Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
你的知识散落在几十个文件夹、好几个云盘、几百条聊天记录里。打开 AI 对话窗口,问一个自己领域的深度问题,得到的回答却像搜索引擎摘要——泛泛而谈、缺少你真正积累的判断和细节。
问题不在 AI 的能力上限,而在你喂给它的知识下限。
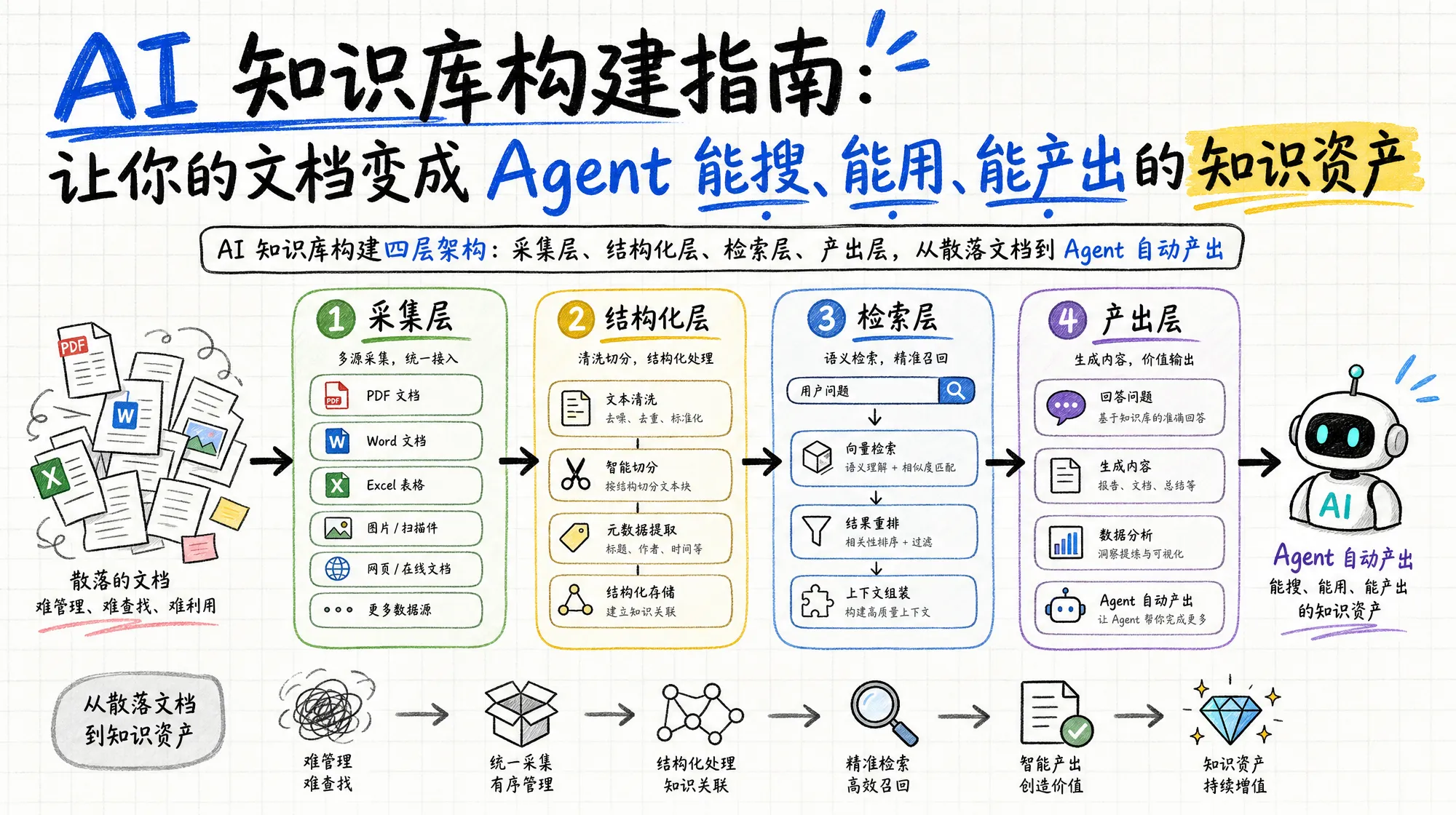
这篇指南从「为什么你的文档不等于知识库」讲起,走完采集、结构化、检索、产出四层架构,带你构建一个 Agent 能搜、能用、能持续产出的知识资产。文末附一份可打勾的构建检查清单,方便你对照进度。
先划一条线:文件夹和知识库是两件事。
文件夹是存放文件的容器。你在里面放了 200 份 Markdown、30 个 PDF、几张架构图,文件夹不会拒绝任何东西,也不会告诉 AI 这些文件之间有什么关系。AI 打开这个文件夹,看到的是一堆孤立的文件名。
知识库在文件夹之上做了三件事:
💡 通俗讲:文件夹像一个没有目录的图书馆,书随意堆在地上。知识库像一个分好类、贴好标签、配了图书管理员的图书馆——你说一个关键词,管理员就把相关的书摆到你面前。
这个区别在实践中的差距是惊人的。同样一个「根据我的品牌定位写一篇公众号引流文」的指令,对着散落文件写出来的内容和对着结构化知识库写出来的内容,完成度可以差几倍——后者能自动调取品牌定位、受众画像、历史爆款数据、写作风格规范,把这些融合进产出。
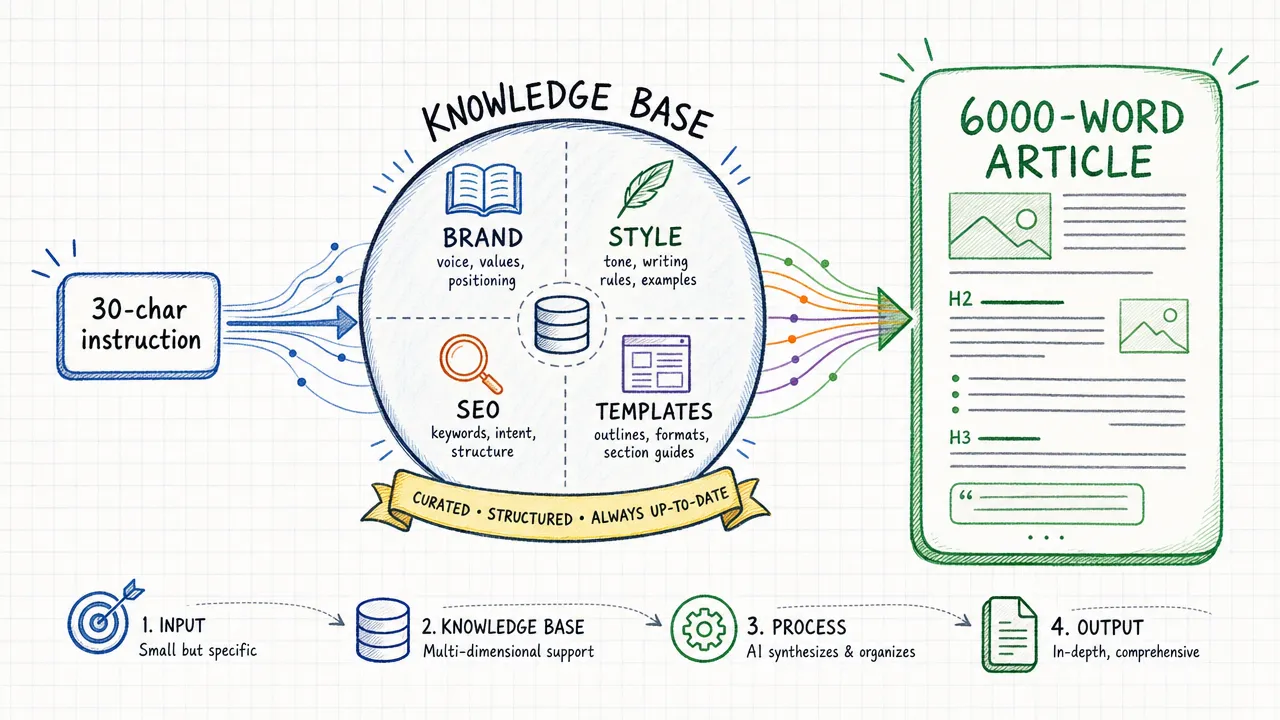
在 Agent 知识库:30 字指令写 6000 字长文 这篇教程里,我详细展示了这种差距的实际效果:一条不到 30 字的指令,Agent 在知识库的支撑下产出了一篇完整的、符合 SEO 标准的长文。关键不在于 Agent 有多聪明,而在于知识库给了它足够的素材和规则。
理解了知识库与文件夹的区别之后,下一个问题是:知识库到底长什么样?
经过长期实践打磨,一个能稳定支撑 Agent 产出的知识库通常包含四层:
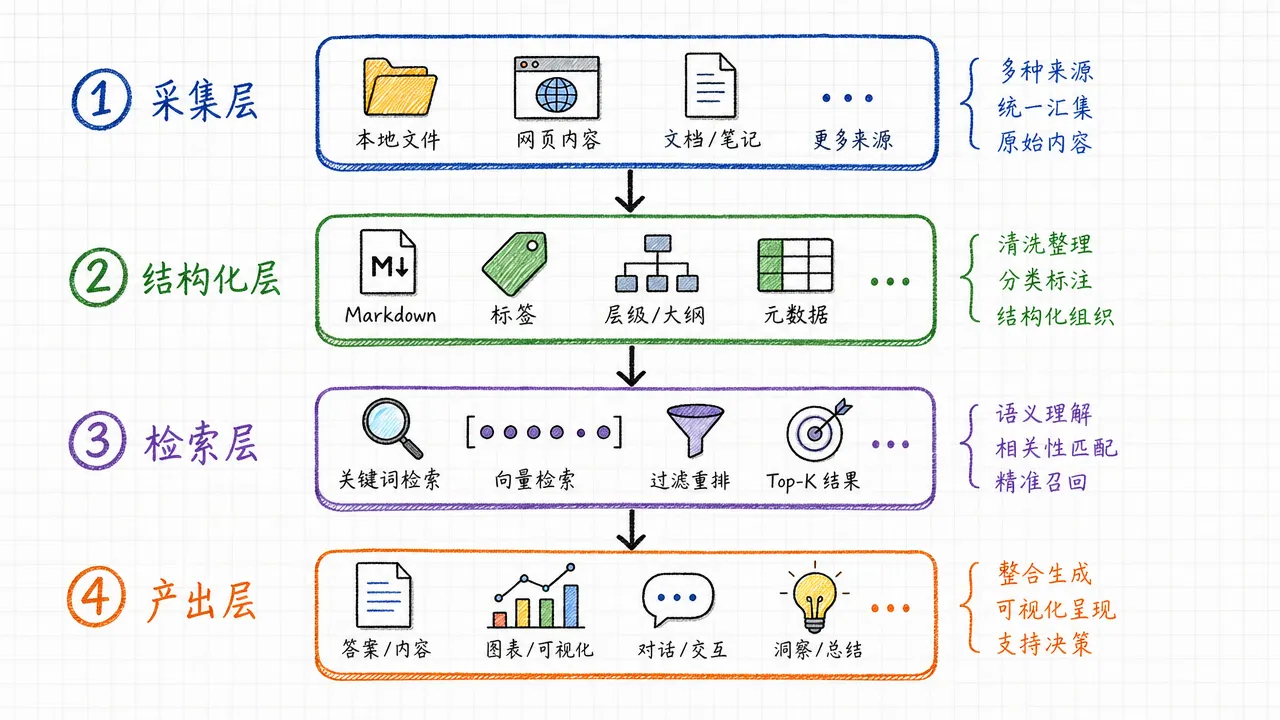
知识的原始状态五花八门:微信聊天记录里的技术讨论、浏览器收藏夹里的参考文章、本地代码仓库的注释、读过的电子书、做过的课程笔记。采集层的任务是把这些来源统一收拢到一个地方,转成可编辑的格式。
实践中最高频的采集动作包括:
采集不是囤积。采集层的产出应该是「有明确主题的素材文件」,而不是「把什么都丢进来」。一个判断标准是:如果这份素材三个月后你想不起来为什么存它,说明它不该进知识库。采集层的健康状态是每一份新入库的文件都有明确的用途指向——要么是某个写作主题的参考,要么是某个工作流程的依据,要么是某个决策的数据支撑。
采集来的原始素材需要经过结构化处理才能被 AI 高效使用。结构化的核心动作有三个:
统一格式:所有知识文件用 Markdown 格式,配 YAML frontmatter 标注标题、分类、关键词、创建日期等元数据。
分层标题:用 H2/H3/H4 建立内容层级,让 AI 能跳到特定章节而不用读完整篇。
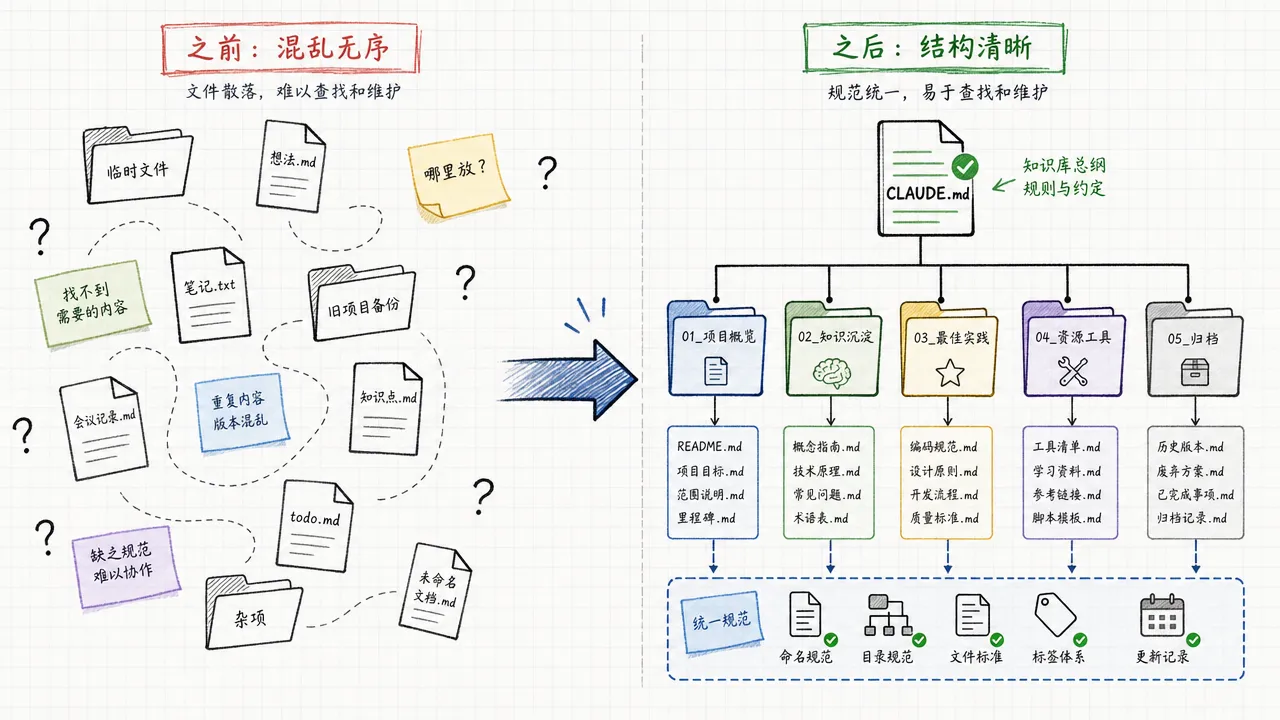
目录导航:在每个目录下放一份 CLAUDE.md,写明这个目录包含什么、子目录的用途、常用的触发词路由。根目录的 CLAUDE.md 是知识库的总入口。
🔍 深入一步:为什么选 Markdown 而不是 Notion 或飞书?因为 Markdown 是纯文本,任何 AI 工具都能直接读取,不依赖特定平台的 API。你换了工具、换了模型,知识库照样能用。这是知识资产的可移植性——你的知识不该被锁在某个 SaaS 产品里。
知识库里有几百甚至几千份文件时,Agent 不可能每次都读完所有内容。检索层解决的是「从哪找」和「怎么找」的问题。
本地检索:对于文件量在几百以内的知识库,CLAUDE.md 导航文件加 Claude Code 原生的文件读取能力就够了。Agent 通过触发词定位到目录,再读取具体文件。
语义检索(RAG):文件量更大或需要跨系统调用时,RAG(Retrieval-Augmented Generation,检索增强生成)是主流方案。原理是把知识文件切成小段,转成向量存入向量数据库,查询时用语义相似度匹配最相关的段落,喂给大语言模型生成回答。
💡 通俗讲:本地检索像在一个小书店里找书——你记得大概在哪个书架,走过去翻一翻就找到了。语义检索像在一个百万藏书的图书馆里找资料——你告诉检索系统你要研究什么主题,系统从不同楼层的不同书架上把相关段落摘出来送到你手边。
知识库的终极价值不是「被读取」,而是「被使用」。产出层把检索到的知识和预设的规则结合,让 Agent 直接完成具体任务。
常见的产出类型:
在 Agent 知识库实战:一人公司全自动内容生产线 这篇文章中,我展示了一个完整的四层架构运转实例——从知识库出发,Agent 自动完成内容生产的全流程,不需要逐步指令。
理论讲完,动手建。这一节给出最小可用版本的构建步骤。
在你的工作目录下新建一个文件夹作为知识库根目录,然后在根目录下创建 CLAUDE.md 文件。
CLAUDE.md 的核心内容包括:
这份文件不需要一次写完。从你最常用的三五个知识领域开始,后续边用边扩展。
目录结构按你的知识领域划分,没有标准答案,但有一条核心原则:一个目录只负责一类知识。
以内容创作者为例,可能的目录结构:
知识库/
├── CLAUDE.md # 总导航
├── 品牌/ # 品牌定位、受众、风格
├── 工具/ # 使用的 AI 工具和脚本
├── 规范/ # 写作规范、SEO 规范
├── 素材/ # 采集的参考素材
├── 业务/ # 已发布的作品和运营数据
└── 研究/ # 行业研究和趋势分析
每个一级目录下再放一份 CLAUDE.md,标注子目录结构和快速定位规则。
每份知识文件用 Markdown 格式,开头加 YAML frontmatter:
---
title: "品牌定位"
category: 品牌
tags: [定位, 价值观, 红线]
created: 2026-01-15
---
正文用 H2/H3 分层,一份文件聚焦一个主题。避免写「万能大杂烩」——一份文件塞了品牌定位、受众画像、竞品分析和写作风格的混合体,AI 用起来反而更低效。
在根目录的 CLAUDE.md 中加一张路由表:
| 触发词 | 路径 |
|--------|------|
| 品牌定位、价值观 | 品牌/身份/定位.md |
| 受众画像 | 品牌/受众/ |
| 写作风格 | 规范/写作风格/ |
| SEO 规范 | 规范/SEO/ |
这样 Agent 每次启动时读到这张表,就知道「用户提到品牌定位时,先去品牌/身份/定位.md 里找」。
⚠️ 常见踩坑:很多人在这一步花大量时间设计「完美的目录结构」,但实际上知识库是活的——目录结构会随着使用不断调整。先按直觉分好大类,用起来之后根据实际的检索需求优化,比一开始就追求完美更高效。
本地知识库搭好之后,下一步是让它在更多场景下可用。知识库云端化教程 详细讲解了从本地到云端的完整部署流程,这里概述核心路径。
本地知识库的局限很明显:
云端化解决这三个问题:多设备同步、跨工具访问、团队协作。
方案一:Git 仓库同步。把知识库目录推到 GitHub 或 GitLab 私有仓库,多设备通过 Git 同步。优点是版本控制天然内置,成本为零。缺点是 Git 处理二进制文件(图片、PDF)不够优雅。
方案二:云存储 + 同步工具。用 Syncthing 做端到端加密的实时同步,或者用 iCloud/坚果云做目录级同步。适合对版本控制要求不高、但需要实时同步的场景。
方案三:RAG 服务部署。对于大规模知识库或需要语义检索的场景,部署 RAG 服务(比如基于 LangChain、LlamaIndex 或自建方案)把知识库暴露为 API,任何 AI 工具都能通过接口查询。
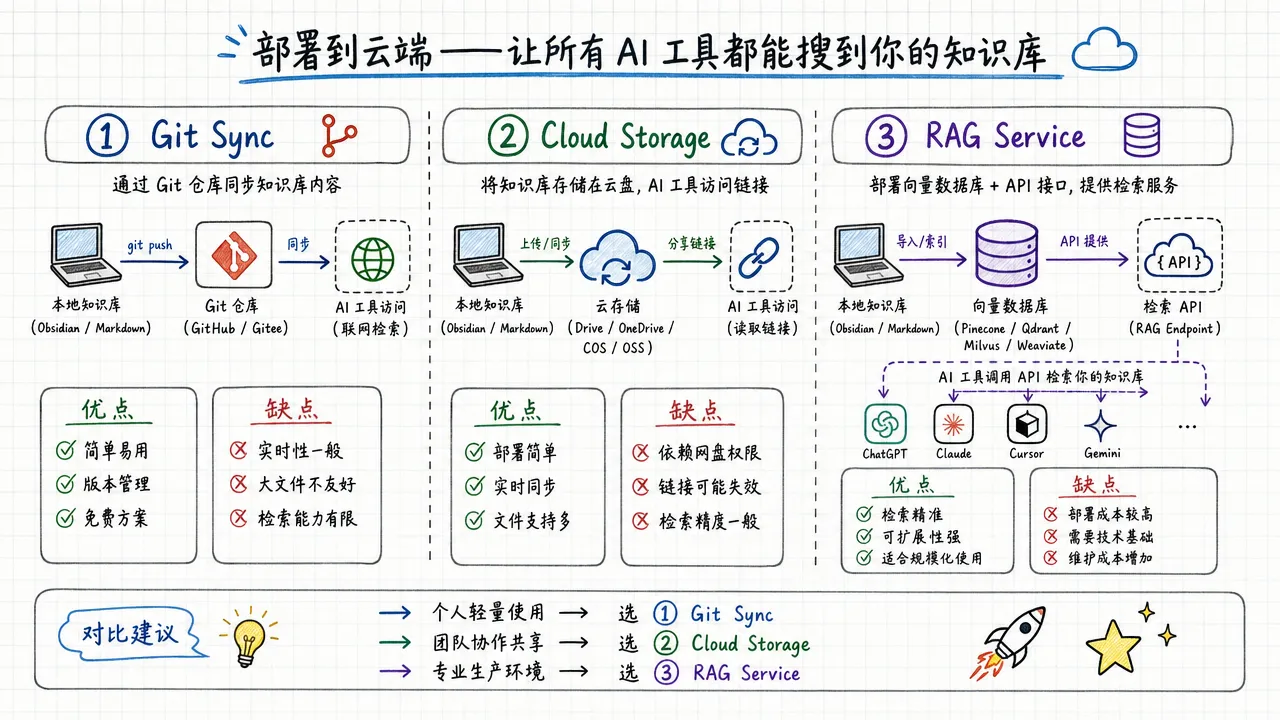
三种方案不互斥。实际操作中,常见的组合是「Git 做版本控制 + Syncthing 做多设备同步 + RAG 做跨工具检索」。
🔍 深入一步:如果你的知识库主要服务 Claude Code,其实不急着上 RAG。Claude Code 的上下文窗口和文件读取能力已经很强,配合 CLAUDE.md 导航,几百份文件规模的知识库完全跑得动。RAG 更适合「知识量大到 Agent 读不完」或「需要接入多个 AI 平台」的场景。
知识库的架构是通用的,但落地一定是垂直的。不同领域的知识有不同的结构特征和使用方式。
法律领域的知识库有一个突出特点:知识量巨大且高度结构化。法律条文、司法解释、案例判决,每一类都有明确的层级关系和引用规范。
在 法律知识库 Skill:850 万字法律库 中,我展示了一个覆盖多部法律法规的知识库是如何构建的。核心做法是:
这类知识库的检索需求极高——一个法律问题可能涉及几十条散布在不同法规中的条文——因此 RAG 语义检索几乎是必备的。
求职和职业发展领域的知识库需求和法律截然不同。用户关心的是趋势、薪资、技能树、转行路径这类半结构化信息。
RAG 知识库职业篇 展示了如何把分散的行业报告、招聘数据和职业发展建议整合成一个可查询的知识库。关键设计是:
个人电子书收藏从几十本到几百本之后,「找一本书里的某个观点」就变成了痛点。
Notion + Make 搭建自动化电子图书馆 展示了一种零代码方案:用 Notion 做书目管理和笔记结构化,Make(自动化工具)做采集和分类的自动化流程,最终形成一个可搜索、可标注、自动分类的个人图书馆。
这个案例的亮点在于门槛极低——不需要写代码,不需要部署服务器,用现成的工具组合就能实现。对于非技术背景但有大量阅读需求的用户来说,这是最务实的起步方案。
🔍 深入一步:三个案例看似领域不同,但共享一个设计规律——知识越结构化,检索粒度就越细,Agent 的产出精度就越高。法律知识库精确到法条编号,职业知识库精确到岗位和技能点,电子图书馆精确到章节和标注。这种粒度设计决定了知识库能支撑多复杂的任务。如果你要构建自己领域的知识库,第一个要回答的问题是:Agent 需要精确到什么粒度来调用你的知识?答案决定了你的结构化策略。
知识库建好之后,最直接的回报是产出效率的飞跃。
传统的 AI 写作流程是这样的:打开对话窗口,花 10 分钟写一段详细的提示词,描述你要什么风格、什么受众、什么结构、引用什么素材。每次写不同的文章,都要重新描述这些信息。
有了知识库之后,流程变成:给 Agent 一个主题,Agent 自动从知识库调取品牌定位、受众画像、写作风格、SEO 规范、历史案例,按照内化的规则完成写作。你的指令从几百字缩短到几十字,产出质量反而更高——因为知识库里的规则比你临时写的提示词更完整、更一致。
这就是 Agent 知识库:30 字指令写 6000 字长文 中展示的效果。一条简短的指令背后,是知识库几十份文件的协同支撑。
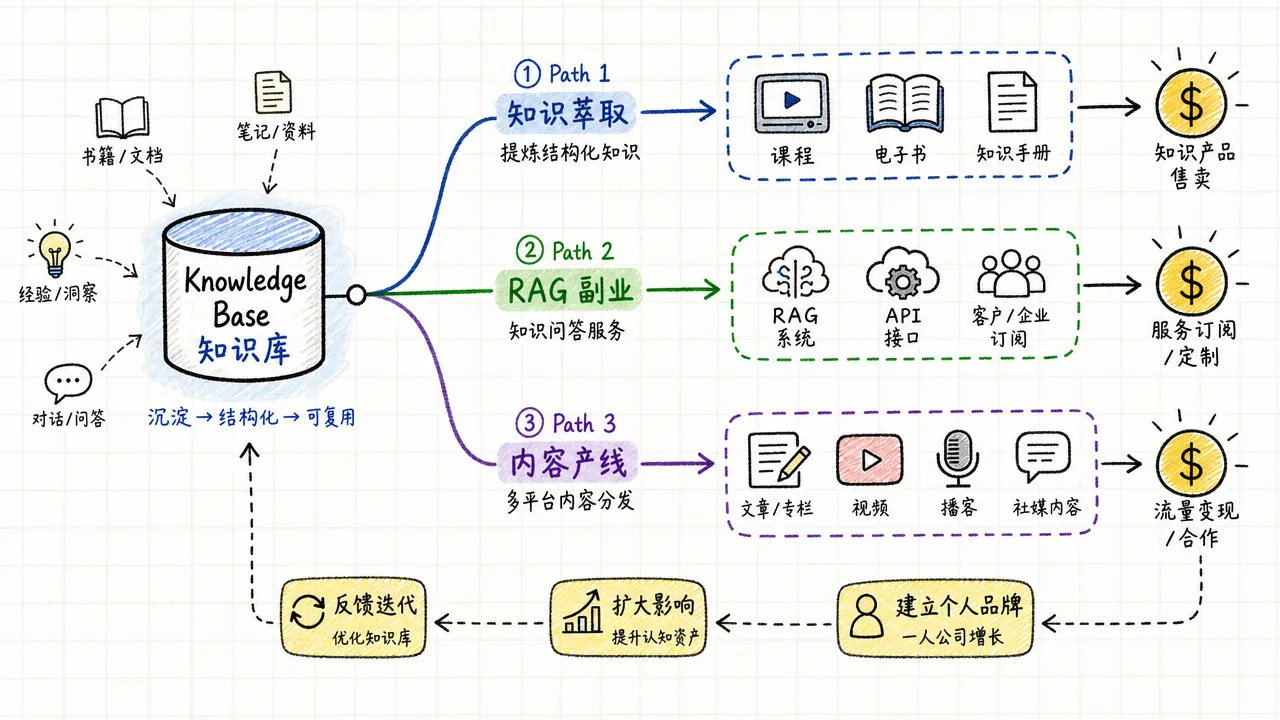
更进一步,知识库驱动的产出不限于写作。在 Agent 知识库实战:一人公司全自动内容生产线 中,同一个知识库同时支撑了文章写作、SEO 优化、多平台发布、数据分析等多个环节。知识库成了一人公司的核心基础设施——不是锦上添花的工具,而是整个业务运转的底座。
💡 通俗讲:没有知识库的 AI 写作像是每次做菜都要从头买调料——你得告诉它放多少盐、用什么油、什么火候。有知识库的 AI 写作像是你已经把常用调料配好放在固定位置,告诉厨师「做一道红烧肉」就够了,厨师知道去哪拿酱油、去哪拿冰糖。
知识库不只是效率工具,它本身就是可变现的资产。
每个人都有大量「只存在于脑子里」的经验和判断。这些隐性知识一旦结构化到知识库里,就变成了可复制、可售卖的产品。
知识炼金术:创作者的知识萃取 系统地讲了这个过程:如何从日常工作中提取可复用的方法论,如何把方法论结构化成教程或课程,如何让知识库自动生成不同形态的内容产品(文章、课件、短视频脚本)。
核心思路是:你不是在卖知识本身,而是在卖知识的组织方式和应用路径。同样的知识,散落在聊天记录里价值为零,结构化成知识库后可以反复产出,价值被杠杆放大。
RAG 全自动知识库副业工作流 展示了一个具体的变现模型:为特定行业建立 RAG 知识库,然后基于这个知识库提供自动化文档服务。
比如,为房地产中介建立一个包含政策法规、小区数据、贷款方案的知识库,然后提供「一键生成房产评估报告」「自动回答买家常见问题」等服务。知识库是你的护城河——竞争对手可以用同样的大模型,但没有你花时间整理的垂直领域知识。
一人公司最稀缺的资源是时间。知识库驱动的自动产出能把内容生产从手工作坊变成流水线:
这不是未来的愿景,而是已经跑通的模式。关键在于前期投入的边际成本:每一份结构化的知识文件都是「一次整理、反复产出」的资产。你今天花一个小时整理品牌定位文档,未来每一次内容产出都不用再重新描述品牌是什么、写给谁、什么风格——这些全由知识库兜底。积累到一定规模后,产出效率的提升是指数级的。
不是。知识库的价值不在于存了多少文件,而在于 Agent 能不能快速找到并正确使用这些知识。1000 份杂乱的文件不如 100 份结构清晰的文件。定期清理过时内容、合并重复文件,比一味堆量更重要。
这是最常见的拖延陷阱。知识库是用出来的,不是规划出来的。从你最常用的 5-10 份文件开始建,用的过程中发现缺什么补什么。等你「觉得差不多了」再开始,大概率永远不会开始。
知识库对人同样有价值。结构化的知识文件本身就是高质量的参考文档,目录导航就是你个人知识体系的全景图。很多人在整理知识库的过程中发现了自己认知的盲区——「原来我对这个领域的理解只停留在表面」。
RAG 是强大的检索方案,但也带来复杂度:向量数据库要维护、嵌入模型要选型、检索质量要调优。对于大多数个人用户和小团队,Markdown 文件 + CLAUDE.md 导航的方案完全够用。先把知识本身整理好,再考虑技术升级。
知识库和代码仓库一样需要维护。新知识要及时纳入,过时信息要更新或标注,目录结构要随使用需求调整。建议每月花一到两个小时做一次知识库巡检,保持知识的新鲜度和准确性。
具体的巡检动作包括:检查哪些文件超过三个月没更新、哪些目录下的文件从未被 Agent 调用过、哪些触发词路由指向了已经不存在的文件。这些信号帮你识别知识库中的死角——要么是知识过时了需要更新,要么是路由设计有问题需要调整。
知识库和笔记应用的区别在于「面向谁」。笔记是给人看的,结构松散、口语化没关系。知识库是给 Agent 用的,结构必须机器可解析、内容必须完整自洽。同一个话题的笔记可能散在十几条随手记里,知识库里它应该被整合成一份聚焦的文档。如果你同时有笔记习惯和知识库需求,建议把笔记当作采集层的输入——定期把笔记中有复用价值的内容提炼、结构化后归入知识库。
⚠️ 常见踩坑:知识库最大的敌人不是技术门槛,而是「完美主义导致的不启动」。大部分知识库的第一个版本都很粗糙,但只要开始用了,迭代的动力就会自然产生。
用这份清单对照你的进度:
⬜ 确定知识库根目录位置(本地路径或 Git 仓库)
⬜ 创建根目录 CLAUDE.md 导航文件
⬜ 设计一级目录结构(3-7 个为宜)
⬜ 每个一级目录下创建子 CLAUDE.md
⬜ 把最常用的 5-10 份知识文件迁入并结构化(Markdown + frontmatter)
⬜ 在 CLAUDE.md 中建立触发词路由表
⬜ 用 Agent 执行一次真实任务,测试检索命中率
⬜ 根据测试结果调整目录结构或补充知识文件
⬜ 考虑云端同步方案(Git / Syncthing / 云存储)
⬜ 评估是否需要 RAG 语义检索(文件量 > 500 或跨工具场景)
⬜ 试跑一次知识库驱动的长文产出
⬜ 建立月度巡检习惯(清理过时内容、补充新知识)
⬜ 探索变现可能性(知识萃取 / RAG 服务 / 自动内容产线)
这篇指南覆盖了知识库从概念到落地、从本地到云端、从自用到变现的全链路。每个环节都有对应的深度教程,你可以按需深入:
知识库的价值是复利型的——今天多整理一份文件,明天所有调用这份知识的产出都会更好。现在开始,永远不晚。
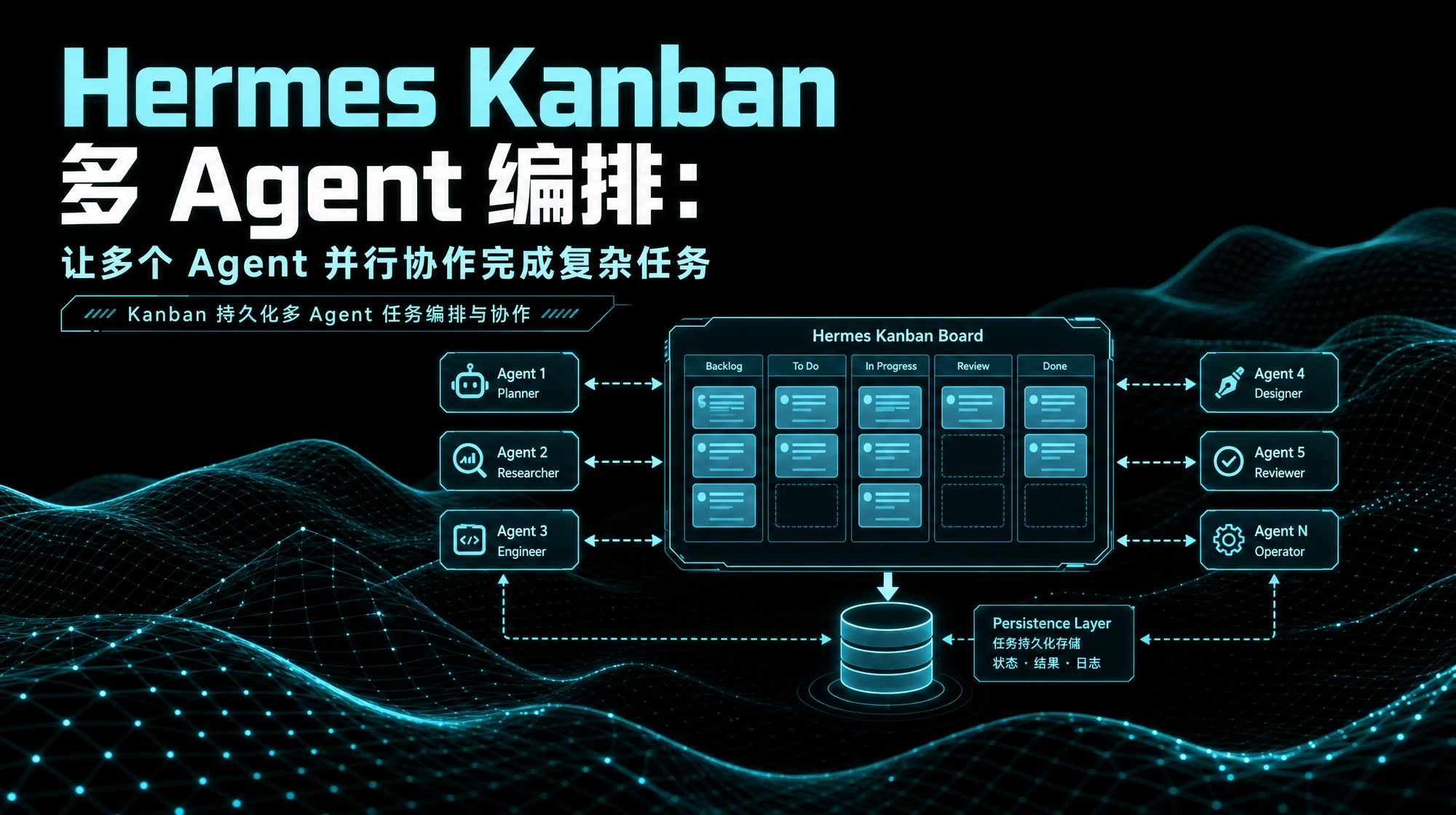
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
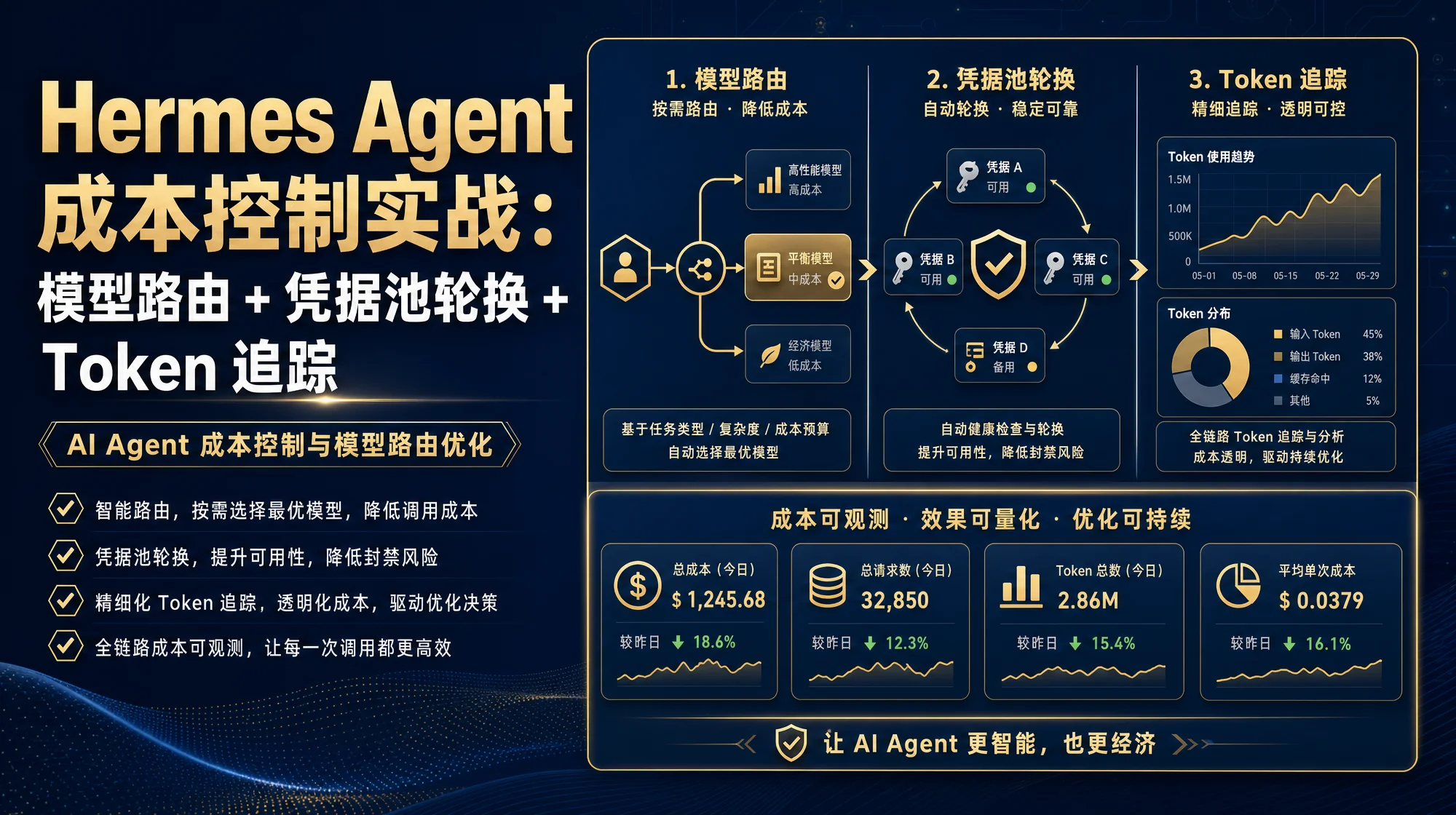
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
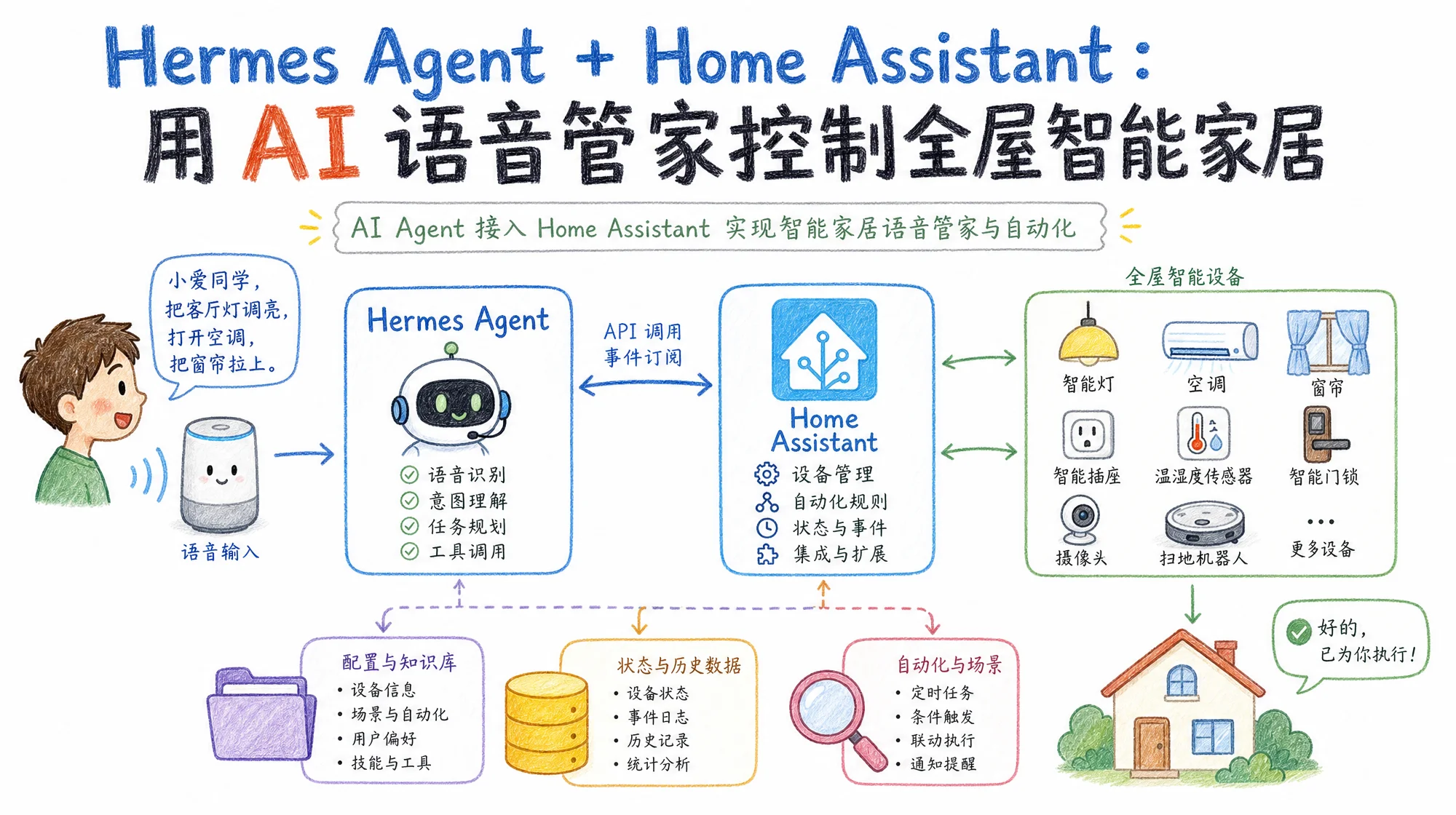
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 支持三种本地推理后端:Ollama 一键启动、LM Studio 可视化管理、vLLM 生产级吞吐。本文覆盖完整接入配置、64K 上下文铁律、模型选型矩阵(按硬件/任务/语言推荐)、社区高频痛点解决方案,以及翔宇 GLM→DeepSeek→Gemini 三模型实战策略。
每周精选 AI 编程与自动化实战内容,直达你的邮箱