Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
工具会迭代,方法论不会过时。这篇指南覆盖驾驭工程、上下文工程、思维框架、项目记忆、权限控制五大方法论体系,串联 10 篇深度教程。

一个能跑的 Agent 编程体系,由五根支柱撑起来:驾驭工程、上下文工程、项目记忆、提示词工程、运行时控制。工具半年换一轮——去年还在用 Cursor,今年主力已经是 Claude Code 和 Codex。但让 Agent 按你的规矩干活的方法论,不会因为换了工具就失效。
大多数人学 Agent 编程停在「会用工具」这一层——装了 Claude Code、跑了几个任务、出了结果。但遇到复杂项目就发现:Agent 会干偏、会忘事、会越权、会在关键步骤做出意外的判断。问题不在工具,在你没有给它建立规矩。
这篇是 Agent 编程方法论的聚合页。它串联 10 篇深度教程,覆盖从概念到实操的完整路径。你可以把它当地图——先看全貌,再按需深入每个子主题。
要点速览
Agent 编程方法论,核心是回答一个问题:怎么让 Agent 在你的项目里可靠地工作?
这跟「怎么用 Claude Code」是两码事。学工具操作,解决的是「这个按钮干什么」的问题。学方法论,解决的是「Agent 干偏了怎么办」「凭什么信任它的判断」「怎么让它记住上次的教训」「怎么防止它在生产环境做出你没预料的判断」这些工程问题。
一个直观的对比:学工具操作的人换了工具要从头学,学方法论的人换工具只需要适配接口——因为底层的管理逻辑没变。
目前 Agent 编程领域有三个核心概念经常被混用,需要先理清关系。
提示词工程(Prompt Engineering)——关注单次对话怎么写指令。它是起点,但远不是全部。一条好提示词能让 Agent 在单次任务中表现更好,但它解决不了跨会话记忆、权限控制、团队协同这些持久化问题。
上下文工程(Context Engineering)——Shopify CEO Tobi Lutke 提出的概念,关注在正确的时间把正确的信息喂给 Agent。它比提示词工程的范围大得多,涵盖了项目记忆、动态检索、工具调用结果注入等整个信息供给链路。OpenAI Codex 上下文工程新手指南对这个概念有完整拆解。
驾驭工程(Harness Engineering)——这是我在实践中总结的总纲。它把 Agent 当作一个需要管理的「新员工」,用规范文件、上下文策略、权限边界和扩展机制建立完整的管理体系。上下文工程和提示词工程都是驾驭工程的子维度。什么是驾驭工程?这篇对概念、架构和实战做了一文通透的拆解。
💡 通俗讲:提示词工程是「怎么跟 Agent 说一句话」,上下文工程是「怎么让 Agent 看到对的信息」,驾驭工程是「怎么让 Agent 在你的项目里长期可靠地工作」。三者是包含关系,不是替代关系。
驾驭工程的核心思想很直接:不要逐句指挥 Agent 做什么,而是建立一套体系让它自己干活。
想象你招了一个新员工。你不会每分钟告诉他「现在打开这个文件,删掉第 3 行,加上第 5 行」。你会做三件事:给他一份入职手册(规范),带他熟悉项目(上下文),告诉他什么事可以自己做、什么事必须先问你(权限)。
驾驭工程对 Agent 做的是同样的事。
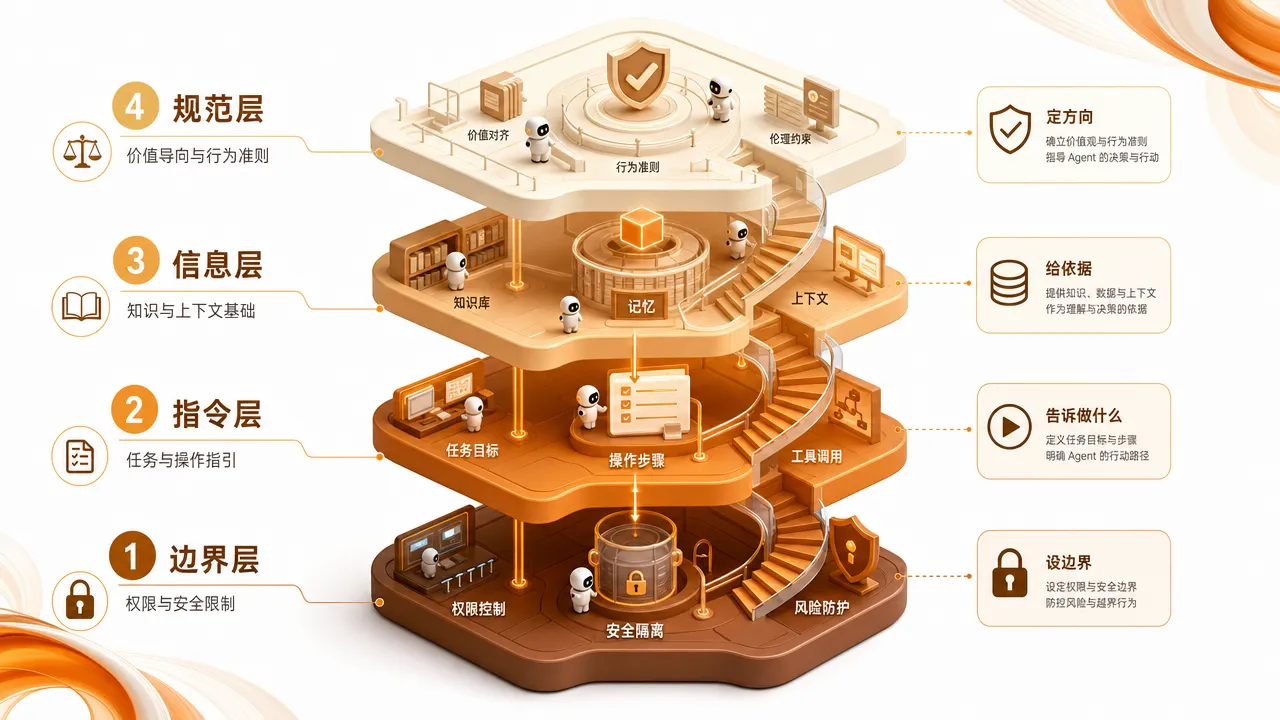
它的架构分四层:
| 层级 | 解决什么问题 | 对应方法论 |
|---|---|---|
| 规范层 | Agent 应该遵守什么规矩 | 项目记忆(CLAUDE.md) |
| 信息层 | Agent 应该看到什么信息 | 上下文工程 |
| 指令层 | 单次任务怎么表达清楚 | 提示词工程 |
| 边界层 | Agent 能做什么、不能做什么 | 运行时控制(权限 + 沙箱) |
这四层不是独立的,是协同工作的。规范层定方向,信息层给燃料,指令层驱动执行,边界层防越权。缺了任何一层,Agent 的输出质量都会下降。
举个具体场景:你让 Agent 给项目加一个用户认证模块。如果只有指令层(提示词)而没有规范层(CLAUDE.md 里写了「用 NextAuth.js,不用自建认证」),Agent 可能花两小时从头搭一个自建认证系统。如果没有边界层(权限控制),Agent 可能在你没注意的时候修改了数据库 schema。四层配合才能让这个任务高效、安全地完成。
🔍 深入一步:驾驭工程跟传统软件工程的区别在于——传统工程管的是代码,驾驭工程管的是一个有「自主判断能力」的执行者。代码不会自作主张,Agent 会。所以驾驭工程的核心挑战不是写逻辑,而是约束判断。你写的不是执行步骤,而是判断标准。
什么是驾驭工程?这篇从概念、架构到实战做了完整拆解。如果你只想读一篇就理解 Agent 编程方法论的全貌,从那篇开始。
Agent 干偏的原因,大多数时候不是它「笨」,是它「瞎」——你没有把它需要的信息喂进去。
上下文工程解决的就是这个信息供给问题。它的核心逻辑是一句话:在正确的时间,把正确的信息,以正确的格式,喂给 Agent。
这里面每个词都重要。
「正确的时间」——不是一股脑把所有信息都塞进去。Agent 的上下文窗口有限,信息太多反而会干扰判断。该用 CLAUDE.md 持久化的信息就写进记忆文件,该在运行时动态检索的就用工具调用,该在特定步骤才注入的就用 Hooks。
「正确的信息」——不是给得越多越好。Agent 最需要的信息是:项目的技术栈和架构决策、编码规范和约定、已知的坑和绕法、当前任务的上下文。这些信息的来源可以是项目记忆文件、文档检索、代码库搜索或网络查询。
「正确的格式」——同样的信息,结构化表达比自然语言描述更容易被 Agent 准确理解。比如用 YAML 写配置偏好,用表格写选项对比,用代码块写提示词模板。一条好的上下文注入,格式占了一半功劳。
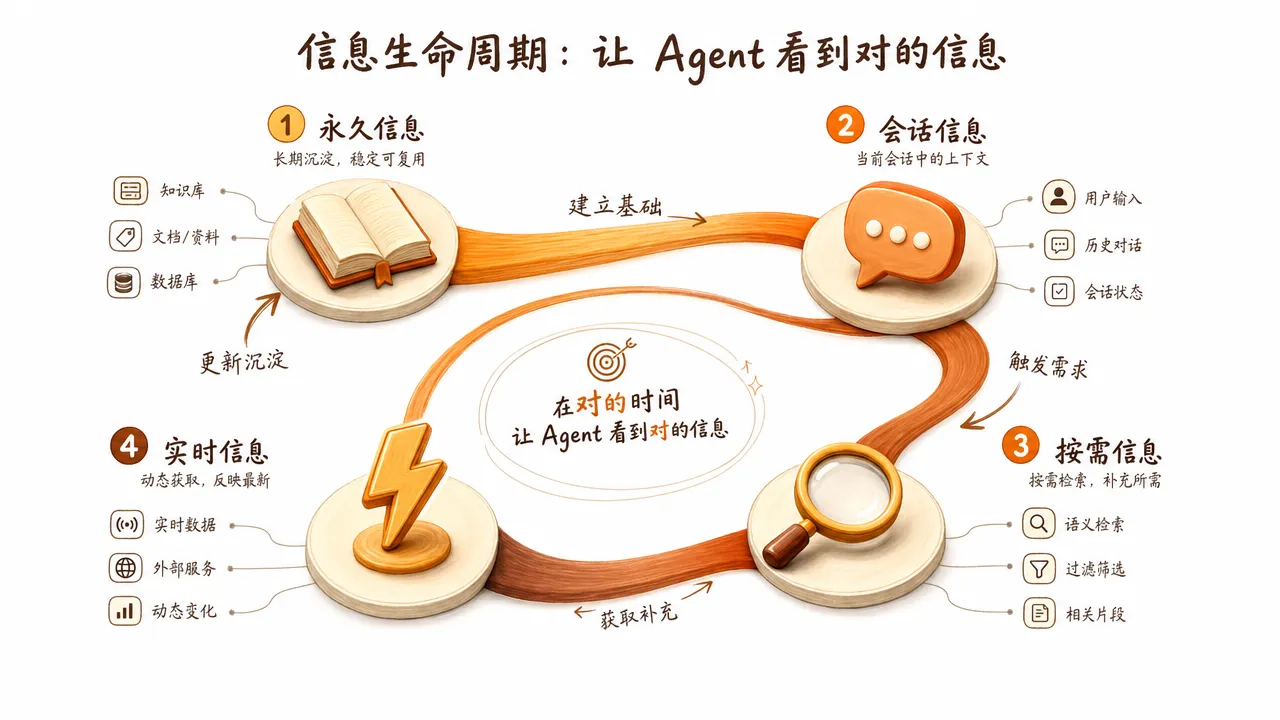
上下文工程的实操方法可以按信息的生命周期来分类:
| 信息生命周期 | 适合的注入方式 | 典型场景 |
|---|---|---|
| 永久有效 | 项目记忆文件(CLAUDE.md) | 技术栈选型、编码规范、架构约定 |
| 会话级有效 | 系统提示词 / 首条消息 | 当前任务的上下文背景、角色设定 |
| 按需触发 | 工具调用 / 动态检索 | 查文档、搜代码库、拉外部 API |
| 实时产生 | 执行结果注入 | 测试输出、编译报错、运行时日志 |
⚠️ 常见踩坑:很多人把上下文工程等同于 RAG(检索增强生成,Retrieval-Augmented Generation)。RAG 只是上下文工程的一种实现手段——从外部知识库检索信息。上下文工程的范围大得多,涵盖项目记忆、系统提示词、动态检索、工具结果注入、会话历史管理等整条信息链。把 RAG 等同于上下文工程,就像把搜索引擎等同于互联网——后者的范围比前者大一个数量级。
OpenAI 在 Codex 的设计中对上下文工程做了非常清晰的工程化实践——从 AGENTS.md 文件到沙箱环境变量,每一层信息注入都有明确的设计意图。OpenAI Codex 上下文工程新手指南从「AI 为什么干偏」这个问题出发,倒推出上下文工程的完整框架。
上下文工程解决「喂什么信息」的问题,项目记忆解决「怎么让这些信息持久化」的问题。
Agent 的本质缺陷是无状态——每次新会话启动,它对你的项目一无所知。所有的技术栈偏好、编码约定、架构决策、历史踩坑,都需要重新告诉它。如果你每次都靠手打提示词来传递这些信息,效率极低,而且容易遗漏。
项目记忆文件就是解决这个问题的。Claude Code 用 CLAUDE.md,OpenAI Codex 用 AGENTS.md,Cursor 用 .cursorrules。名字不同,本质一样:把项目规范写成 Agent 能读懂的文件,让它每次启动都自动加载。
CLAUDE.md 的设计尤其值得关注,因为它支持多级记忆体系:
全局级(~/.claude/CLAUDE.md)
→ 所有项目共享的个人偏好和通用规范
项目级(项目根目录/CLAUDE.md)
→ 这个项目的技术栈、架构和约定
目录级(子目录/CLAUDE.md)
→ 特定模块的专属规范
这种层级设计意味着规范可以继承和覆盖——全局规范定底线,项目规范定方向,目录规范定细节。团队协作时,每个人的全局规范不同,但项目规范是统一的。
💡 通俗讲:项目记忆文件就是 Agent 的「入职手册」。新员工第一天上班,你不会口头交代所有规矩——你会给他一份手册,让他有问题先查手册。CLAUDE.md 对 Agent 起的是一模一样的作用。
写好 CLAUDE.md 有几个关键原则:
一个容易忽略的细节:记忆文件的效果跟它在上下文中的位置有关。Agent 对开头和结尾的信息注意力更高,对中间的容易忽略。把最关键的约束放在文件前部——比如「禁止直接修改生产数据库」这种硬红线,应该出现在前 10 行,不是埋在第 200 行。
CLAUDE.md 怎么写?这篇有完整的写作指南和可抄的模板,是项目记忆实操的起点。

项目记忆解决的是持久化规范,提示词工程解决的是每次任务的即时指令。
Agent 编程场景下的提示词,跟聊天场景的提示词有本质区别。聊天时你可以写「帮我写个网站」,模型会按默认假设给你一个结果。编程时你写同样的话,Agent 大概率会做出一堆你不想要的决策——用你不喜欢的框架、选你不需要的功能、搭一个跟现有项目完全不兼容的架构。
关键差异在于:聊天是一次性的,编程是有上下文的。 编程场景的提示词必须跟项目记忆、代码库、历史会话协同工作,不能孤立存在。
好的 Agent 编程提示词有三个特征:
明确约束边界。 不是告诉 Agent「写一个组件」,而是「在 src/components/ 下新建 UserProfile.tsx,用项目已有的 Card 和 Avatar 组件组合,props 接口继承 User 类型」。约束越明确,Agent 的自由裁量空间越小,偏差越少。
分解到可验证的步骤。 一条大而模糊的需求拆成多条可独立验证的小任务。不是「重构用户模块」,而是「第一步:提取公共类型到 types/user.ts;第二步:把 UserService 拆成 UserAuthService 和 UserProfileService」。每一步做完你能验证结果是否正确。
预设判断标准。 告诉 Agent 什么算做完了——不是「优化性能」,而是「首屏加载时间降到 2 秒以内,Lighthouse Performance 分数达到 90+」。有了明确的判断标准,Agent 能自己决定什么时候停。
🔍 深入一步:提示词工程的一个高阶技巧是「示范优于描述」。与其用三段话描述你想要的代码风格,不如直接给一个已有的范例文件让 Agent 参考。Agent 从样本中提取模式的能力,远强于从自然语言描述中还原意图的能力。
Claude Code 提示词怎么写?这篇从「把模糊需求改成工程任务」的角度,给出了完整的提示词写作方法。
前面四个维度解决的是「给 Agent 什么信息」和「怎么给」的问题。思维框架解决的是更深一层的问题:怎么让 Agent 用更好的方式思考?
Agent 默认的思维方式是「按最大概率输出」——它会选择训练数据中最常见的解法。大多数时候这够用了。但在需要创造性思考、系统性分析、多角度权衡的场景下,默认思维方式会趋向平庸。
思维框架就是用来打破这种局限的工具。
一个实际的例子:你让 Agent 分析一个业务决策,默认它会给你一个 SWOT 分析——因为训练数据里 SWOT 分析最多。但如果你在提示词里指定「用第一性原理从基本事实出发推导」,或者「用反演法从最坏结果倒推风险」,Agent 的分析质量会显著提升。
这不是玄学。本质原因是:思维框架改变了 Agent 的注意力分配方式。指定框架等于告诉 Agent「沿着这条路径思考」,减少了它在多个思考方向上的随机游走。
💡 通俗讲:思维框架之于 Agent,就像棋谱之于棋手。棋手不是死记棋谱——他通过学习棋谱内化了判断模式,遇到新局面能更快找到好棋。Agent 也是一样,好的思维框架帮它在复杂问题上更快找到高质量的分析路径。
具体怎么用思维框架?两个层级:
会话级注入——在提示词中直接指定框架。适合单次任务,比如「用 MECE 原则拆分这个需求」「用 5W1H 分析这个问题」「用红队视角找出这个方案的三个最大漏洞」。
项目级固化——在 CLAUDE.md 中写入常用框架。适合团队统一思考方式,比如「所有架构决策用 ADR(Architecture Decision Record)格式记录,包含背景、选项、决策和后果」「Bug 分析用 5-Why 根因法」。
这里面有一个容易被忽视的洞察:思维框架的价值不在于让 Agent 变聪明,而在于让它变可预测。 不指定框架时,同一个问题问三遍可能得到三种完全不同的分析路径。指定框架后,Agent 的分析路径变得稳定可复现。对于团队协作和质量管控,可预测性比聪明更重要。
200 个思维框架这篇整理了实战中验证有效的框架库,按场景分类。重要的不是记住 200 个,而是在你的领域找到 5-10 个高频好用的,固化到日常工作流里。
方法论的前五层——驾驭工程、上下文工程、项目记忆、提示词、思维框架——解决的都是「输入端」的问题。运行时控制解决的是「执行端」的问题:Agent 在运行过程中,怎么确保它的行为在可控范围内?
运行时控制有三个核心维度。
Agent 的上下文窗口是它的「工作记忆」。Claude Code 支持最大 100 万 token 的上下文窗口,但这不意味着你应该把所有信息都塞进去。
信息太少,Agent 缺乏判断依据,容易干偏。信息太多,Agent 在海量信息中迷失重点,同样会干偏。上下文窗口管理的核心是在充分和精简之间找到平衡。
Auto Compact 机制是关键——当上下文接近窗口上限时,Agent 会自动压缩历史信息,保留关键摘要。理解这个机制,你才能合理规划长会话中的信息密度。
上下文窗口新手指南对窗口大小、Auto Compact 机制和实际使用策略做了完整讲解。
Claude Code 提供多档思考模式(thinking modes),从默认模式到 ultrathink,对应不同深度的推理能力。
不是所有任务都需要最深的思考。简单的格式化、重命名、模式替换用默认模式就够了。复杂的架构设计、跨模块重构、多约束权衡才需要 ultrathink。
⚠️ 常见踩坑:把思考模式当成「质量开关」——以为开了 ultrathink 就一定出好结果。思考模式影响的是推理深度,不是知识覆盖面。如果 Agent 缺乏必要的上下文信息,再深的思考也弥补不了信息缺口。先确保信息充分,再考虑思考深度。
选择思考模式的判断标准是任务的推理链长度。如果一个任务需要 Agent 在 3 步以内完成推理,默认模式够用。如果推理链超过 5 步、涉及多个约束条件的权衡取舍,上 ultrathink。
思考模式新手指南对每种模式的适用场景和性能差异做了详细拆解。
权限管理是运行时控制中最容易被忽视、也最容易出事的环节。
Claude Code 提供 6 种权限模式,从最严格的「每步确认」到最宽松的「全自动执行」。核心原则是最小权限——给 Agent 刚好够完成任务的权限,不多给。
权限管理不是一次性配置,是一个渐进过程。你对一个项目的信任度越高、对 Agent 行为模式越熟悉,可以逐步放宽权限。但在生产环境,永远保持保守策略。
权限新手指南覆盖了 6 种模式的配置方法和安全沙箱的使用策略。

前面讲的方法论体系让 Agent 在已有能力范围内可靠工作。扩展机制解决的是另一个问题:怎么让 Agent 获得新能力?
Hooks 是 Agent 运行时的检查点机制。它允许你在 Agent 的关键操作节点——比如修改文件前、提交代码前、执行命令前——插入自定义逻辑。
Hooks 解决的核心需求是安全和质量的自动化保障。比如:
这些检查人工做容易遗漏,用 Hooks 固化到 Agent 工作流里就变成了确定性的保障。Claude Code 提供了 8 个检查点,覆盖了从文件操作到命令执行的关键节点。
Hooks 新手指南详细讲了 8 个检查点的用法和配置方法。
如果说 Hooks 是在 Agent 已有能力上加检查点,Plugins 就是给 Agent 接入全新的能力。
Agent 默认能读写文件、执行命令、搜索代码。但很多实际工作需要超出这些能力的操作——比如调用外部 API、查询数据库、操作浏览器、访问专业知识库。Plugins 提供了标准化的接口,让 Agent 能调用这些外部能力。
🔍 深入一步:Plugins 的设计哲学是「能力组合」而不是「能力内建」。Agent 不需要内建所有能力——它需要一个标准化的方式来调用外部工具。这跟 Unix 的管道哲学一脉相承:每个工具做好一件事,通过标准接口组合起来完成复杂任务。
Plugins 新手指南覆盖了插件生态的使用方法和开发指南。
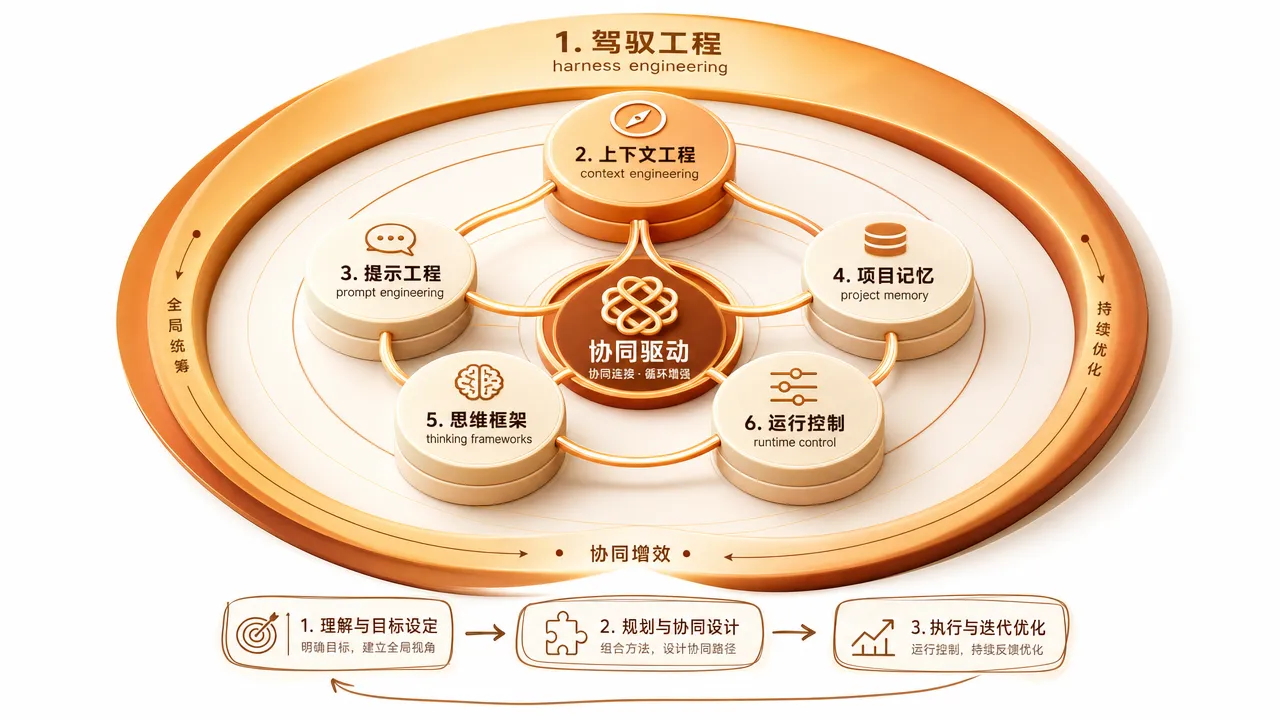
五大方法论不是五个独立的技能点,是一个有层次的体系。
┌─────────────────────────────────────────────────┐
│ 驾驭工程(总纲) │
│ 把 Agent 当新员工管理的完整体系 │
│ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ 上下文工程 │ │ 提示词工程 │ ← 信息供给 │
│ │ 喂对的信息 │ │ 说对的指令 │ │
│ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │
│ ┌──────┴───────┐ ┌──────┴───────┐ │
│ │ 项目记忆 │ │ 思维框架 │ ← 认知基础 │
│ │ 持久化规范 │ │ 思考方式 │ │
│ └──────────────┘ └──────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ 运行时控制 │ ← 行为边界 │
│ │ 上下文窗口 │ 思考模式 │ 权限沙箱 │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ 扩展机制 │ ← 能力增长 │
│ │ Hooks │ Plugins │ │
│ └──────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
驾驭工程是总纲,它定义了「怎么管理 Agent」的整体框架。上下文工程和提示词工程是信息供给层——解决 Agent 知道什么、被要求做什么的问题。项目记忆和思维框架是认知基础层——解决 Agent 的知识持久化和思考方式问题。运行时控制是行为边界层——解决 Agent 在执行时的约束问题。扩展机制是能力增长层——解决 Agent 能力边界的扩展问题。
学习建议:从驾驭工程的概念开始,建立全局认知。然后根据你当前最痛的问题选择切入点——如果 Agent 老干偏,先学上下文工程;如果不知道 CLAUDE.md 怎么写,先学项目记忆;如果任务结果不可控,先学运行时控制。
| 你的痛点 | 建议阅读顺序 |
|---|---|
| Agent 总是干偏 | 上下文工程 → 项目记忆 |
| 不知道怎么给 Agent 下指令 | 提示词工程 → 思维框架 |
| Agent 做了不该做的事 | 权限控制 → Hooks |
| 想扩展 Agent 的能力 | Plugins → Hooks |
| 想从全局理解方法论 | 驾驭工程 → 按上面的痛点路径深入 |
⬜ 我理解驾驭工程的核心思想——不逐句指挥,而是建规矩、给资源、设边界
⬜ 我的项目有 CLAUDE.md(或等价的项目记忆文件),包含技术栈、编码约定和架构决策
⬜ CLAUDE.md 按多级体系组织——全局偏好、项目规范、目录细节各归各位
⬜ 我给 Agent 的提示词有明确的约束边界,不是模糊的自然语言需求
⬜ 复杂需求我会拆解成可独立验证的小任务,而不是一条大指令丢过去
⬜ 我知道上下文工程不等于 RAG——我在正确的时间喂正确格式的信息
⬜ 我会根据任务复杂度选择合适的思考模式,不是一律用默认或一律用最深
⬜ 我的 Agent 权限遵循最小权限原则,不会为了方便开全自动模式
⬜ 我配置了关键操作的 Hooks 检查点——至少包含提交前跑测试
⬜ 我有常用的思维框架清单,并把高频框架固化到了项目记忆文件里
⬜ 我理解五大方法论的关系——驾驭工程是总纲,其他四个是子维度
⬜ 面对新的 Agent 工具,我先迁移方法论,而不是从零学操作
工具会换代,方法论不会过时。
今天你用 Claude Code,明天可能用下一代工具。但怎么给 Agent 定规矩、怎么喂信息、怎么设权限——这些方法论是通用的。它们不依赖于某个具体产品,而是依赖于 Agent 这个物种的基本特性:有自主判断能力,但需要约束和引导。
我的判断是:Agent 编程方法论会成为每个技术人的基础能力,就像版本控制和自动化测试一样——不是某个工具的使用说明,而是一种工作方式。
这篇是起点。10 篇深度教程各有侧重,根据你当前最痛的问题选择切入。
深入实操:对应课程模块
这篇讲的五大方法论体系,在翔宇的 AI 编程实操课中都有对应的实战模块——从 CLAUDE.md 的真实写法,到 Hooks 的配置实操,到多 Agent 协同的上下文管理策略。
延伸阅读
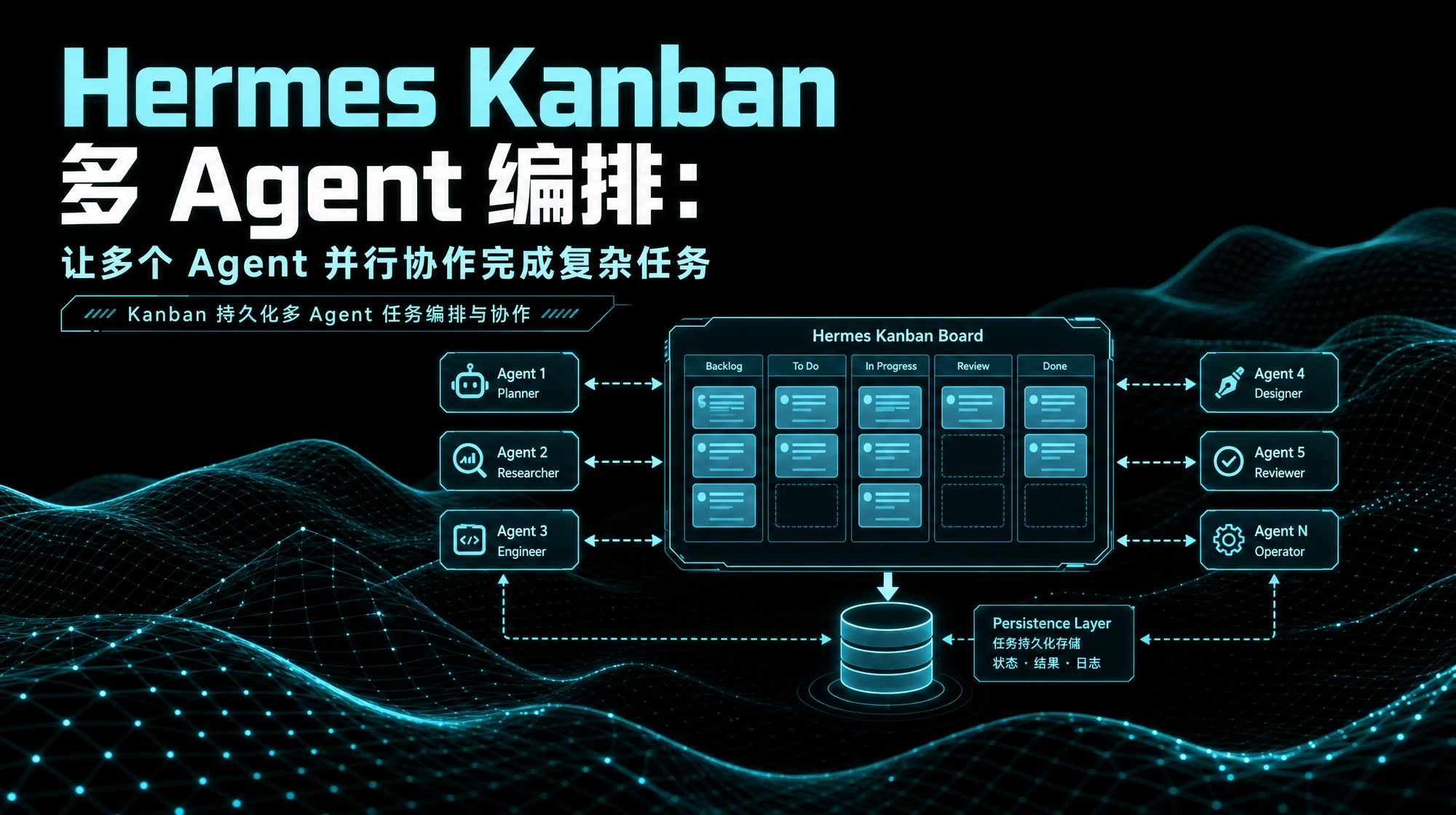
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
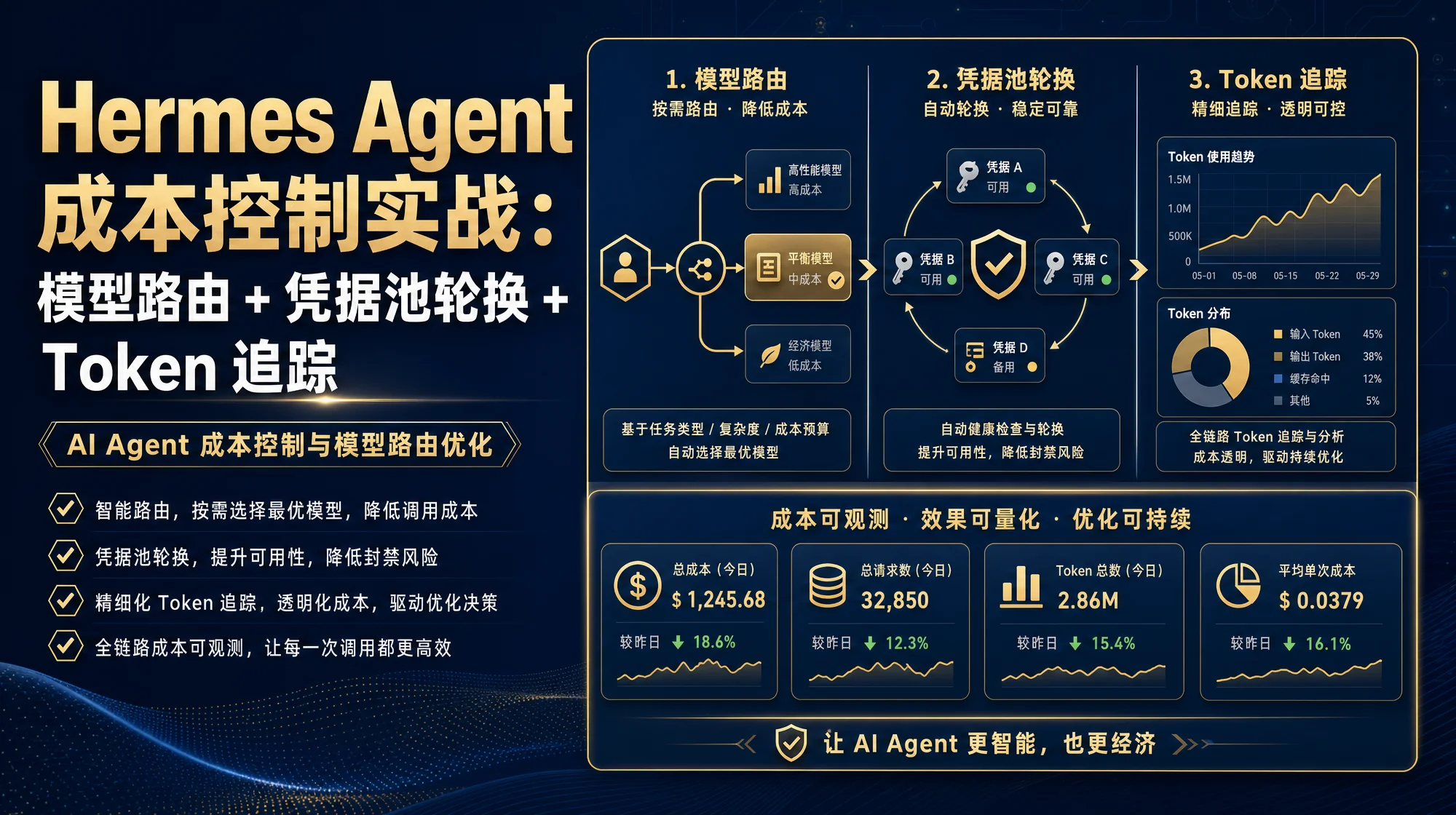
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
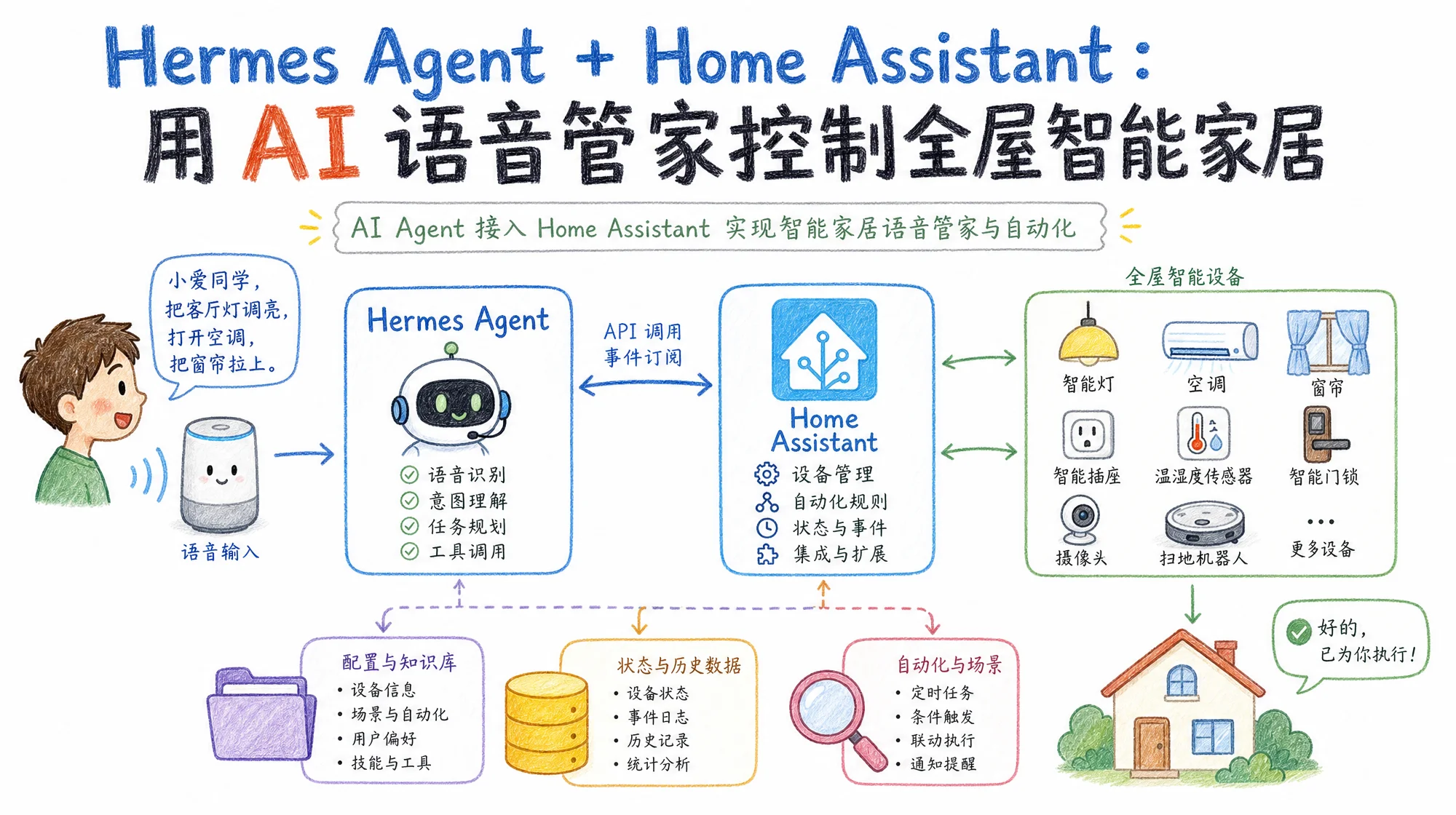
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 支持三种本地推理后端:Ollama 一键启动、LM Studio 可视化管理、vLLM 生产级吞吐。本文覆盖完整接入配置、64K 上下文铁律、模型选型矩阵(按硬件/任务/语言推荐)、社区高频痛点解决方案,以及翔宇 GLM→DeepSeek→Gemini 三模型实战策略。
每周精选 AI 编程与自动化实战内容,直达你的邮箱