翔宇要特别强调:前 4 层是核心,做事必须有的;后 4 层是支撑,做好事情的保障。品牌和记忆始终加载,其他按需。这样上下文不会撑爆。
这套架构的精髓不在于 8 层是哪 8 层,而在于正交性——每一层职责不重叠,删掉任何一层其他层依然能跑;同时又通过路由机制联动起来。
8 层架构听起来很多,翔宇用五层路由把这 8 层串成一个永远不会乱的系统:
| 层级 | 文件 | 职责 |
|---|---|---|
| 根 CLAUDE.md | CLAUDE.md |
全局路由表 + 触发词 |
| 域 CLAUDE.md | {品牌/工具/工作流…}/CLAUDE.md |
域内子目录索引 |
| 子域 CLAUDE.md | 品牌/风格/CLAUDE.md 等 |
子域内文件索引 |
| 目录 CLAUDE.md | 品牌/风格/youtube/CLAUDE.md |
具体平台索引 |
| 文件 | 具体 .md 文件 | 实际内容 |
三条铁律:
翔宇给你一个判断标准:打开任意一个 CLAUDE.md,3 秒内能找到你要的文件路径——做到了就是合格的索引;做不到就是需要重新设计的百科全书。
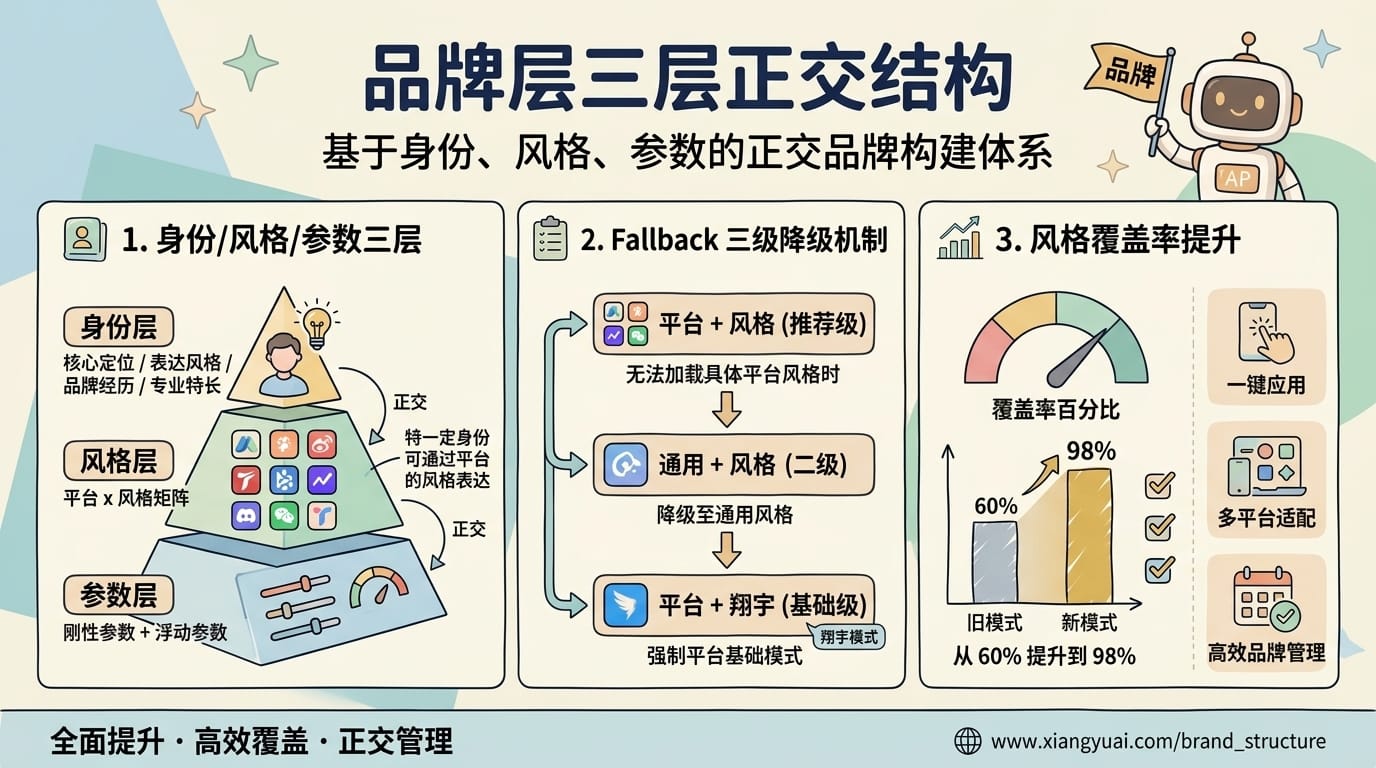
品牌层回答「我是谁、写给谁、什么调性」,是 Agent 知识库的灵魂。翔宇把品牌层设计成三层正交结构:
第一层:身份
定位、表达风格、视频讲解风格、专长、经历、介绍、愿景、商业模式,共 8 个文件。写作前必读「定位 + 表达风格」两个文件。
第二层:风格
按平台分目录——微信 / 小红书 / 推特 / YouTube / 官网 / FlowUS / 抖音 / B站 / 知乎 / 通用。每个平台目录下再分风格子目录(翔宇 / 费曼 / 引路人 / 实战)。每个风格自包含三件套:平台规则 + 语言风格 + 结构 + 系列。
第三层:风格参数与 Fallback
风格文件用「刚性参数 + 浮动参数」两类描述。刚性参数是风格的基因(句长、术语策略、人称),不同主题都不变;浮动参数随主题调节(情绪基调、数据密度、演示节奏)。
风格 Fallback 三级降级:
平台+风格存在 → 直接用
平台+风格不存在 → 通用+同风格
通用+风格也不存在 → 平台+翔宇(默认风格)
翔宇在实际生产环境中的数据是:三层正交 + Fallback 降级让风格覆盖率从 60% 提升到 98%——几乎任何平台任何主题都有对应风格可用。
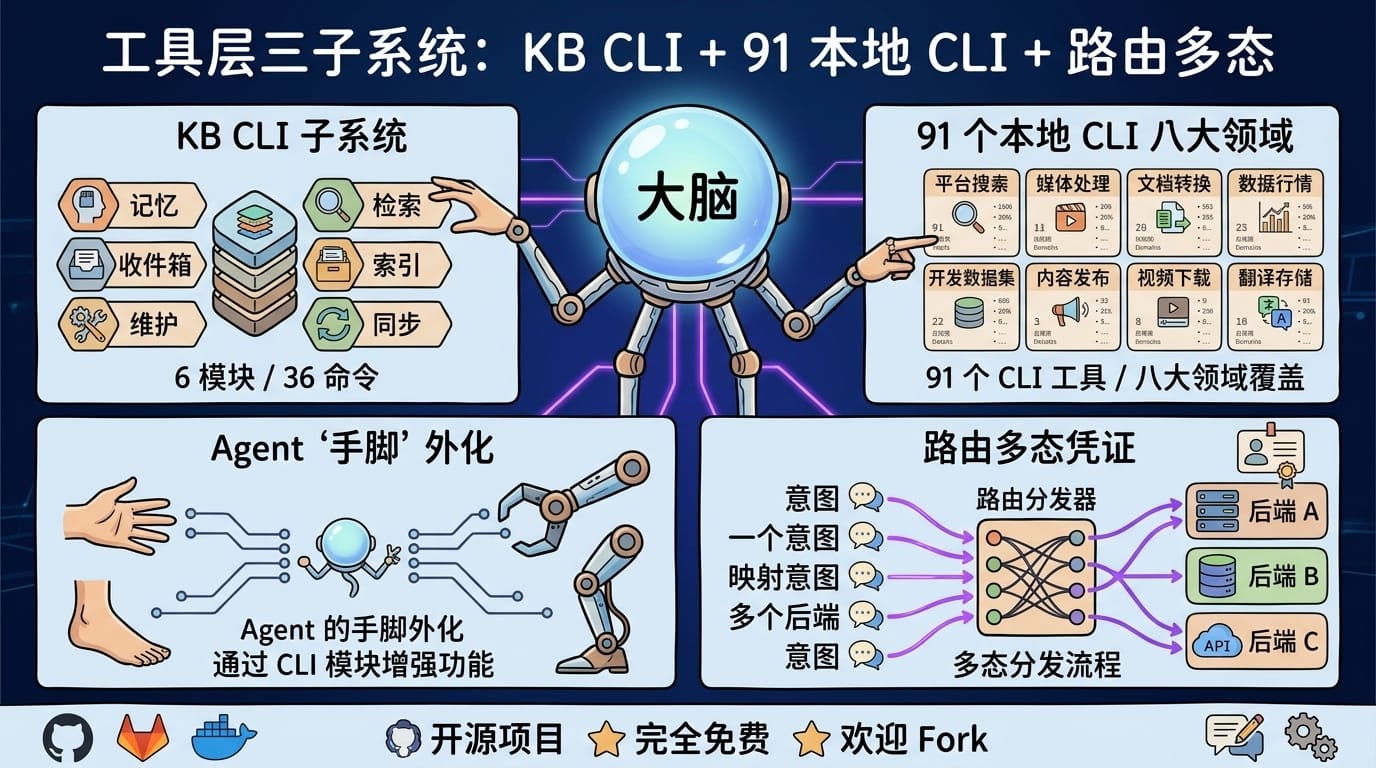
工具层的核心是把 Agent 的手脚外化——Agent 本身是大脑,手脚靠 CLI / Skill / MCP。翔宇的工具层有三个子系统:
KB CLI:6 模块 36 命令
记忆 / 检索 / 收件箱 / 索引 / 维护 / 同步,每个模块 4-8 个命令。典型命令如 KB memory add、KB query smart、KB inbox approve、KB index update、KB health、KB sync verify。
91 个本地 CLI:八大领域
平台搜索 / 媒体处理 / 文档转换 / 数据行情 / 开发数据集 / 内容发布 / 视频下载 / 翻译存储。每个 CLI 独立维护、独立凭证、独立文档。
路由多态凭证
同一个意图(如「搜索」)映射到多个后端(YouTube / Twitter / TikTok / 小红书 / 微博 / 知乎…),每个后端有独立凭证和参数。Agent 只看意图,不关心后端。
翔宇的经验是:工具数量不是关键,效率等于委托程度——有多少重复工作能从你身上转交给工具。91 个 CLI 听起来多,真正高频使用的可能只有 15 个。其他 76 个是「偶尔需要时一条命令就能用」的长尾。
💡 核心结论
效率 = 委托程度。工具不是越多越好,关键是有多少重复工作能从你身上外化到 Agent 的手脚上。
规范系统是 Agent 产出质量的保障。没有规范时 AI 写出来的东西 AI 味十足;有了规范后,它知道翔宇不用「此外」要用「那么好了」,输出质量立刻稳定。
17 套规范全景:写作风格 / 品牌 / 产品 / 工具 / Skill / CLAUDE.md / Markdown / 收件箱 / 知识库…每一套覆盖一类产出物。
元规范 + 6 章骨架约束语言:所有规范文件本身遵循同一个元规范——定位 / 格式参数 / 能力限制 / 审核 / 禁区 / 变更记录。这套元规范本身也是一个规范文件,自洽。
覆盖矩阵:每类产出物映射到对应的规范文件,避免遗漏。
Skill 16 正交:Skill 设计的 16 个正交维度(单文件 / 多文件、无状态 / 有状态、交互 / 非交互…),让 Skill 之间不重叠、可组合。
翔宇在这里展开讲:规范不是束缚,是解放。Claude Code 官方文档也提到——Claude 在能验证自己工作时表现显著更好。没有明确的成功标准,它可能产出看起来对但实际不工作的东西。规范就是这个「成功标准」。花时间写规范是投资不是成本——每写一页规范,未来就能节省 100 次重复纠正。
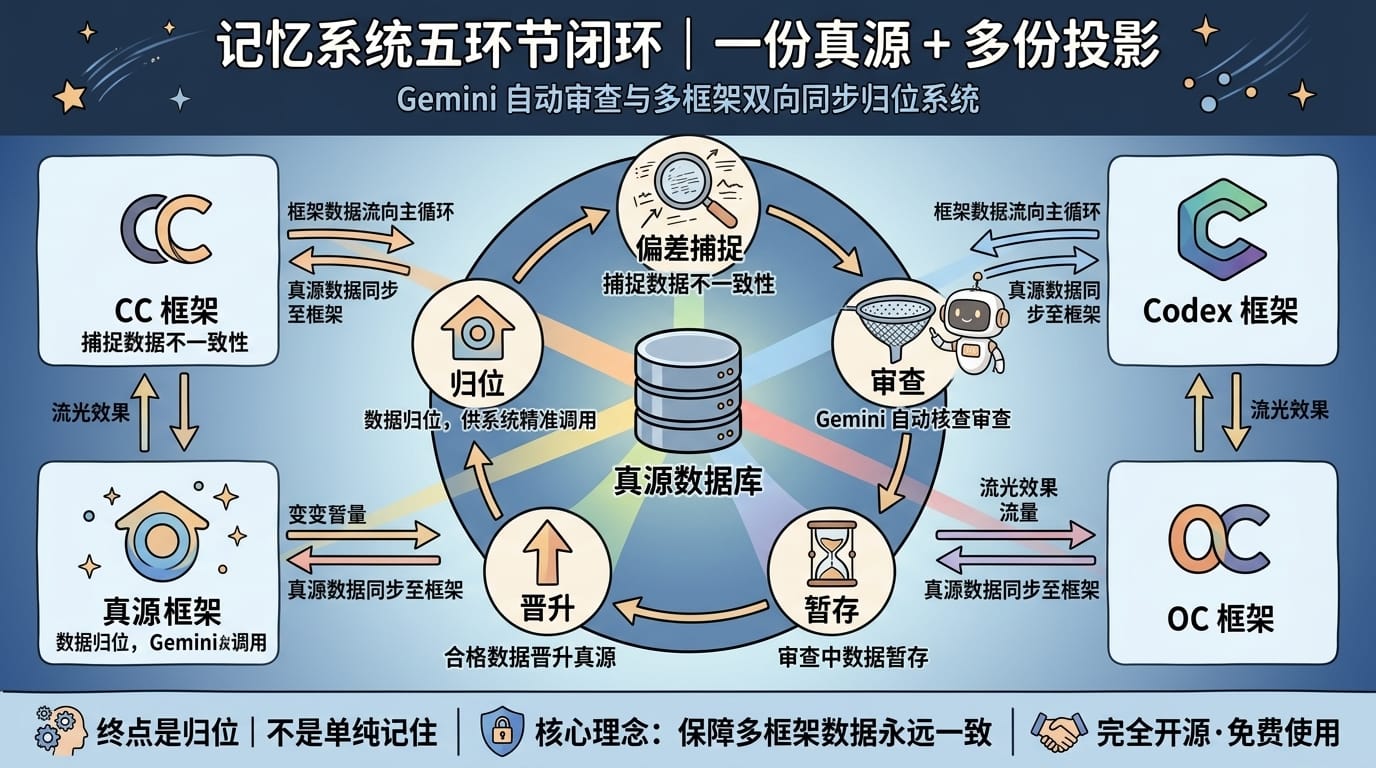
记忆系统解决的是「AI 犯过的错会不会再犯」的问题。翔宇的记忆系统有五个环节:
KB memory add "{发现}" 写入暂存KB memory consolidate --auto,让 Gemini Flash 自动过滤 / 去重 / 分类 / 精简 / 合并规则.md,成为始终加载的核心规则KB memory sync 把规则双向同步到 Claude Code / Codex / Gemini CLI / OpenClaw翔宇要特别强调:记忆的终点不是「记住」,是「归位」——让每条经验最终沉淀到它该去的地方。暂存只是临时缓冲,规则.md 是中间枢纽,最终所有经验都应该归位到品牌 / 工具 / 规范 / 工作流等具体层。
💡 核心结论
记忆的终点不是「记住」,是「归位」。经过 3+ 次引用验证的规则应当归位到对应规范文件,不再占用记忆槽位——否则记忆系统自己就会变成新的技术债。
多框架同步的价值:一个人可能同时用 Claude Code 写代码、用 Codex 跑实验、用 Gemini CLI 查资料、用 OpenClaw 做多 Agent 编排。记忆系统让这 4 个框架共享同一套规则,不用在每个框架里重复配置。
收件箱是外部信息的唯一入口。任何外部信息(PDF、网页、书籍、邮件、截图)都必须经过收件箱的四阶段管线才能进入知识库:
| 阶段 | 操作 | 命令 |
|---|---|---|
| 提取 | 原始内容抽取(PDF → 文本、网页 → MD) | KB inbox extract |
| 提炼 | 结构化 + 去重 + 归类 | KB inbox refine |
| 审核 | 翔宇人工确认(或 Gemini 自动审核低重要性) | KB inbox approve |
| 入库 | 归位到对应目录 + 更新索引 | KB index update |
翔宇给你一个判断标准:一条信息有没有资格进知识库?问三个问题——会被引用吗?能产生决策吗?不写下来会忘吗?三个都不是 → 扔掉。
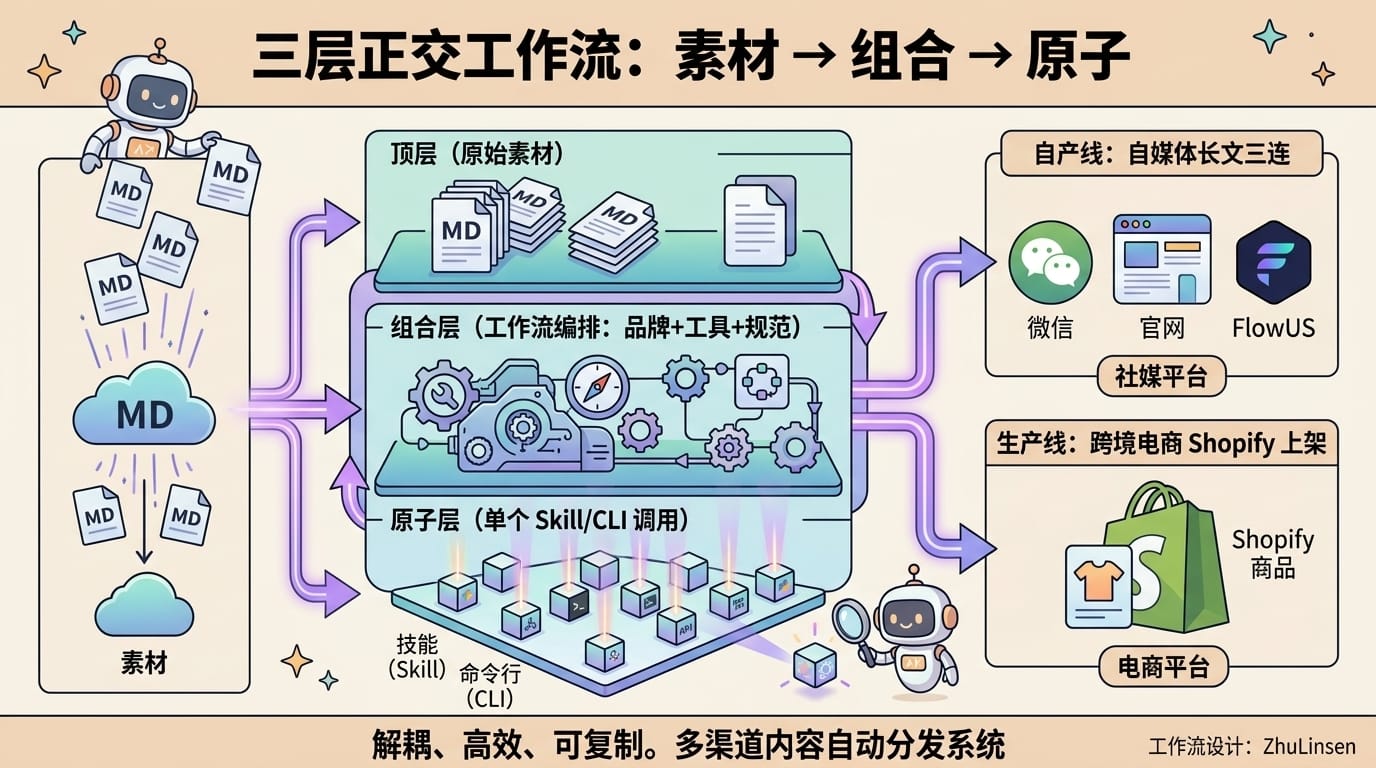
工作流层把前 7 层编排成可执行的 SOP。翔宇把工作流设计成三层正交解耦:
视频里演示两条完整生产线:
自媒体长文三连:一句话输入「帮我写一篇 AI 编程的长文发到公众号」→ 自动读品牌身份 / 风格 / 微信平台规则 → 生成长文 + 配图 + 封面 → 发布到微信公众号 / 官网 / FlowUS 三平台。
跨境电商 Shopify 上架:一句话输入「竹制鞋架值不值得做」→ 自动读 HomeNest 品牌 / 选品规范 / CLI 工具链 → 抓搜索量 / 竞品 / 差评 / 利润率 → 生成选品报告 → 进一步生成 Listing 文案 → 上架 Shopify。
同一个 Claude Code,两种完全不同的人格——区别只在背后的知识库。
一套完整的 Agent 知识库跑起来,翔宇的月度实际成本是这样:
| 项目 | 用途 | 月成本 |
|---|---|---|
| Claude Code(Anthropic API) | 主力对话 + 编码 + 写作 | ~$80 |
| Gemini Flash | 记忆审查 + 收件箱分类 + 低重要任务 | <$2 |
| OpenRouter | 多模型备份与切换测试 | ~$10 |
| Brave Search API | 每日检索 | ~$5 |
| Firecrawl | 网页抓取(SPA / 反爬) | ~$20 |
| Cloudflare R2 | 图床 + 文件存储 | $0(免费额度) |
| 合计 | ≈ $115 / 月 |
翔宇的经验是:80% 的成本集中在 Claude Code 主模型上,其余都是长尾。想省钱的关键不是少用工具,是让 Gemini Flash 接管低重要性任务——记忆审查、收件箱分类、文件重命名、批量 Rename,这些完全不需要 Claude 主力模型介入。翔宇实测接入 Gemini Flash 审查后,月度成本从 $180 降到 $115,质量几乎无感知损失。
💡 核心结论
月 $115 换回一套「不再每次从零开始」的 Agent 工作系统,每月省下的沟通成本远超这个数——真正贵的不是 API,是重复解释的时间。
Q:我没用过 Claude Code,能直接学这套知识库吗?
可以,但建议先看 CC视频 38 建立基础认知。Agent 知识库的设计原则是通用的——即使你用的是 Cursor、Gemini CLI、OpenClaw,这 14 条原则和 8 层架构同样适用,只是路由文件的加载方式略有差异。
Q:22 万字规范我真的需要全部写完吗?
不需要。翔宇建议从「品牌 / 记忆 / 工具 / 规范」四层的最小闭环开始,先让 Agent 跑起来,再根据实际踩坑逐步扩展。课程里的 133 个规范文件是翔宇三个月的完整沉淀,你可以直接复用并按需裁剪,不需要从零写。
Q:Markdown 真的比向量数据库更好吗?在什么场景下该选向量数据库?
对个人和一人公司,Markdown 几乎总是更好——零依赖、人可读、Git 可追溯、跨框架可用。向量数据库更适合的场景是:文档量超过 10 万篇、需要跨文档语义搜索、有专门的运维团队。对大多数人来说,Markdown + 一个轻量向量索引(LanceDB / Chroma)就够了。
Q:多框架同步(CC / Codex / Gemini / OC)是怎么做到的?
核心思路是「一份真源 + 多份投影」。规则.md 是真源,sync 命令把它投影到每个框架对应的配置文件(CC 的 CLAUDE.md、Codex 的 AGENTS.md、Gemini 的 GEMINI.md、OC 的 workspace)。任一框架的修改都先回到暂存,经 Gemini 审查后再晋升到真源,保证多框架永远一致。
Q:这套知识库可以用在非编程场景吗?比如纯写作、选品、教学?
完全可以。翔宇的两个实战演示就是自媒体写作和跨境电商选品——都不是编程场景。8 层架构本身是通用的,换个行业只需要换品牌层和业务层的内容,其他层的结构不变。
这篇文章把 Agent 知识库从理念到架构到工程的完整方法论都摊开了。翔宇三个月踩过的坑、查过的 31 个理论、写过的 22 万字规范、设计过的 100+ CLI 与 Skill——所有能沉淀成文字的都在这里。剩下的只有一件事:你自己动手搭一个。
翔宇的一个观察是——真正让 Agent 变聪明的不是模型升级,而是上下文的工程化。模型每半年升一代,但你的上下文只要设计一次就能永久复利。这是一场从追工具到做内容的思维转变。

翔宇做了一个小工具,叫 brain-mcp。名字很直白——brain 是大脑,MCP 是 AI 工具连接外部数据的标准协议。合在一起就是:把你的知识库变成 AI 的第二大脑。

用开源框架 OpenClaw 部署 10 个 AI Agent,像公司部门一样 24 小时自动协作。完整架构选型、三级通信体系、6 种多 Agent 模式对比,附渐进式上手路径。

AI 编程进阶技巧,让 Skill 学会自己发现并修复 Bug 的闭环机制。从手动调试升级到智能体自修复,大幅减少 Skill 开发中占比六成的调试时间。教程涵盖双阶段循环设计包含静态检查和动态运行、四重验证体系让缺陷无处可逃、智能退出策略避免无限循环修复,以及错误日志结构化分析方法,帮你构建真正可靠的自治 Skill 系统。

用五个 Claude Code Skill 打造 Twitter 自动化流水线的实战教程。从对话式编程跨越到流水线式自动化,实现素材采集、内容改写、排期调度和自动发布全链路无人值守。教程涵盖 Skill 设计的单一职责原则、Skill 间数据传递规范、错误处理和自动重试机制以及定时触发配置,帮你掌握让 Claude Code 自主运行复杂任务的编排能力。
每周精选 AI 编程与自动化实战内容,直达你的邮箱