Hermes Skill 自我进化系统:让 AI 助手越用越聪明
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。
这篇以开源项目 workflow-agent-skill-spec 为主线,拆解如何把 Claude Code Skill 做成可触发、可恢复、可测试、可审计的工作流。

这是官网精华版。公众号原文是一篇 3 万字长文,完整展开了 18 章和 5 大模块;这篇先把最关键的架构、规范和实战路径压缩成一篇可读版本。配套开源项目已经整理到 GitHub:https://github.com/xiangyugongzuoliu/workflow-agent-skill-spec。
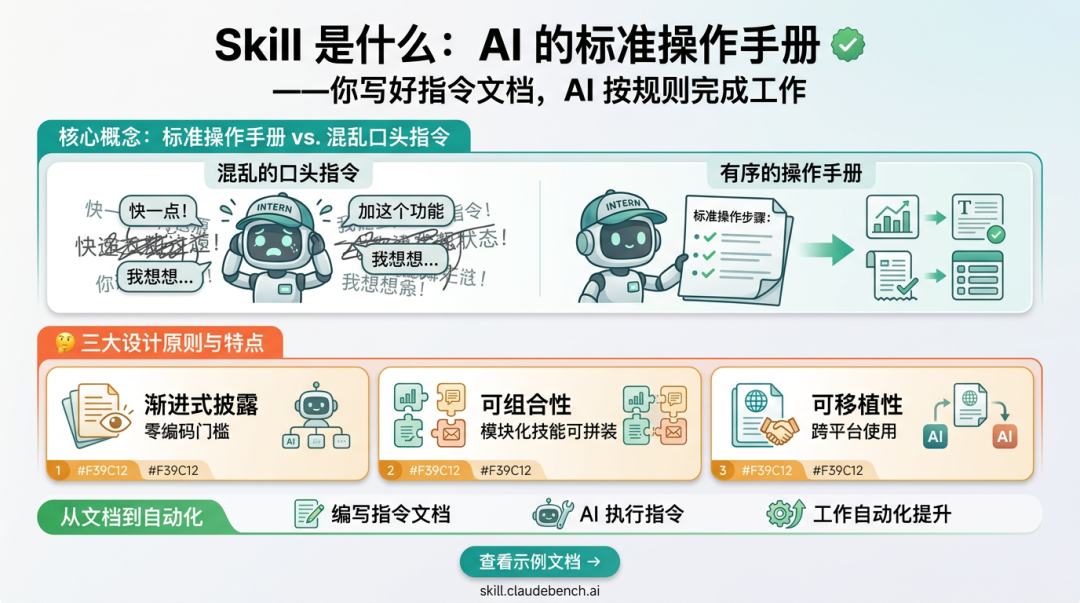
很多人用 Claude Code,是把它当聊天窗口。
输入一段话,等它给一段回复。效果好就惊喜,效果差就觉得模型不行。
但真正能把 AI 用出生产力的人,想的不是「怎么问一句」,而是「怎么让 AI 按我的标准、我的流程、我的节奏稳定交付」。
这就是 Skill 的价值。
Skill 不是一个神秘插件。它本质上是一份给 AI 的标准操作手册:告诉 Claude Code 什么时候触发、按什么步骤执行、读哪些文件、调用哪些脚本、结果放在哪里、失败了怎么恢复。
这篇文章对应的是我开源的 Workflow Agent Skill 规范:
docs/、templates/、schemas/、evals/、scripts/validate-spec.py。如果你只是想理解 Skill 的设计方法,先读这篇文章。如果你想让 Agent 直接按规范帮你新建、审查或升级 Skill,就把 GitHub 仓库交给它。
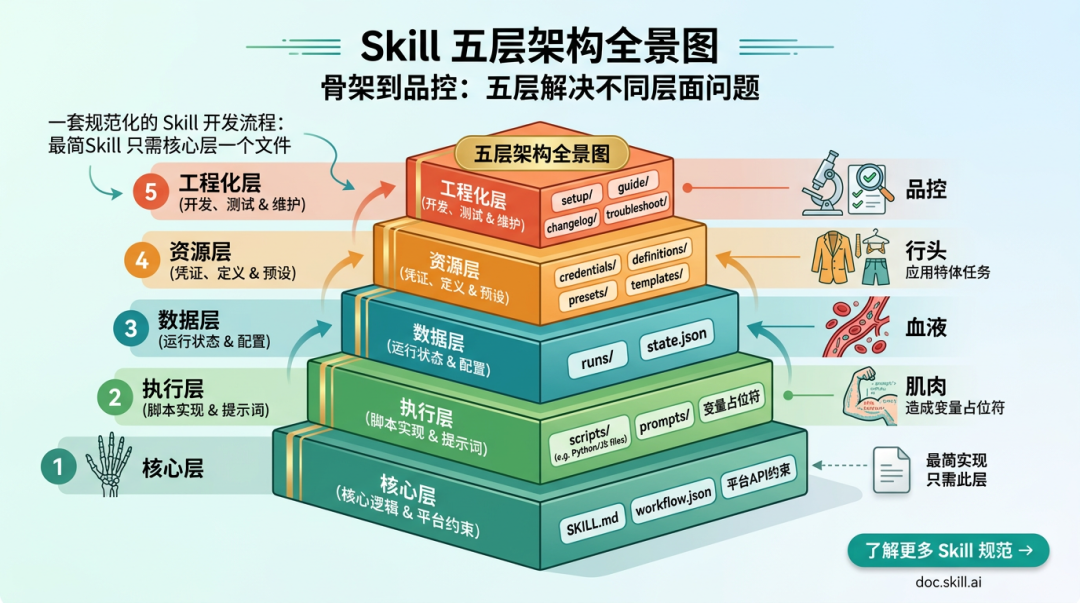
我把生产级 Skill 拆成五层。
第一层是核心层:SKILL.md、工作流表格、平台约束。它定义这个 Skill 是什么,什么时候触发,执行几步。
第二层是执行层:scripts/、prompts/、变量占位符。脚本负责确定性体力活,Prompt 负责需要判断的脑力活。
第三层是数据层:runs/、state/、config/、params.schema.json。它决定每次运行的数据往哪放,进度怎么记录,断点怎么恢复。
第四层是资源层:credentials/、definitions/、presets/、templates/。它负责凭证、常量、预设和输出模板,让 Skill 更安全、更可配置。
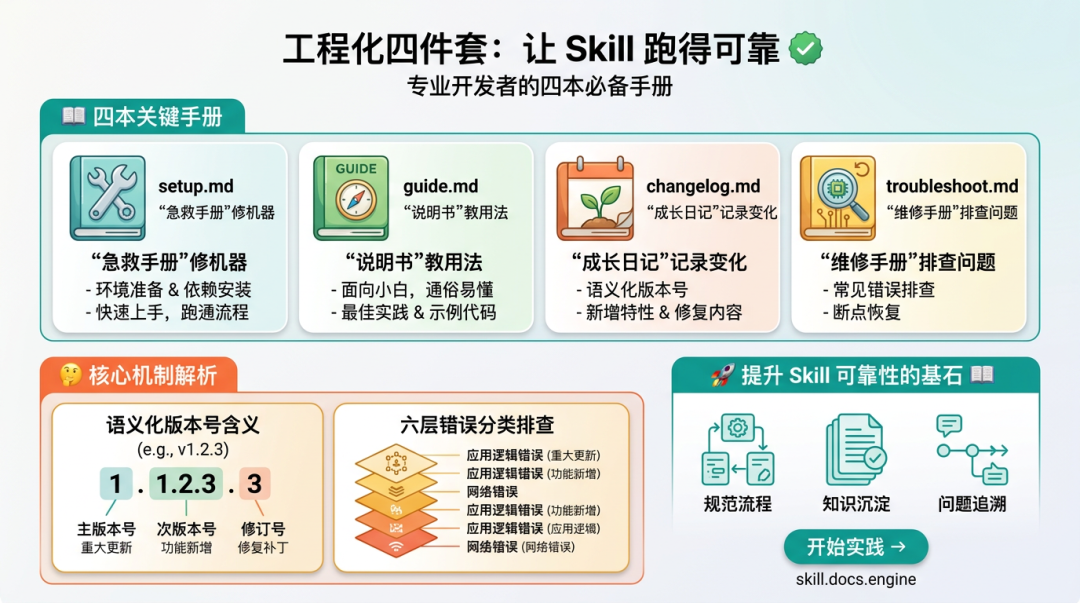
第五层是工程化层:setup.md、guide.md、changelog.md、troubleshoot.md。它让别人能安装、能理解、能维护、能排错。
最小可用 Skill 只需要第一层。真正稳定复用的 Skill,通常会慢慢长出后面四层。
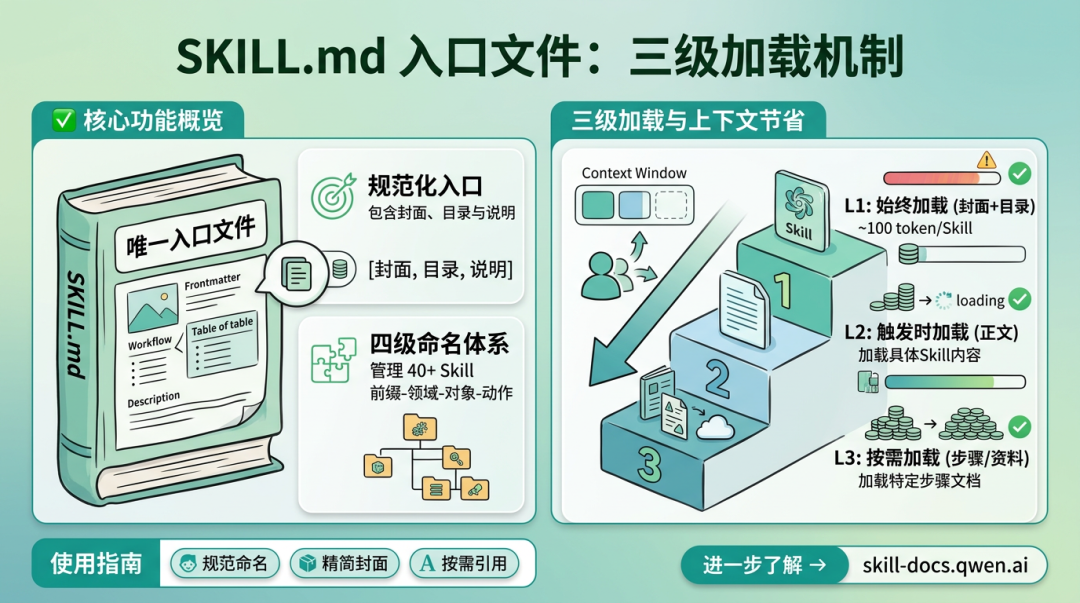
一个 Skill 的入口永远是 SKILL.md。
你可以把它理解成一本书的封面和目录。封面告诉系统「我叫什么、我能做什么」,目录告诉 Claude Code「按什么顺序执行」。
最小结构是这样:
my-first-skill/
└── SKILL.md
更完整一点,会变成:
my-first-skill/
├── SKILL.md
└── workflow/
├── step01-init.md
├── step02-process.md
└── step03-output.md
SKILL.md 的 frontmatter 至少要写两个字段:name 和 description。
name 用小写字母和连字符,方便系统识别。description 要写清楚功能和触发条件,而且尽量用第三人称,不要写「我可以帮你」这种对话式句子。
真正重要的是工作流表格。它要讲清楚每一步的职责、执行者、文档、输入和输出。
一个好 Skill,不是把所有事情都塞给 Claude Code 临场发挥,而是把流程拆成清楚的任务单元:第一步初始化,第二步采集,第三步分析,第四步输出。
Skill 开发里最容易踩坑的是:什么都让 Claude Code 直接想。
我的原则很简单:确定性的事情交给脚本,需要判断的事情交给模型。
比如批量重命名、读取 JSON、合并 CSV、下载图片、校验文件结构,这些都应该放进脚本。脚本稳定、便宜、不会消耗大量上下文。
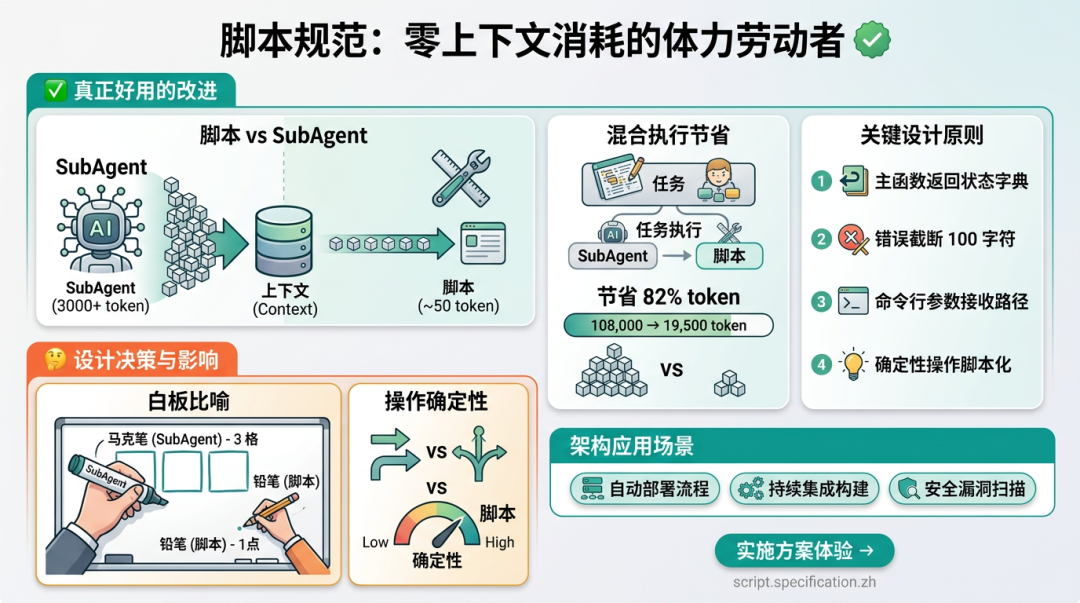
比如判断标题是否吸引人、分析用户痛点、选择写作角度、诊断内容质量,这些才适合交给 Claude。
Prompt 模板也要标准化。一个生产级 Prompt 至少要包含六件事:
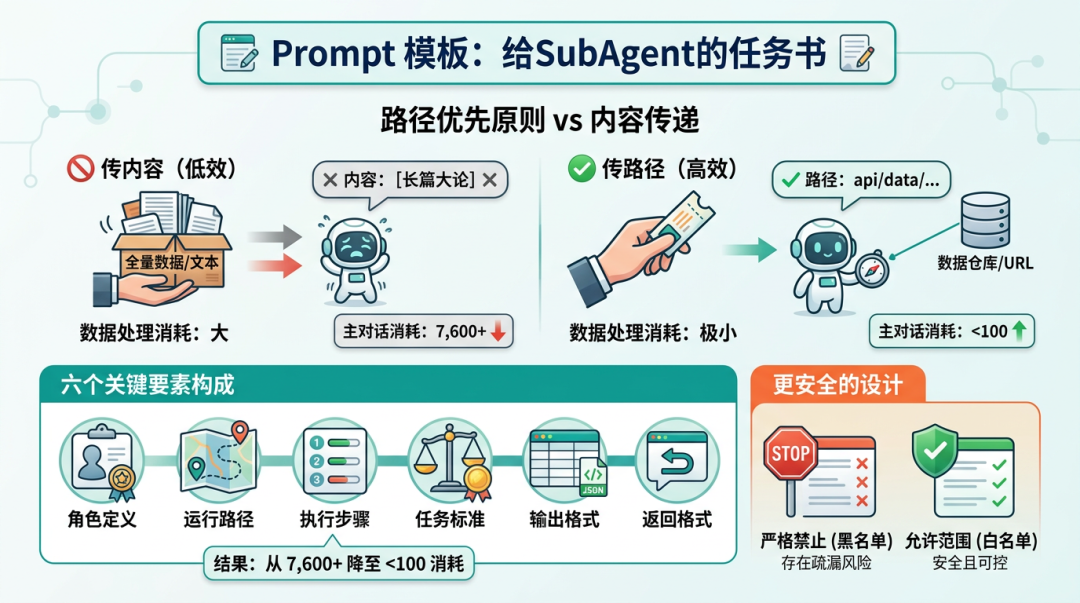
变量占位符负责把这些部分串起来。比如 {input_path}、{run_dir}、{output_path}。不要让 Agent 自己猜路径,路径要从状态文件或参数里明确传递。
复杂 Skill 最怕的不是失败,而是跑到一半不知道发生了什么。
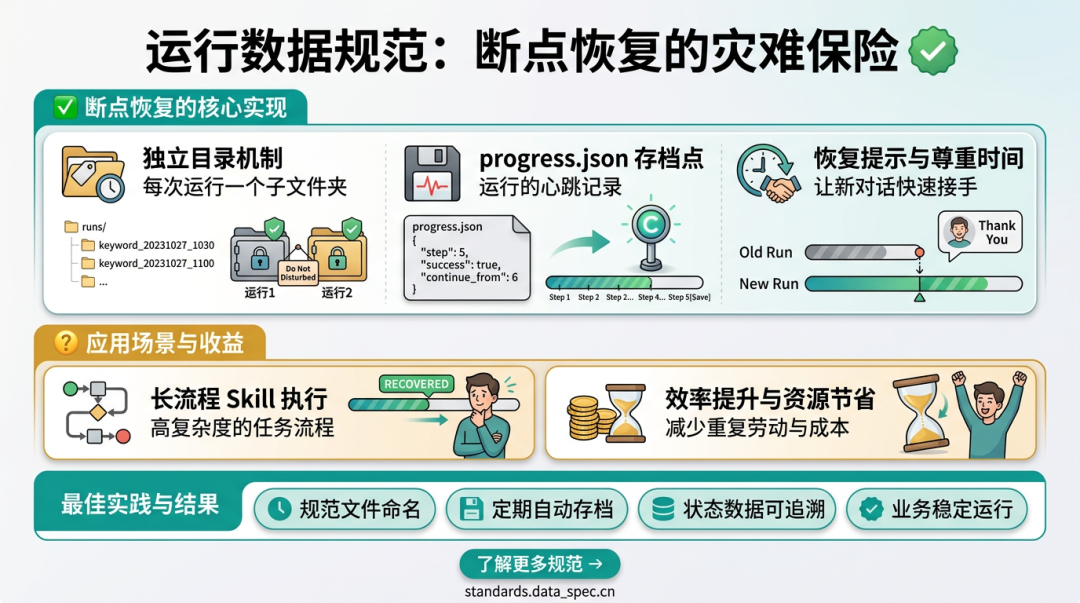
所以每次运行都应该有独立运行目录:
runs/
└── article-20260430-130000/
├── state/
│ └── progress.json
├── output/
└── logs/
progress.json 是心跳。它至少要记录当前步骤、输入路径、输出路径、状态、错误信息和时间戳。
这样上下文被压缩、会话中断、任务失败之后,Agent 仍然能通过状态文件知道:做到哪一步了,下一步该干什么,是否可以恢复。
配置也要分层。
交互参数是这一次运行用户临时给的,比如主题、平台、风格。默认配置是 Skill 自带的稳定参数,比如输出目录、模型偏好。预设配置是可复用选项,比如「公众号风格」「小红书风格」「专业报告风格」。
这三层不要混在一起。混在一起,后面维护一定会乱。
资源层解决的是「别把隐性规则散落到各处」。
凭证放 credentials/,并且真实密钥不能进 Git。常量放 definitions/,比如平台枚举、评分项、字段名。用户可选项放 presets/,比如风格、模板、输出尺寸。HTML 或 Markdown 输出样式放 templates/。
为什么要这么麻烦?
因为魔法字符串会杀死可维护性。
你在 8 个文件里手写同一个平台名、同一个字段名、同一个风格选项,改一次就要全局搜索。更糟的是,Agent 可能只改了其中 5 个,留下 3 个旧值。
生产级 Skill 的资源层,本质上是在给 Agent 留一套「唯一真相源」。
如果一个 Skill 只有你自己能用,它还不算真正完成。
setup.md 解决安装和依赖。guide.md 解决新手怎么用。changelog.md 解决版本变更。troubleshoot.md 解决常见故障。
这四件套看起来不性感,但非常关键。
Skill 一旦多起来,你会发现真正耗时间的不是第一次写出来,而是三周后你忘了它怎么装、半年后你不知道它为什么坏、换一台电脑后你不知道缺了哪个依赖。
工程化文档就是给未来的自己省命。
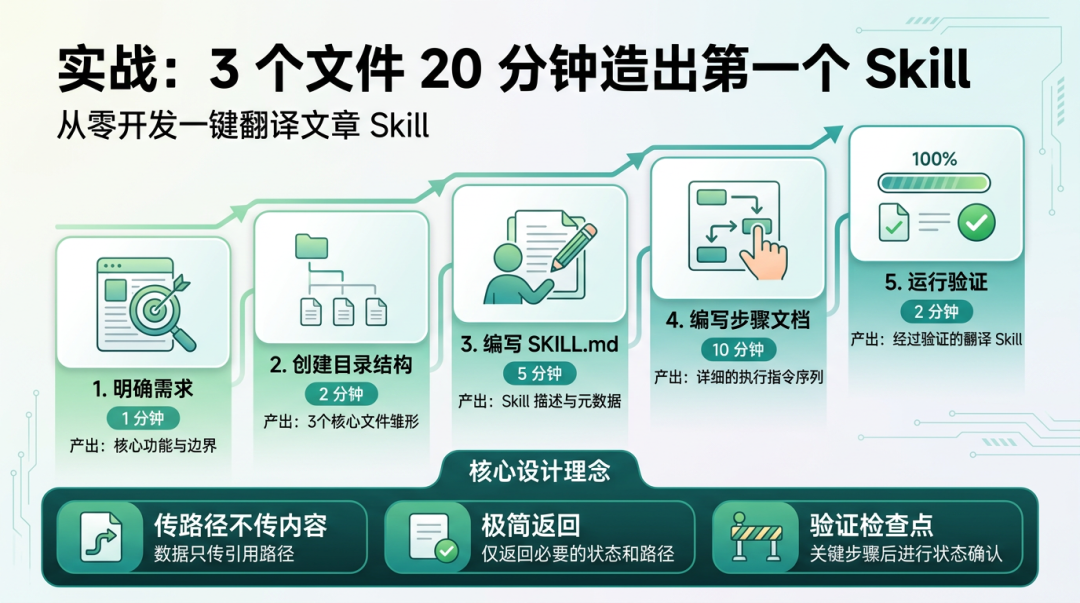
最适合入门的案例,是一个文章翻译 Skill。
需求很简单:输入一篇英文 Markdown 文件路径,输出翻译后的中文 Markdown,保留标题、列表、代码块和链接。
目录只需要三个文件:
xiangyu-content-article-translating/
├── SKILL.md
└── workflow/
├── step01-init.md
└── step02-translate.md
SKILL.md 可以这样写:
---
name: xiangyu-content-article-translating
description: 将英文 Markdown 文章翻译为中文,保留原文格式和结构。当用户说「翻译文章」「translate article」「转中文」时触发。
---
# 文章翻译 Skill
## 工作流
Step 01 初始化:读取用户提供的文件路径,创建 runs 目录和 progress.json。
Step 02 翻译输出:启动 SubAgent 读取源文件,翻译后写入 output/translated.md。
## 执行规范
- 渐进式披露:执行一步读一步。
- 传路径,不传全文。
- SubAgent 返回极简状态,翻译结果写文件。
第一步初始化,检查文件存在,创建运行目录。第二步翻译输出,启动 SubAgent,把源文件路径和输出路径传给它。
关键点不是翻译本身,而是设计习惯:路径明确、输出明确、状态明确、验证明确。
这就是 Skill 开发的基本功。
写 Skill 的过程,本质上是在把你的隐性经验变成显性流程。
你脑子里「怎么写一篇好文章」的直觉,变成步骤文档。你「怎么做一次质量检查」的经验,变成检查清单。你「怎么排查失败」的经验,变成 troubleshoot.md。
这就是 AI 工作流真正值钱的地方:不是让 AI 偶尔帮你一次,而是让你的方法可以被复用、被调用、被改进。
从这个角度看,Skill 不是插件。
Skill 是你的数字操作手册。
可以。最小可用 Skill 只需要一个 SKILL.md 文件。只有当工作流需要调用 API、批量处理文件或复用确定性逻辑时,才需要增加脚本。
MCP 是让 AI 调用外部工具的接口,Skill 是让 AI 按固定流程完成任务的操作手册。Skill 可以在执行步骤里调用 MCP 工具,两者是互补关系。
没有硬性上限,但生产实践里建议控制在 6 到 8 步以内。超过 10 步时通常应该拆成多个 Skill,或者把确定性部分下沉到脚本。
AI 编程实操课(翔宇完整课程,从 Claude Code 到 OpenClaw 全流程):
国内版和国际版内容完全相同,根据你的支付渠道自行选择即可。
📚 更多 Agent 工作流内容:Agent 工作流实战指南:从单个 Agent 到十人团队的完整搭建路径
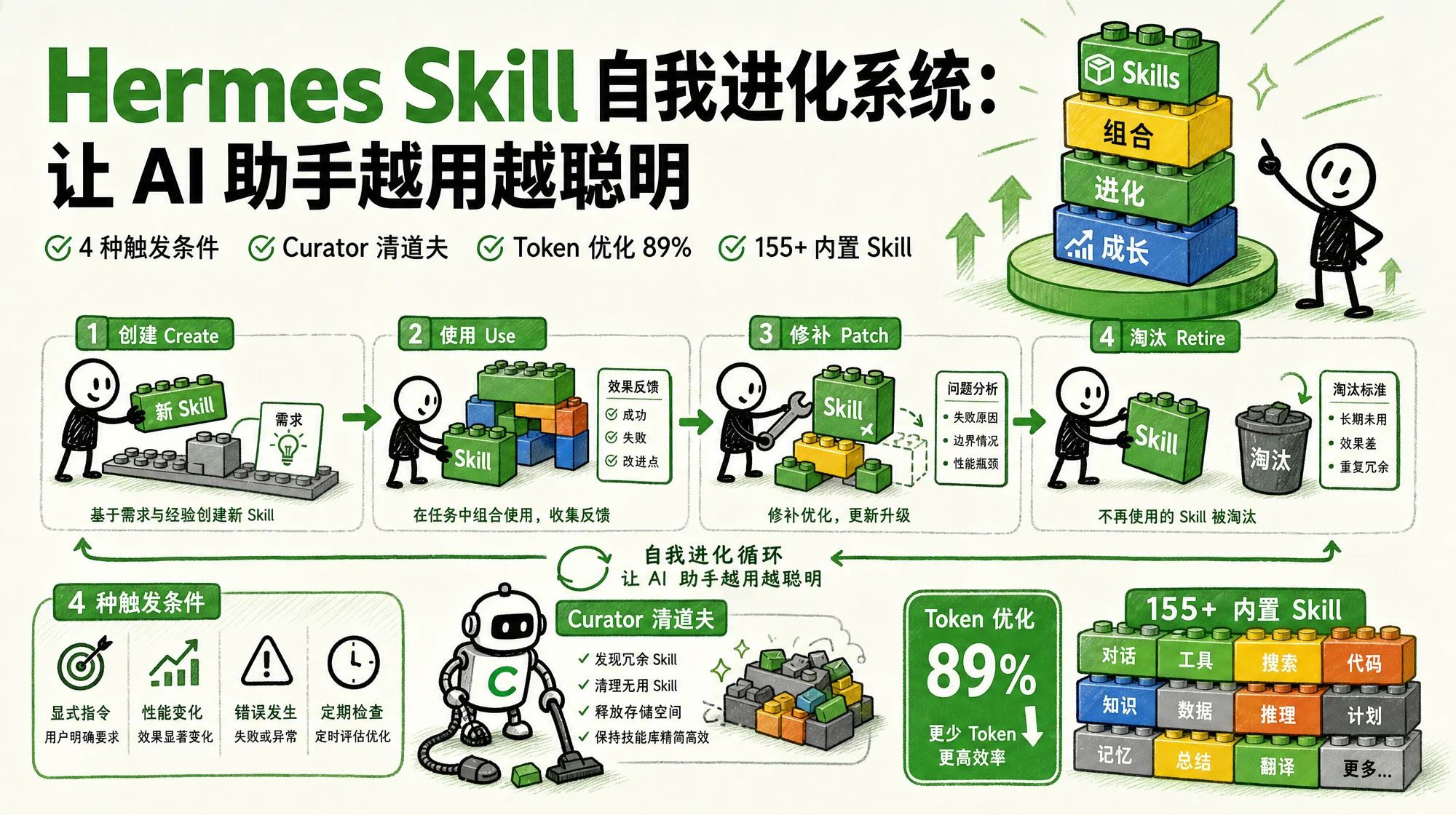
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。

Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。

基于两个 Ghost 站(中文站 + 英文站)18 个月的完整运营经验,覆盖选型决策、VPS 部署、域名配置、主题开发、Newsletter 增长、SEO 优化、多站管理和 API 自动化发布全链路。
每周精选 AI 编程与自动化实战内容,直达你的邮箱