Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
什么是 Claude Code 动态工作流?系统拆解三种单窗口失效、六大编排模式和模式选择决策表,让你知道什么时候该用、怎么用、怎么控制成本。

Claude Code 动态工作流(Dynamic Workflows)是 Anthropic 于 2026 年 5 月 28 日发布的一项能力——Claude 不再一个窗口从头干到尾,而是自动把大任务拆成几十甚至上百个小任务,派出一群独立的「小 Claude」同时干活,干完互相检查,最终只把验证过的结论交还给你。这篇文章从「为什么需要」讲到「怎么选模式」,帮你判断什么时候该开、怎么用、怎么控制成本。
要点速览
动态工作流是 Claude Code 在对话之上新增的一层编排能力。Claude 接到你的任务后,不再逐轮问你「下一步做什么」,而是自动规划出一套分工方案,在后台同时执行。方案里定义了谁做什么、按什么顺序、怎么汇总——你的对话窗口保持响应,后台工作流在跑。
💡 通俗讲:想象你以前是一个人加班干所有事,现在你变成了项目经理——写一份任务清单,组一个临时团队,把活分出去,等所有人做完了汇总验收。动态工作流做的就是这件事,只不过「项目经理」和「团队成员」都是 Claude。
核心机制拆开看就三个东西:
和你已经熟悉的子代理(Subagent)相比,区别不在于「能不能并行」,而在于谁持有计划。子代理的计划存在 Claude 的对话记忆里,聊得越长记忆越模糊;动态工作流的计划写在独立的方案里,不管对话多长都不会走样。
动态工作流不是为了让 Claude 更聪明。问题出在对话本身——当任务足够复杂、对话足够长时,单窗口代理有三种结构性的失效方式,靠提示词优化只能缓解、无法根治。
代理惰性(Agentic Laziness)是这样一种现象:Claude 完成了任务的一部分,就宣布「已完成」——但实际上只做了一小部分。
你让它审计 200 个文件的安全漏洞,它认真检查了前 30 个,然后告诉你「审计完成,发现 5 个问题」。不是它偷懒——是对话窗口里堆积了太多中间结果,Claude 对「做完了」和「还没做完」的判断开始模糊。
动态工作流的解法是循环驱动:脚本里写了明确的停止条件(比如「所有 200 个文件都跑过且无新发现」),条件不满足就继续派代理,不存在「提前下班」的可能。
自我偏好偏差(Self-Preferential Bias)指 Claude 倾向于认为自己的产出是正确的。
💡 通俗讲:你让它写一段代码再自己检查,它大概率会说「代码没问题」。这就好比让一个学生批改自己的试卷——同一个大脑出的题,同一个大脑验收,很难发现自己的盲区。
不是它敷衍——同一个对话里,出题和判卷是同一个 Claude,天然看不到自己的盲区。
动态工作流的解法是角色分离:生产者和验证者是不同的子代理,拥有独立的上下文,验证者的唯一目标就是找出生产者的问题。这是架构层面的解决方案,不是靠提示词「请仔细检查」能替代的。
目标漂移(Goal Drift)发生在长对话中。你最开始的需求可能有 20 个细节,经过 30 轮对话后,上下文窗口压缩了早期信息,Claude 只记得最近几轮提到的重点,悄悄偏离了原始目标。
💡 通俗讲:你跟朋友打了一小时电话,开头说的那件事到最后早被岔开了。Claude 的「记忆」也是有限的,聊得越长、早期指令丢失越多。
你让它重构一个模块,中间讨论了几轮设计方案,等它动手改代码的时候,已经忘了最初那三条不能动的约束。
动态工作流的解法是计划固化:需求写死在脚本变量里,不随对话压缩丢失。每个子代理拿到的是完整的、不变形的指令。
🔍 深入一步:这三种失效不是 Claude 的 bug,而是长上下文窗口的必然结果。任何大模型在对话轮次足够多时都会出现类似问题。动态工作流的本质是把「边聊边做」的松散方式,升级为「先定计划再分头执行」的严格方式——牺牲一些灵活性,换来更高的可靠性。
动态工作流的「动态」是相对于静态编排而言的。静态编排是你提前设计好一套固定流程(比如用 n8n 或 Make 搭一条自动化流水线),每次按同样的步骤跑;动态工作流是 Claude 根据任务临场生成编排逻辑,你只需要描述目标。
| 维度 | 动态工作流 | 静态编排 |
|---|---|---|
| 编排逻辑 | Claude 临场生成,每次可能不同 | 你提前写好,每次相同 |
| 适用场景 | 任务结构不确定、需要 Claude 判断如何拆解 | 任务结构固定、流程已验证 |
| 定制程度 | 依赖 Claude 的理解能力 | 完全由你掌控每个步骤 |
| token 消耗 | 较高(分工方案生成 + 多个子任务并行) | 可预测,通常更低 |
| 复用性 | 可保存为命令,但每次执行可能微调 | 确定性重复执行 |
| 调试难度 | 中等(脚本可读但自动生成) | 低(你自己写的,你自己懂) |
| 错误恢复 | 支持中断恢复,断了能接着跑 | 取决于你自己的实现 |
| 安全边界 | 子代理继承主会话权限,需手动确认文件操作 | 完全由你的代码控制 |
选择标准很简单:
⚠️ 常见踩坑:不是所有任务都需要工作流。一个能在单轮对话里解决的问题,开工作流反而更慢、更贵。判断标准是:这个任务是否需要多个独立视角或并行处理大量子任务?如果两者都不需要,直接在对话里做就好。
🔍 深入一步:我自己在知识库里运行了数十个 Agent 工作流之后的一个体会——动态工作流最大的价值不在于「并行加速」,而在于「角色隔离」。单窗口里让 Claude 先写再审,它审不出自己的问题;拆成两个独立子代理(一个写、一个审),找出的问题数量翻了几倍。如果你只打算记住一件事,记住这个:生产和验证分开做,比一个人从头做到尾靠谱得多。
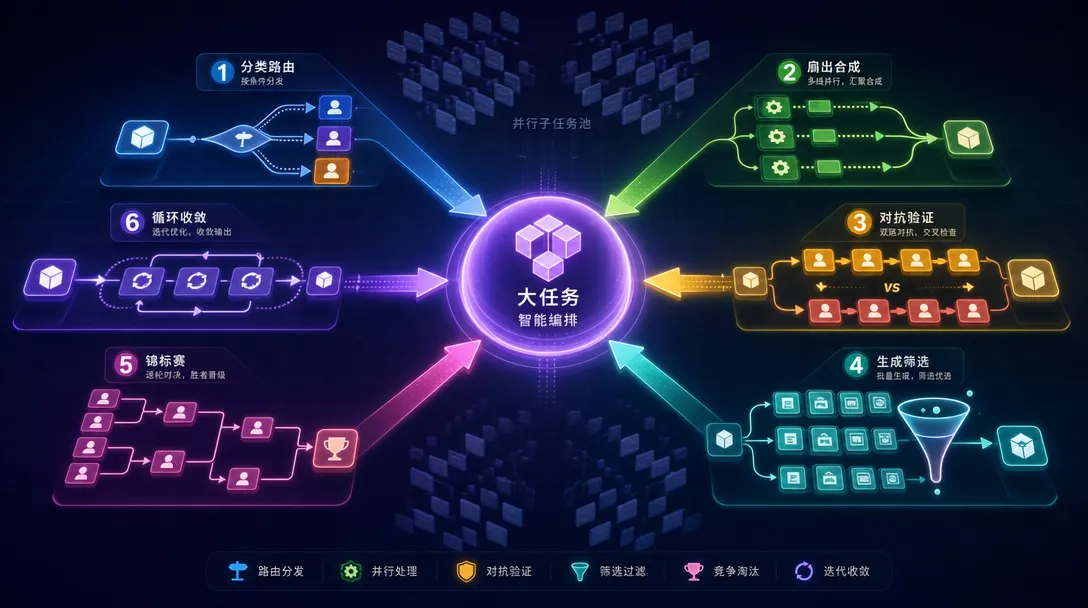
Anthropic 在官方博文「A Harness for Every Task」中定义了六种可组合的编排模式。这不是随意分类——每种模式解决的问题不一样,选错模式不如不选。
分类路由(Classify-and-Act)是最简单的模式:一个分类器代理读取任务,判定类型,把不同类型路由到对应的专家代理。
典型场景:客户工单进来了,先判断是技术问题、账单问题还是功能建议,然后分发给不同的处理流程。代码场景里,先判断一个 bug 报告是前端问题、后端问题还是数据库问题,再分配给对应的修复代理。
这个模式的关键在于分类器的准确性。分类错了,后面所有工作都白做。实操建议:在提示词里穷举所有可能的类别并附带一两个示例,让分类器的判断边界尽可能清晰。
扇出合成(Fan-Out-and-Synthesize)是使用最广泛的模式:把大任务拆成多个互不依赖的小任务,每个分配一个独立代理并行执行,全部完成后统一合并结果。
典型场景:审计 200 个文件的安全漏洞——每个文件分配一个代理,200 个代理同时跑,跑完后汇总所有发现。大规模代码迁移——每个模块分配一个代理独立迁移,最后合并。
这个模式的效率优势是并行带来的时间压缩。200 个文件串行审计可能要几个小时,并行只需要最慢那一个文件的时间加上结果合并的开销。实操要点:子任务之间必须完全独立——如果 A 文件的审计结果依赖 B 文件的结构,就不能用纯扇出,要先做依赖分析再决定分组。
对抗验证(Adversarial Verification)是动态工作流最有特色的模式:为每个生产代理配一个验证代理,验证者的唯一目标是按预设标准反驳生产者的结论。只有验证者无法推翻的结论才进入最终报告。
这个模式直接解决自我偏好偏差的问题。生产者和验证者拥有独立上下文,验证者看不到生产者的推理过程,只看到结果——相当于给每一份产出安排了一个专职的「挑刺者」。
典型场景:深度调研中验证一条论断是否有可靠来源支撑,代码审计中确认一个安全发现是否是真实漏洞而非误报。
生成筛选(Generate-and-Filter)适合「先发散后收敛」的场景:批量生成候选方案,再用明确的标准或测试逻辑筛选,去重后保留最优候选。
典型场景:为一个函数生成 10 种不同实现,然后跑测试看哪种性能最好。为一篇文章生成 20 个标题候选,再按点击率预测模型筛选。
和锦标赛模式的区别在于:生成筛选用客观标准筛(测试通过率、性能指标、代码行数),锦标赛用主观比较选(可读性、设计美感、用户体验)。如果筛选标准能量化(比如测试通过率、响应速度),用生成筛选;如果必须凭判断力(比如哪个设计更好看),用锦标赛。
锦标赛(Tournament)模式让 N 个代理用不同方法解决同一个问题,然后由评判代理进行两两对比,淘汰到最后一个胜出。
两两比较(「A 比 B 好在哪」)比绝对打分(「给 A 打个分」)更可靠——这一点在大模型评估领域已经被反复验证。锦标赛模式把这个认知内化到了工作流编排中。
典型场景:多种重构方案的最终选择、文案风格的 A/B 测试、设计方案的评审。凡是需要主观判断优劣的场景,锦标赛比直接让 Claude 打分更稳。
循环收敛(Loop-Until-Done)是一个开放式的发现模式:持续派代理探索,直到满足停止条件(连续两轮无新发现、剩余错误归零、覆盖率达标等)。
典型场景:代码库里的编译错误修复——修一个可能暴露两个新的,一直修到全部通过。开放式搜索——不断扩展搜索角度,直到搜不出新东西为止。
这个模式的风险是失控:如果停止条件设得不好,它会一直跑下去烧 token。设计停止条件是用好循环收敛的关键——推荐至少设两道保险:一个业务条件(如「连续两轮无新发现」)加一个硬上限(如「最多迭代 10 轮」)。
🔍 深入一步:真实工作流往往不是单一模式,而是多模式叠加。Bun 重写案例就同时用了分类路由(做生命周期映射)、扇出合成加对抗验证(做并行移植)、循环收敛(做修复迭代)。选模式不是单选题,是组合拳。
知道了六种模式,下一个问题是:我手上的任务该用哪种?
| 任务特征 | 推荐模式 | 注意事项 |
|---|---|---|
| 任务可以明确分类、不同类型走不同处理流程 | 分类路由 | 分类器的准确性决定了后续所有工作的质量 |
| 大量相同结构的子任务可以并行 | 扇出合成 | 子任务之间不能有依赖,有依赖要先拆解 |
| 产出需要严格的正确性保证 | 对抗验证 | 验证代理会增加约一倍的 token 消耗 |
| 需要探索多种可能方案再选最优 | 生成筛选 | 必须有客观可衡量的筛选标准 |
| 方案之间的优劣需要主观判断 | 锦标赛 | 评判标准要提前在提示词中写清楚 |
| 不知道要做多少轮才能做完 | 循环收敛 | 必须设计好停止条件,防止无限循环 |
| 任务兼具拆分、验证和迭代需求 | 多模式组合 | 先确定主干模式,再在关键节点叠加 |
| 单轮对话就能解决 | 不需要工作流 | 杀鸡用牛刀,反而更慢更贵 |
一个简单的判断公式:任务需要 ≥ 3 个独立子任务并行处理,或者产出需要独立验证 → 用工作流。否则直接对话解决。
实操诀窍:拿到一个任务后先自问三个问题——① 这个任务能拆成互不依赖的子任务吗?② 产出是否需要交叉验证或多角度对比?③ 做完预计超过 15 轮对话吗?三个问题里有两个答「是」,就值得开工作流。
知道了六种模式和决策方法,下一步是动手。以下提示词可以直接复制到 Claude Code 中使用——在 ultracode 模式下效果最佳:
深度调研
使用工作流,对「{你的主题}」做深度调研。从至少 5 个独立来源采集信息,交叉验证每条关键论断,最后汇总成一份带来源引用的报告。
全库安全审计
使用工作流,扫描整个项目的安全漏洞。每个文件独立检查,对每个发现都做对抗验证,确认是真实问题后再进入报告。
商业计划压力测试
读我的商业计划书,然后用工作流从投资人视角、客户视角和竞争对手视角分别拆解它。每个视角独立分析,最终汇总出三个视角的核心质疑。
简历筛选
这个文件夹有 50 份简历。使用工作流,按以下标准排序:{你的标准}。先做初筛,对 Top 10 做交叉验证,最终给出排名和理由。
CLAUDE.md 规则挖掘
使用工作流,翻阅我最近 30 个对话记录,找出我反复纠正 Claude 的地方,把重复出现的纠正归类,转化成 CLAUDE.md 规则。
这些提示词的共同特点:描述目标和约束,不指定实现方式。Claude 会自行判断用哪种编排模式、派多少子代理、怎么验证结果。你控制的是「做什么」和「做到什么标准」,不是「怎么做」。
动态工作流的能力边界比你想的宽。以下十个场景按 Anthropic 官方文档和早期用户反馈整理(来源:Anthropic 官方博客),覆盖代码和非代码两大类。
你想搞清楚一个话题但信息分散在几十个网页里——让 Claude 分头搜索、交叉验证、汇总成一份报告。
需要从大量来源中提取、交叉验证、汇总信息的调研任务。Claude Code 内置的 /deep-research 命令就是这个场景的标准实现。
适用模式:扇出合成 + 对抗验证 + 循环收敛。
试试这样说:对「{话题}」做深度调研,从中英文至少 8 个独立来源采集,交叉验证每条论断,汇总成一份 3000 字的带引用报告。
你写了一篇文章或报告,想确认里面的每个数字和引用都是对的——让 Claude 逐条查证。
验证一篇报告、一份文档中的所有事实性声明。每条声明分配一个代理去查证,查不到来源的标记为存疑。
适用模式:扇出合成 + 对抗验证。
试试这样说:使用工作流,验证这份文档中的每一条事实性声明。每条声明独立查证,找不到一手来源的标记为存疑。
你面前有一堆待处理的东西(邮件、工单、文件),想按类型分类后分别处理。
一次性处理大量待处理项(工单、告警、代码审查请求),先分类,再按类型走不同处理流程。
适用模式:分类路由 + 扇出合成。
试试这样说:使用工作流,处理这批 200 个待办项。先按类型分类,再按优先级排序,对高优先级项尝试直接解决,解决不了的整理好上下文交给我。
你不确定哪种方案最好,想先广泛探索几种再选——比如文章标题怎么起、产品命名怎么选。
你不确定最优方案是什么,需要先广泛探索再收敛。比如为一个新功能设计多种 UX 方案,或者探索一个问题的多种解法。
适用模式:生成筛选 / 锦标赛。
试试这样说:使用工作流,为这个功能探索 5 种不同的实现方案,每种方案独立开发,然后做两两对比选出最优方案。
你有一批候选方案需要排个优劣,但标准比较主观——让多个 Claude 两两对比投票选出最优。
需要对一组方案、候选人或产出进行排序,但排序标准是主观的。让评判代理两两对比,比绝对打分更可靠。
适用模式:锦标赛。
试试这样说:使用工作流,对这 10 个方案做锦标赛评选。每两个方案对比一次,最终选出 Top 3 并说明理由。
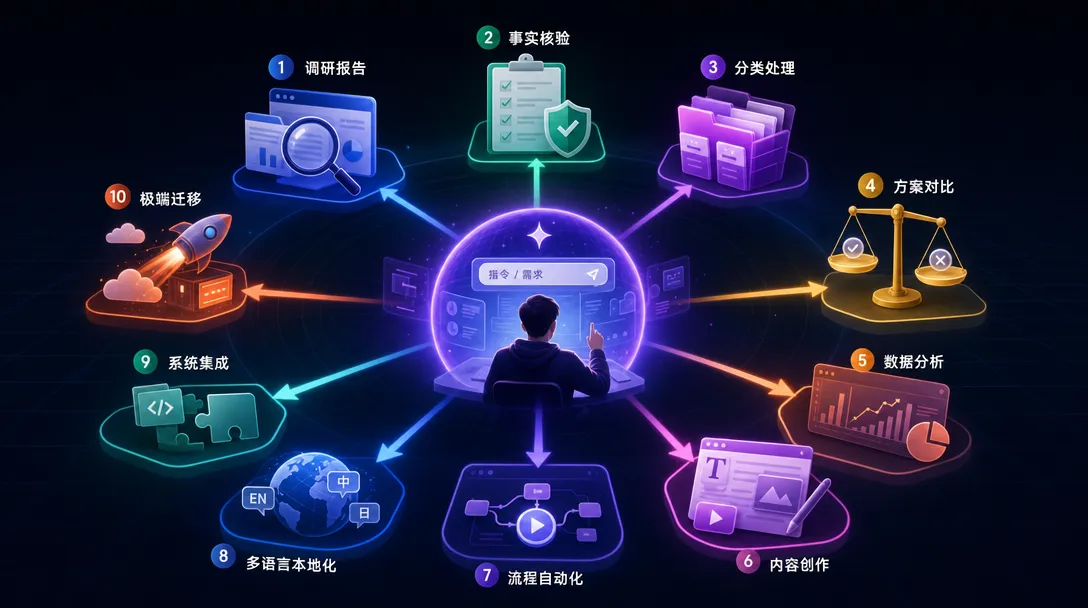
出了问题但不知道根本原因在哪——让多个 Claude 分别从不同角度调查,然后交叉比对。
面对一个复杂的 bug 或系统故障,让多个代理从不同角度分析根因——有的看日志,有的看代码变更,有的看性能指标——然后汇总交叉比对。
适用模式:扇出合成 + 对抗验证。
试试这样说:使用工作流,分析这个 bug 的根本原因。分别从日志、代码变更历史和性能指标三个角度独立调查,最后交叉比对三方结论。
你有一套标准想确认是否被遵守——或者想从历史对话中挖出自己反复纠正的模式。
检查代码库是否遵守特定的规则集(安全策略、编码规范、合规要求)。每条规则分配一个代理全库扫描。
适用模式:扇出合成。
试试这样说:使用工作流,检查这个项目是否遵守 CLAUDE.md 中的所有规则。每条规则独立扫描全库,违反的给出具体位置和修复建议。
你想对一个系统或项目做全面体检,发现问题后立即修,修完再检查,循环到全部通过。
对已有系统做性能评估、安全审计或质量审核,发现问题后立即修复,修完再验证,直到通过所有检查。
适用模式:扇出合成 + 循环收敛。
试试这样说:使用工作流,对这个项目做全面质量审计。发现问题后立即修复,修完再验证,循环直到所有检查通过。
你需要对大量文件做同一类修改——比如统一格式、替换写法、升级框架。
把整个代码库从一个框架迁移到另一个框架——每个文件或模块分配一个代理独立迁移,同时配验证代理确保行为一致。Bun 从 Zig 迁到 Rust 的案例就是这个场景的极端版本。
适用模式:扇出合成 + 对抗验证。
试试这样说:使用工作流,把项目中所有 CommonJS 的 require 改成 ESM 的 import。每个文件独立处理,改完跑一遍测试确认没坏。
工作流中有的子任务简单有的复杂——让 Claude 自动给简单任务用快模型、复杂任务用强模型,省钱不降质。
工作流中不是每个子任务都需要最强的模型。简单分类用快模型,复杂推理用强模型——脚本可以为每个子代理指定不同的模型,在质量和成本之间做动态平衡。
适用模式:分类路由(按复杂度路由到不同模型)。
试试这样说:使用工作流处理这批任务。简单的分类和格式化用快模型,需要深度推理的用强模型,帮我在质量和成本之间找到平衡。
⚠️ 实操提醒:以上十个场景都可以用一句自然语言触发。你不需要告诉 Claude 用哪种模式——只需要在 ultracode 模式下描述你的任务,Claude 会自行选择合适的编排方式。模式名称是帮你理解和调试用的,不是你必须手动指定的参数。
ultracode 是动态工作流的最高档位。它做了两件事:把 Claude 的思考深度调到最高,同时启用自动工作流编排——Claude 自主判断每个任务是否需要启动工作流。
三种触发方式,按使用频率排:
/effort ultracode,当前会话进入 ultracode 模式。ultracode 这个词,或自然语言请求如「use a workflow」「run a workflow」。/deep-research <你的问题>,这会触发预定义的深度调研工作流。ultracode 仅在当前会话生效,新会话自动重置。回到日常工作用 /effort high 切回。
第一次尝试的推荐路径:如果你从未用过动态工作流,建议按这个顺序体验——先跑一次 /deep-research "你感兴趣的技术话题",感受工作流自动编排的过程;然后在一个小项目上试 /effort ultracode + 一句自然语言指令(比如「审计 src/ 目录下所有文件的错误处理」);最后再尝试在提示词里指定具体模式(比如「用扇出合成模式并行审计」)。
这是进阶用户最关心的问题。没有内置的消费上限——一个复杂任务在 ultracode 模式下可能消耗的 token 远超你的预期。
实用的成本控制手段:
/workflows 视图实时查看每个代理的 token 消耗,发现跑偏随时停止。/model 确认当前使用的模型,考虑把不需要最强模型的子任务路由到更便宜的模型。/effort high 就够了,只在需要多代理深度编排的高价值任务上开 ultracode。/cost,记录实际 token 消耗和耗时,为下次同类任务提供预算参考。动态工作流有几个内置的安全限制:一次运行最多调度 1,000 个子代理,同时跑的不超过 16 个(来源:Claude Code 官方文档)。运行期间你不能追加指令,只能在需要确认权限时暂停。这些限制是为了防止任务失控——你不需要记住这些数字,Claude 会自动遵守。
⚠️ 常见踩坑:ultracode 不等于一定更好。如果你的任务不需要并行处理或交叉验证,ultracode 只会增加 token 消耗而不提升结果质量。一个判断标准:如果
/effort high已经能给出满意结果,就没必要升级到 ultracode。

当一个工作流跑出了满意的结果,你不需要每次重新触发。Claude Code 提供了保存和复用机制。
保存:运行 /workflows,在工作流列表中选中目标运行,按 s 键保存。你可以选择两个保存位置:
.claude/workflows/:项目级,任何克隆这个项目的人都能用。~/.claude/workflows/:个人级,你的所有项目都能用。保存后的工作流以 /<名称> 形式出现在斜杠命令的自动补全中,像内置命令一样使用。
分享:保存到 .claude/workflows/ 并提交到 Git,团队成员克隆仓库后就自动拥有了这个工作流。不需要额外配置。
配合 [/loop](https://xiangyugongzuoliu.com/loop-engineering-guide/) 和 /goal 做持续任务:/loop 让 Claude 自动循环执行直到达标,/goal 设定明确的验收目标。三者配合使用的场景:用 /goal 定义「所有测试通过」,用 ultracode 启用工作流编排,用 /loop 让它持续修复直到目标达成。这套组合拳在大规模代码重构中效果尤其明显——人类定义目标和边界,Claude 自己想办法达标。
🔍 深入一步:保存后的工作流可以接受不同的输入参数。比如你保存了一个「审计安全漏洞」的工作流,下次可以对不同的项目直接复用,不需要重新描述任务。
假设你想搞清楚「2026 年有哪些值得关注的 AI 编程工具」这个话题。不用动态工作流,你大概需要:自己搜索 → 逐个打开链接 → 读文章 → 做笔记 → 交叉验证 → 整理报告,全程至少一两个小时。
用动态工作流,你只需要说一句话:
使用工作流,对「2026 年值得关注的 AI 编程工具」做深度调研。从至少 8 个独立来源采集信息,交叉验证每条关键论断,最后汇总成一份带来源引用的报告。
Claude 会自动拆任务:几个子代理分头去不同渠道搜索,另外几个专门验证前一批找到的信息是否可靠,最后一个负责把所有发现整理成一份有来源、有引用、经过交叉验证的报告。整个过程大约 10 分钟。
这就是动态工作流最直接的价值:你描述你要什么,Claude 自己想怎么组织团队去做。
动态工作流的天花板有多高?Bun(一个 JavaScript 运行时工具)的创始人 Jarred Sumner 用动态工作流把 Bun 的核心引擎从一种编程语言迁移到另一种,产出约 75 万行代码,从开始到合并只用了 11 天(引述自 Anthropic 官方博文,该项目尚未投入生产)。
这个案例的意义不在数字本身,而在于验证了一种新的工作模式:人定目标和边界,AI 编排团队并行执行,人做最终审查。Jarred 白天审查前一晚工作流的产出,晚上启动下一批工作流。
不过需要注意:Jarred 本人有深厚的编译器开发经验,这个速度不代表一般用户的预期。把它当作「动态工作流能做到多大规模」的参考就好。
动态工作流和子代理有什么区别?
子代理是被派出去执行具体任务的独立 Claude 实例,由 Claude 在对话中逐轮判断是否需要派生。动态工作流是一段 JavaScript 编排脚本,由独立运行时执行,可一次调度数十到上千个子代理并行工作。区别在于谁持有计划:子代理的计划在上下文窗口里,工作流的计划在脚本里。
Pro 计划能用动态工作流吗?
能用。Pro 计划默认关闭,需要在 /config 中手动开启 Dynamic workflows。Max 和 Team 计划默认开启。Enterprise 计划需管理员在 Claude Code 管理后台 启用。版本要求 Claude Code v2.1.154 或更高。
ultracode 会消耗多少 token?
取决于任务复杂度和代理数量。社区有用户反馈在几分钟内消耗超过 170 万 token(来源:Reddit r/ClaudeAI)。建议先在小范围试跑,用提示词显式设定 token 预算,避免失控。
工作流中断了怎么办?
动态工作流支持中断恢复。运行进度保存到磁盘,下次启动时自动从断点续跑,已完成的子代理结果不会丢失(来源:Claude Code 文档)。
一个工作流最多能跑多少个子代理?
单次运行最多 1,000 个子代理,并发上限 16 个(CPU 核心数较少的机器会相应减少)。这两个限制由运行时强制执行,防止脚本失控。
动态工作流能用在非代码任务上吗?
完全可以。深度调研、事实核验、投资分析、简历筛选、商业计划压力测试都是典型的非代码场景。核心判断标准:任务能否被拆解为多个可并行的子任务,以及产出是否需要独立验证。
六大编排模式能混合使用吗?
可以,而且真实工作流往往是多模式叠加。Bun 重写案例就同时用了分类路由、扇出合成加对抗验证、循环收敛三种模式。选模式不是单选题,是看任务的不同阶段需要什么能力。
怎么把跑好的工作流保存下来复用?
运行 /workflows,选中目标运行后按 s 键保存。可以选择保存到 .claude/workflows/(项目级,团队共享)或 ~/.claude/workflows/(个人级,跨项目可用)。保存后以斜杠命令形式出现在自动补全中。
怎么关闭动态工作流?
个人用户在 /config 中关闭 Dynamic workflows,或在 ~/.claude/settings.json 中设置 "disableWorkflows": true。也可以用环境变量 CLAUDE_CODE_DISABLE_WORKFLOWS=1。组织级在托管设置或管理后台关闭。
API 和云端部署(Bedrock / Vertex AI)支持动态工作流吗?
支持。API、Amazon Bedrock、Google Vertex AI、Foundry 上的动态工作流默认开启,直接使用即可。
动态工作流是我用过的 Claude Code 功能里,设计理念最清晰的一个——不是在已有能力上堆参数,而是从架构层面解决了一个用提示词补不了的问题:单窗口代理在复杂任务上的结构性失效。
我的判断是:动态工作流改变的不是 Claude 的智力水平,而是协作结构。我在自己的知识库项目中实际体验过——同一个任务,单窗口跑到第 20 轮开始丢细节,拆成工作流后 50 个子代理各管各的、互相审查,产出质量明显不同。但它不是万能方案。简单任务不需要它,成本敏感的场景需要谨慎控制 token 消耗,Bun 级别的大规模案例目前还缺少生产环境的完整验证。
如果你已经在用 Claude Code,我建议从 /deep-research 开始感受工作流的运作方式,再在一个你自己的调研或审计任务上试 ultracode 模式。把上面的提示词范例复制过去,亲手体验一次「描述目标 → Claude 自动编排 → 多代理并行 → 汇总验证」的完整过程,比读十篇文章都管用。
动态工作流是 Claude Code 最新的编排能力。如果你想从基础开始系统学习 Claude Code 的全部功能——从安装配置到提示词工程,从 Skill 开发到多代理协作——翔宇的 AI 编程实操课从入门到进阶都有覆盖。

AI 编程实操课:Claude Code + Codex + Agent 工作流,覆盖一人公司、自媒体自动化、AI 副业全场景。实战教程 + 最佳实践 + 源码包,跟着做就出成果。国内版-FlowUS | 国际版-BMC
国内版和国际版内容完全相同,根据你的支付渠道自行选择即可。
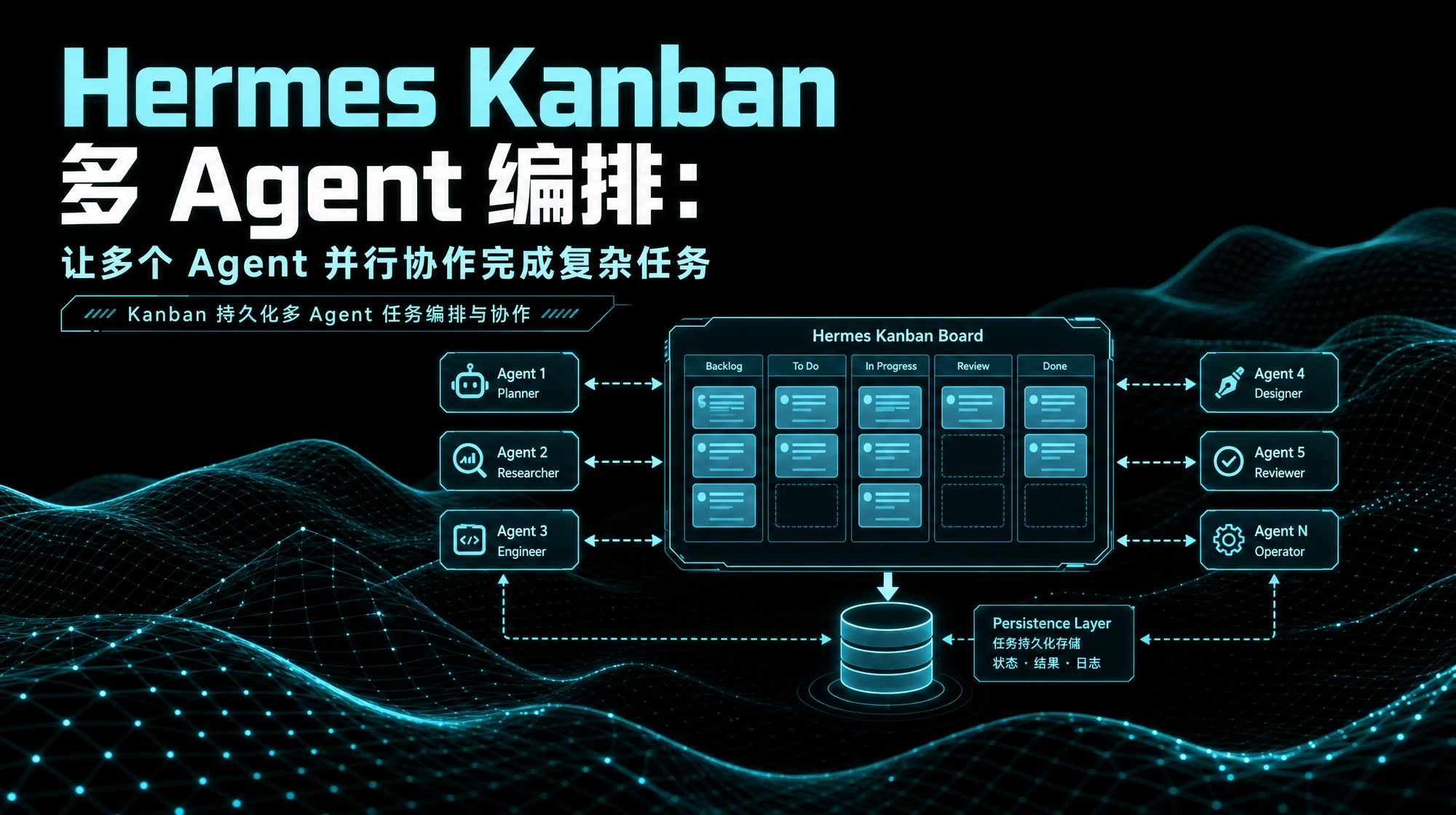
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
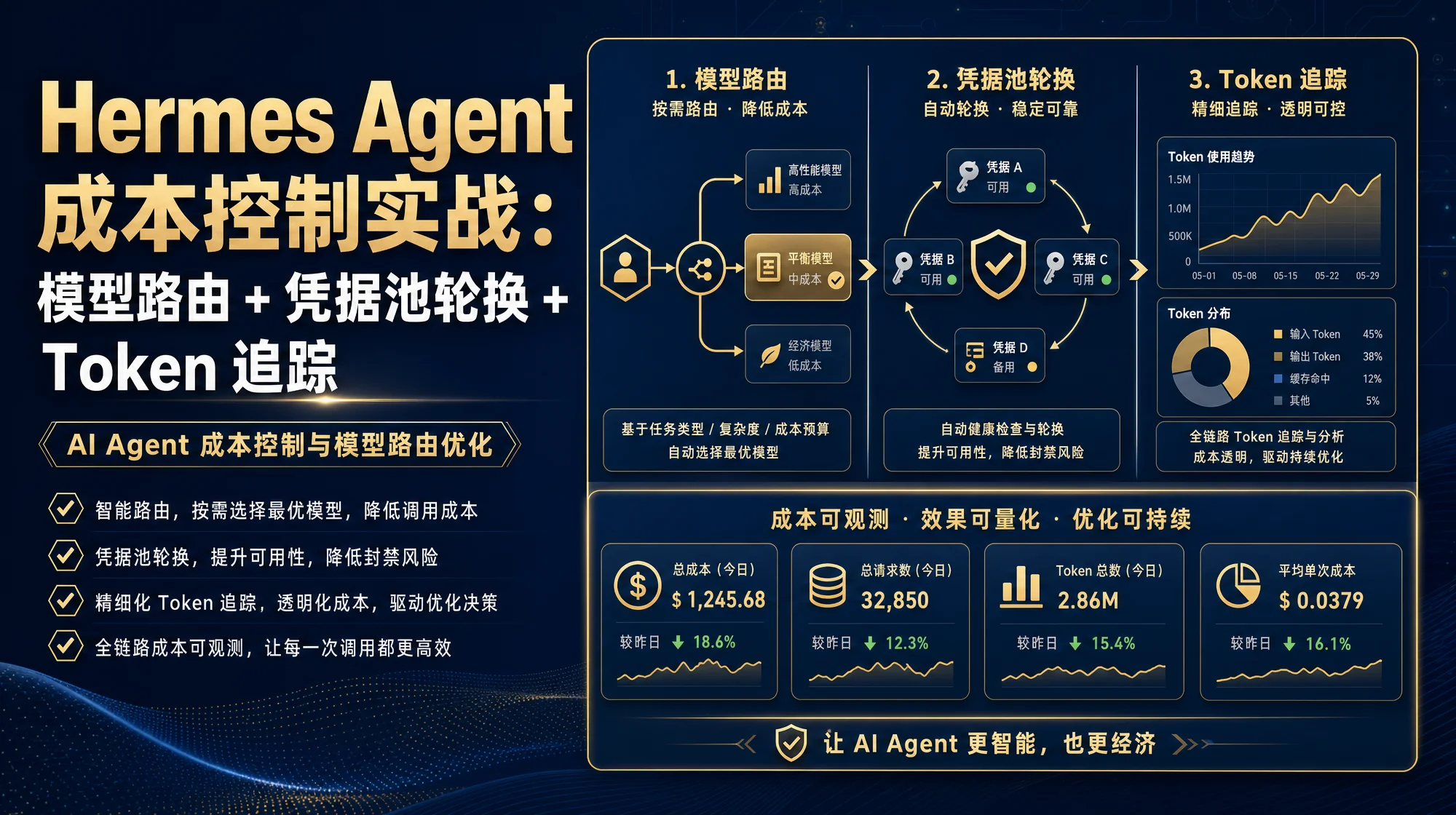
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
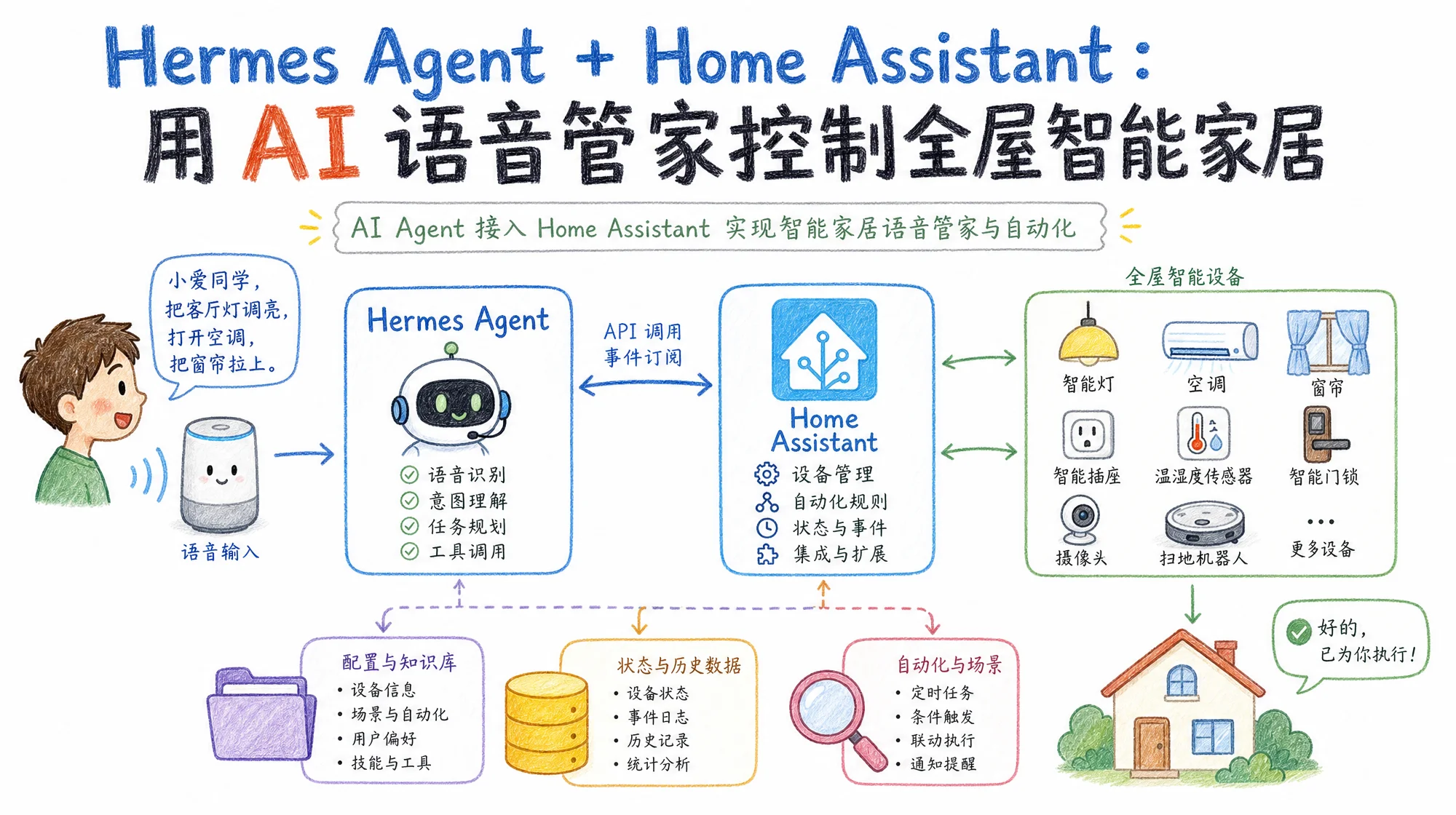
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 支持三种本地推理后端:Ollama 一键启动、LM Studio 可视化管理、vLLM 生产级吞吐。本文覆盖完整接入配置、64K 上下文铁律、模型选型矩阵(按硬件/任务/语言推荐)、社区高频痛点解决方案,以及翔宇 GLM→DeepSeek→Gemini 三模型实战策略。
每周精选 AI 编程与自动化实战内容,直达你的邮箱