Hermes Skill 自我进化系统:让 AI 助手越用越聪明
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。
用 Make.com 自动化生成高质量提示词的独家方法。区别于常规的单轮生成,这套工作流采用多阶段迭代策略——先生成框架再逐层填充细节最后自我评审优化,产出的提示词质量远超手写。教程涵盖提示词元结构设计、多轮 AI 对话编排、质量评分自动筛选和 Notion 提示词库管理,帮你从手动写一条升级为系统化批量生产。

提示词的质量直接决定了 AI 输出的质量,这个道理大家都懂。但问题在于,写一个真正好用的结构化提示词并不容易——你需要定义角色、目标、技能、约束、工作流程、输出格式,每一个部分都要精心设计。如果手动写,一个高质量的提示词可能要花半小时甚至更久。
我是翔宇。翔宇花了很长时间测试了多种提示词自动化方案,踩过不少坑,最终找到了这套既高效又可控的迭代方法。
那如果我需要100个、1000个不同领域的提示词呢?手动写显然不现实。
我花了很长时间测试了多种方案,踩过不少坑,最终找到了一个既高效又高质量的方法——利用推理大模型的深度理解能力,配合 EXA 爬虫采集的互联网素材,在 Make 中实现提示词的全自动化生成。你只需要输入一句10个字的需求,系统就能输出一个完整的、结构化的、可直接使用的提示词。
本教程配套视频已发布在 YouTube,建议搭配视频一起学习效果更佳。
先用一个简单例子说明。你去点咖啡,说"给我一杯咖啡"——这是不好的提示词。说"请给我一杯中杯美式咖啡,加两份糖,要热的,不要牛奶"——这才是好的提示词。
好的提示词具备结构化和框架化的特征。上面这个例子本质上就是一个简单框架:"主意图 + 属性 + 工作流程"。通过清晰的结构表达意图和需求,减少来回沟通成本,提高输出精准度。
对于自动化工作流来说,这一点更为关键。因为大模型的输出会作为下一个模块的输入,你必须确保输出是稳定、标准、可预期的。标准化才能自动化,自动化才能规模化。
我常用的框架是 LangGPT——一个国内比较知名的开源结构化提示词项目。它的核心结构包含:
这个框架的好处是每个部分职责清晰,组合在一起就构成了一个完整的"工作回头书"。
方法一(失败):简单模型直接创作。把提示词发给不带推理能力的大模型,它不会帮你改写提示词,而是直接按照提示词执行。尤其是带有结构化输出示例的提示词,模型会误以为你想让它扮演角色并输出内容。
方法二(可用但复杂):拆分框架分别创作。把框架拆成角色、能力、目标等多个部分,分别让大模型创作再组合。能实现,但工作流复杂,各部分之间缺乏协调性,质量不高。
方法三(推荐):利用推理大模型创作。这是我最终采用的方案。推理大模型(如 o1、o1-mini、DeepSeek R1、Gemini Thinking)会先理解你的意图——"你是要让我修改这个提示词,还是按它执行?"——然后基于理解进行创作。结果统一、结构清晰,一步到位。
创作型:只提供任务描述,让大模型从零创作。
流程是分步对话:
模仿型:提供一个参考提示词,让大模型基于它创作新的。
关键技巧——一定要先说"下面是一个提示词示例,请先回复'收到提示词示例'"。等它回复收到,再提出新需求。这个预处理步骤能确保大模型理解你的意图是修改提示词而不是执行它,百试百灵。
使用 Custom Webhook 模块,将生成的链接配置到 Notion 函数字段中。在 Make 中开启"Immediately as data arrives"模式后,只需在 Notion 中点击按钮即可触发,手机上也能操作。
使用 OpenRouter 的原生模块,模型选4o-mini(便宜稳定)。系统提示词的作用是根据用户的任务描述生成中英文检索关键词,输出为 JSON 格式。
为什么要分 System Prompt 和 User Message 两步?三个原因:系统提示词权重更高、未来可以映射成 Notion 变量便于维护、复杂任务需要渐进式提供上下文。
Make 现在已内置 EXA 原生模块(早期版本需要 HTTP 调用)。配置要点:
检索到的3个结果通过 Text Aggregator 聚合,用换行符分隔合并成一个完整文本。
这是整个工作流最关键的模块。使用 OpenRouter 调用 o1-mini 模型(或 Gemini Thinking 免费模型)。
对话流程严格遵循分步模式:
一定要关闭 Automatic Fallback(防止模型被替换),Streaming 可以打开但影响不大。框架要求的提示词需要仔细调试——每个字的变动都会影响输出质量,我为此调试了很长时间。
由于推理模型的输出不一定是标准 JSON,再用一个 o1-mini 模块对输出进行结构化处理,然后通过 Parse JSON 解析为独立字段(Role、Description、Goals 等),方便后续映射组合。
用 Set Variable 将解析出的各字段组合成完整的 Markdown 格式提示词,添加时间戳和翔宇工作流标识,最终保存到 Notion 知识库的附录页中。
通过参考提示词字段是否为空来判断走哪条路径:
模仿型路径的对话流程略有不同:先发送参考提示词并要求回复"收到",再发送新任务让它参照创作。不需要开启结构化输出,因为每个人提供的参考提示词框架不同,直接保存原始输出即可。
Q:必须使用 o1模型吗,有没有免费替代?
A:可以用 Google Gemini Thinking 模型,它是免费的且效果也不错。DeepSeek R1也可以。核心要求是模型必须具备推理能力,普通对话模型做不到。
Q:批量生成1000个提示词大概需要多少成本?
A:如果用 o1-mini,1000个提示词大约需要几美元的 API 费用。用免费的 Gemini Thinking 模型则零成本,但可能遇到 Token 限制。
Q:EXA 采集的素材质量不高怎么办?
A:可以调整检索关键词的提示词,让关键词更精准。也可以增加返回结果数量到5-10个,给大模型更多素材参考。
这期视频从提示词是什么、框架是什么、为什么需要框架出发,系统讲解了利用推理大模型批量生成结构化提示词的方法。三种方案的演进过程也展示了搭建工作流时的真实思考路径——不是一步到位,而是不断迭代优化。
整套工作流的价值不仅在于提示词生成本身,更在于它展示的方法论:分步对话、推理模型、EXA 素材采集、结构化输出。这些技巧可以迁移到任何需要高质量内容生成的场景中。
📚 更多 Make 自动化内容:Make 自动化工作流完全指南
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
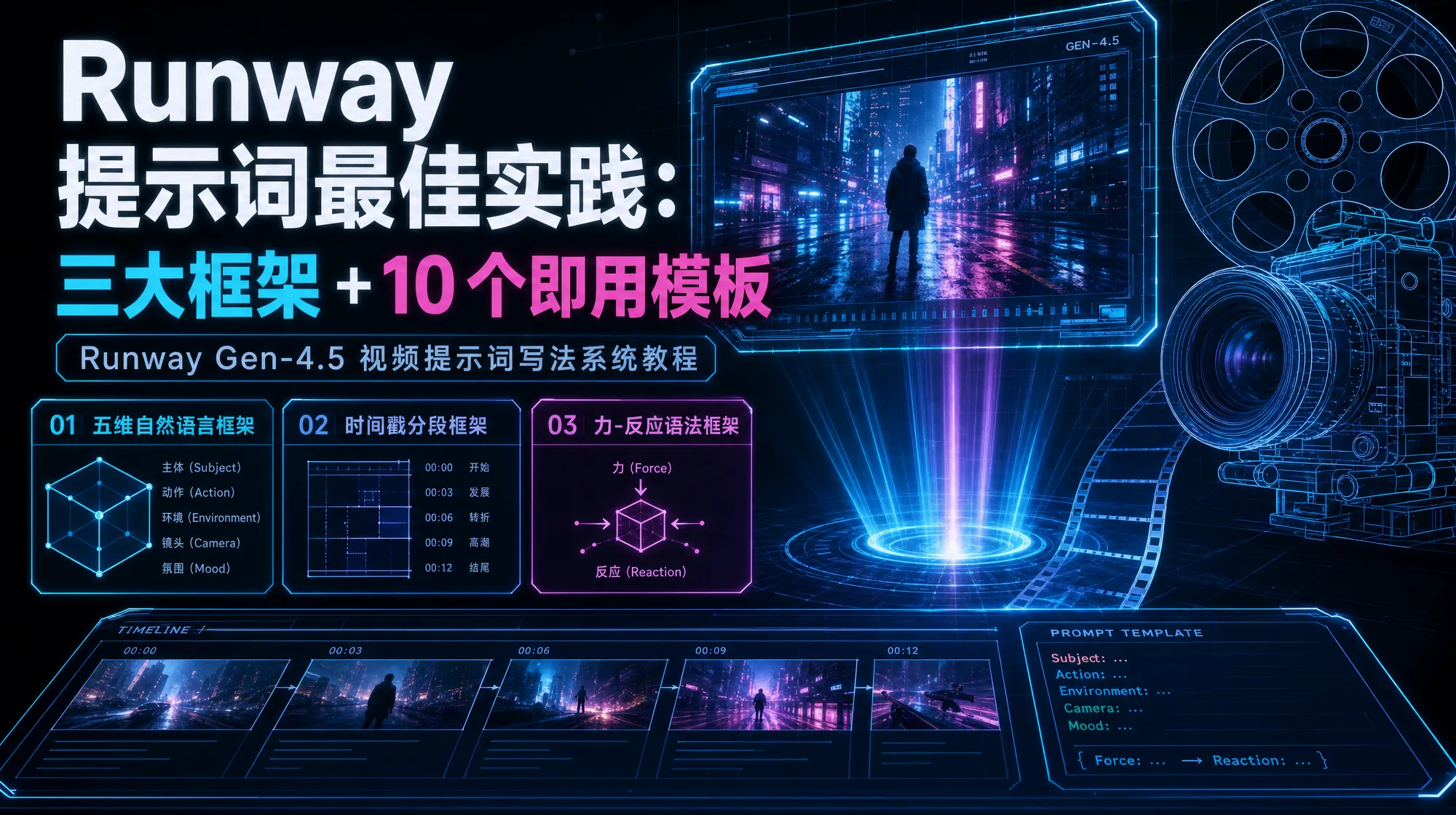
从零掌握 Runway Gen-4.5 视频提示词写法。一个八层统一框架融合五维自然语言、时间戳分段和力-反应语法,附 10 个精选模板和可直接使用的元提示词。

从零掌握 Google Veo 3.1 视频提示词写法。一个八层统一框架覆盖单镜头到时间戳多镜头,附 10 个精选模板和可直接使用的元提示词。

每周精选 AI 编程与自动化实战内容,直达你的邮箱