Hermes Kanban 多 Agent 编排:让多个 Agent 并行协作完成复杂任务
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。
Claude Code 思考模式新手教程:讲清 effort 档位、ultrathink 关键词、扩展思考开关,看完知道什么时候该让 Claude 想得更深、什么时候省着用。

预计阅读 16 分钟。看完你会知道 Claude Code 的思考模式到底由什么控制、ultrathink 现在还有没有用、什么时候该让它想得更深、什么时候省着点。
先说清一件事:网上很多「think / think hard / think harder / ultrathink 四档预算阶梯」的中文教程已经过时了。这篇按官方当前机制讲,把真正的主控(effort 档位)和你常听说的 ultrathink 摆到一起说清楚,再给你一套能照做的判断。
还要提醒一句:思考模式涉及的具体模型号、档位数量、默认档会随 Claude Code 和模型版本更新而变,本文只钉住「由什么控制、怎么选」这套不变的机制,具体值以你机器上
/effort实际显示和官方文档当前内容为准。
一句话先答:Claude Code 的思考模式,现在由 effort 档位主控,ultrathink 是给单次提问临时加深的便捷开关。 扩展思考(extended thinking,指 Claude 回答前那段不直接展示的推理)默认就开着,你要做的不是「开不开」,而是「这件事值不值得让它想得更深」。
先按身份对号入座:
| 你是谁 | 推荐做法 |
|---|---|
| 刚装 Claude Code、听过 ultrathink 但不懂 | 先不动设置,难题在提示词里加 ultrathink 即可,其余交给默认档 |
| 老用户,停留在「四档关键词」旧认知 | 改用 /effort 定调,记住 think hard 这类短语现在不再是触发词 |
| 团队 / 企业,想控成本 | 统一一个较低默认档,难任务环境再放开,思考 token 按输出计费 |
| 也用 Codex / GPT,想对比 | Claude 用 effort 档位 + 关键词两条路,OpenAI 走 reasoning.effort 接口参数 |
最常见的新手错误是:把「想久一点」当成质量保证,简单任务也硬上最高档。 结果只是更慢更贵,质量几乎没差别。下面把机制和判断讲透。
先回答:思考模式解决的是「这件事需要 Claude 想多深」的判断,不是替你把需求说清楚。
你用 Claude Code 时多半遇到过两种别扭。一种是它回答太快,跨多个文件的改动它三两下就动手,漏掉了取舍和风险;另一种是它想得太久,明明是改个文案的小事,它也铺开一大段分析,让你等。这两种别扭,根子都在思考深度和任务难度没对上。
思考模式就是用来对齐这件事的旋钮。明确的小改动不需要深想,多方案比较需要认真想,跨文件架构和风险取舍才需要更高强度。把这条对应关系建立起来,比记住每个档位的英文名重要得多。
💡 通俗讲:思考 token 就像 Claude 答题前在草稿纸上打的草稿。草稿打得越多,难题想得越透,但简单题也铺一大张草稿纸,就是浪费纸和时间。思考模式让你决定每道题给多大张草稿纸。这张草稿(token)也是要算钱的——它按输出 token 计费,和 Claude 写给你的正式答案一个价,所以「多想」不是免费的,这也是后面要讲「怎么省」的原因。
要注意它的边界:思考模式提高的是「判断质量的机会」,不替你补清楚需求。需求模糊时,想得再久也只是更认真地猜。先写清目标、材料、限制和验收,再决定要不要加深思考,顺序不能反。新手常犯的一个错,是把目标说得含糊、再指望靠加深思考补回来——这条路走不通,模型只会沿着模糊的方向想得更细,离你真正想要的更远。
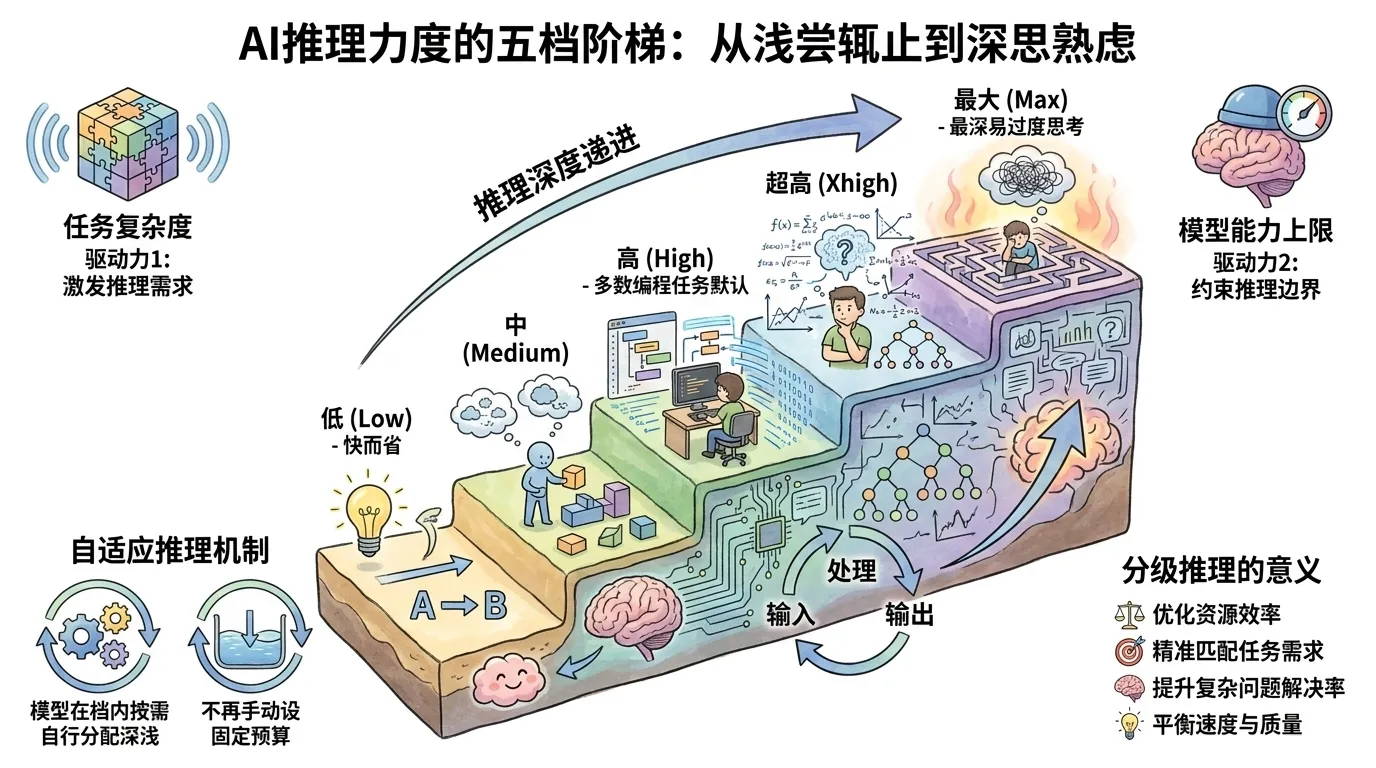
先回答:当前控制思考深浅的主控是 effort(推理力度)档位,配合自适应推理(adaptive reasoning)让模型按需分配。
这是全网旧教程最容易讲错的一节,得讲清楚。扩展思考是 Claude 回答前生成的那段推理,默认开启,按输出 token 计费。它的深浅由 effort 档位决定。
⏱️ 时效声明:下面提到的具体模型号、各模型支持几档、哪一档是默认,都会随 Claude Code 版本和模型更新而变。本文写法按官方当前机制讲,具体档位名与默认值以你机器上
/effort实际显示和官方 model-config 文档当前内容为准。要紧的是记住「档位由什么控制、怎么选」,而不是背某个版本号。
effort 档位随模型不同:能力更强的 Opus 系新模型一般给到 low / medium / high / xhigh / max 五档;其余支持 effort 的模型通常少一档(没有 xhigh)。默认档多数停在 high,部分模型出厂默认更高。你不用记哪个模型是几档——打开 /effort,机器会把当前模型支持的档和默认值直接列给你看,logo 和加载提示旁边也会标出当前生效的档(如「with low effort」)。
每一档怎么选,官方给了对应场景:
| 档位 | 什么时候用 |
|---|---|
low |
短、范围窄、对延迟敏感、对智力要求不高的活 |
medium |
对成本敏感、可以牺牲一点智力换省钱的活 |
high |
平衡 token 和智力,多数编程任务的默认 |
xhigh |
更深推理、更高 token 花费 |
max |
最深推理、不限制 token 花费,可能出现过度思考、收益递减,先小范围试再推广 |
还有一个容易混淆的 ultracode:它在 /effort 菜单里,但不是模型档位,而是 Claude Code 的设置——按 xhigh 推理,同时让 Claude 为较重的任务编排动态工作流,只对当前会话生效。换句话说,ultracode = 高推理力度 + 自动拆解任务,比单纯把档位拉到 xhigh 多了一层「先规划再执行」,适合一上来就很重的活。
这里有两个细节值得点出来。其一,档位的刻度是按模型校准的,同一个档位名在不同模型上不代表同一个底层值——同样设 high,换一个模型后实际思考力度并不等价。所以换模型后别假设「档位没变就一样」,必要时重新感受一下。其二,如果你设了当前模型不支持的档(比如在少一档的模型上设 xhigh),Claude Code 会自动落到它支持的、不超过你所设值的最高档——不会报错,但也不会真按 xhigh 跑。
🔥 翔宇判断:很多人卡在「该选
high还是max」,其实多数编程任务停在默认high就够。max不限 token、官方都明说容易过度思考、收益递减,把它当成专门为难题准备的临时档,而不是日常默认。能用默认解决的事,别一上来就把旋钮拧到底——拧到底的代价是更慢、更贵,而结果未必更对。
自适应推理是这套机制的另一半:它让思考在每一步变成可选,常规提问快速回答、值得深想的步骤才多想,由模型自己判断。较新的模型一律用自适应推理。换句话说,你设的 effort 档是「上限和倾向」,模型在档内自己决定每一步要不要动用深度思考——你不用再像旧时代那样手动猜一个固定的 token 预算。
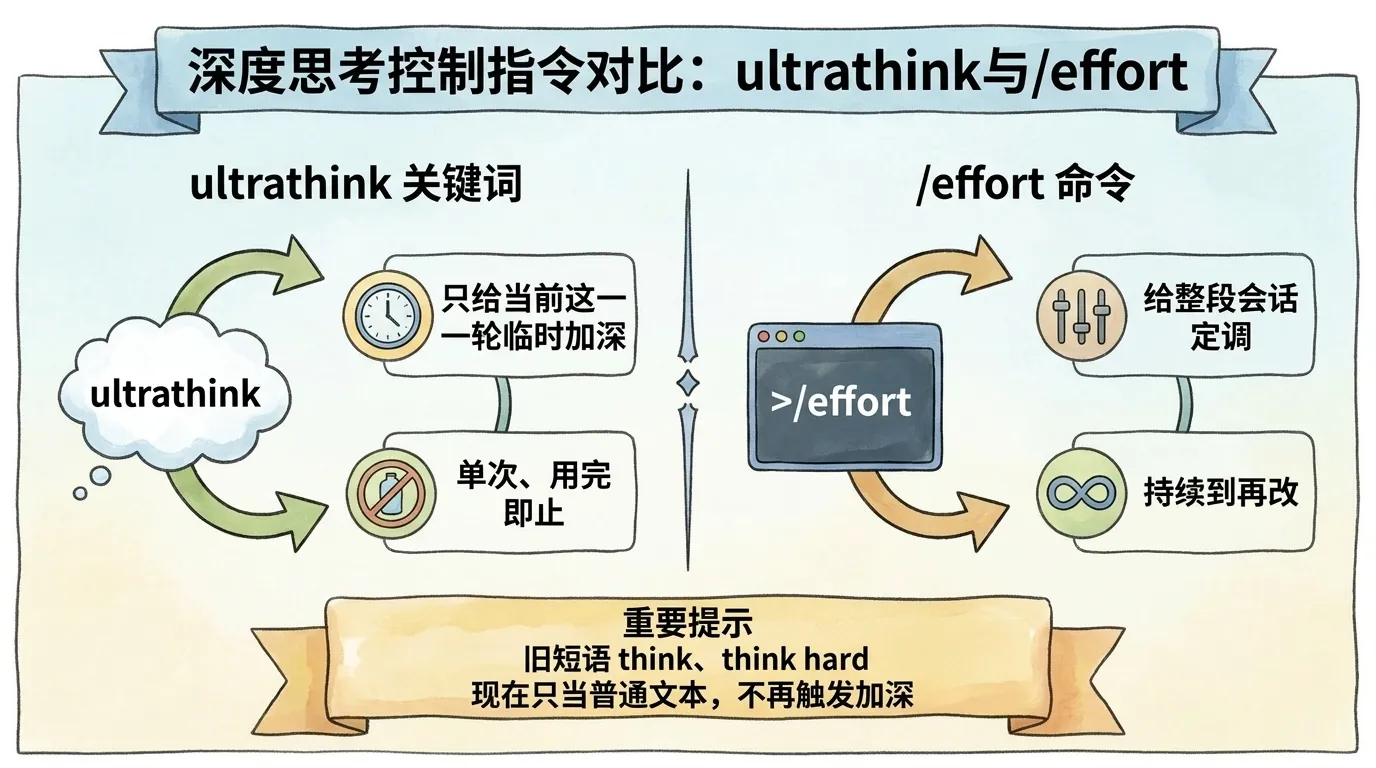
先给结论:ultrathink 关键词仍然有效,但它只给当前这一轮加深推理,不改会话的 effort 档位。 而 think、think hard、think more 这些短语,现在已经不再是触发关键词了。
这一节专门破除旧教程的误解。过去流传一套说法:think 是标准档、think hard 是中档、think harder 接近 ultrathink、ultrathink 给到约三万思考 token,像四级油门一样逐级加深。这套说法已经不成立。 官方现在的机制是:
ultrathink,Claude Code 识别这个关键词,给这一次回答加一条「请更深推理」的上下文指令;但发给接口的 effort 档位本身不变,只影响当前这一轮。think、think hard、think more 等其他短语,现在只当普通提示词文本处理,不被当成关键词——你写「think harder about this」,它就只是字面意思的一句话,不会触发额外推理力度。⚠️ 常见踩坑:照着旧中文教程在提示词里堆
think hard、megathink想逐级加深,结果一点用没有——这些词早已不是触发词。新手最该更新的认知就是这一条:临时加深只认ultrathink一个词,整段会话定调要用/effort,别再迷信关键词阶梯。
那 ultrathink 和 effort 档位是什么关系?可以这样理解:effort 档位是你给整段会话定的基准油门,ultrathink 是某一道难题时临时踩一脚的瞬时加深。两者并存、各管一段。
具体怎么写?ultrathink 放提示词哪个位置都行,被识别就行,比如:
ultrathink 一下:这个鉴权模块要从 session 迁到 JWT,
帮我先列出涉及哪些文件、迁移顺序、以及回滚点,先别改代码。
你不用记复杂语法,把 ultrathink 当成一句普通中文里的提示词混进去即可。下一节讲怎么用 /effort 把基准油门定好。
先回答:第一次动手,别碰复杂配置,先学会两个动作——临时难题加 ultrathink,整段会话定调用 /effort。
建议按这个顺序做:
ultrathink,只加深这一轮。/effort high(或更高)定调;都在做简单活,跑 /effort low 省 token。/effort 的几种设法,挑顺手的用:
/effort:不带参数打开滑块,带档位名直接设(如 /effort high),/effort auto 回到模型默认。/model 里:选模型时用左右方向键调 effort 滑块。--effort:启动 Claude Code 时给单次会话设。CLAUDE_CODE_EFFORT_LEVEL:设档位名或 auto,优先级最高。effortLevel 字段:设 low/medium/high/xhigh(max 和 ultracode 只能临时设、不写进设置文件)。💡 通俗讲:
/effort像汽车的驾驶模式(经济 / 标准 / 运动),定好整段路怎么开;ultrathink像超车那一下踩地板油,只管这一脚。新手先把驾驶模式设对,超车油门以后再说。
这个顺序看着慢,但能避开新手最常见的「什么都 ultrathink」。思考强度应该跟任务风险匹配,而不是跟焦虑程度匹配。
先回答:扩展思考默认开着,你能控制三件事——临时开关、全局默认、以及看不看推理过程。
新手容易把「调档」和「开关思考」混为一谈,其实是两层。effort 档位调的是深浅,下面这几个开关管的是开关和显示:
| 控制项 | 怎么设 |
|---|---|
| 当前会话临时开关思考 | macOS 按 Option+T,Windows/Linux 按 Alt+T |
| 全局默认开关 | 跑 /config 切换思考模式,存为设置里的 alwaysThinkingEnabled |
| 不管 effort 强制关 | 设 MAX_THINKING_TOKENS=0 |
| 看推理过程 | 按 Ctrl+O 切换显示,推理会以灰色斜体出现 |
这里要点出一个容易误用的变量:MAX_THINKING_TOKENS。它是早一代的固定思考预算开关。在走自适应推理的较新模型上,思考改成模型按需分配,固定预算模式不生效,设具体数值没意义。 它现在只剩两个有效用法:一是 MAX_THINKING_TOKENS=0 强制关掉扩展思考;二是在仍支持固定预算的旧模型上先设 CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 回到固定预算模式,这时具体数值(比如 8000)才会按设定生效。哪些模型走自适应推理、哪些还能切回固定预算,以官方当前文档为准。
🔥 翔宇判断:翔宇见过不少人还在照旧教程设
MAX_THINKING_TOKENS=31999想「拉满思考」,在新模型上这其实是白设。日常用最新模型,调思考深浅就认准 effort 档位一条路,别再去碰这个老变量——它现在更多是为兼容旧模型保留的。
要不要把推理过程显示出来?新手值得开一次 Ctrl+O 看看 Claude 怎么想,对建立信任有帮助;看明白了再收起来,省得刷屏。注意:所有思考 token 都要计费,哪怕你折叠不看。
这一节把前面散着讲的机制收成一张对照表,方便你扫一眼就知道某个东西归哪类、管什么。
| 你看到的 | 是什么 | 管什么 | 持续范围 |
|---|---|---|---|
ultrathink(写在提示词里) |
触发关键词 | 给这一轮加深推理 | 仅当前一轮 |
think hard / think more |
普通文本 | 不触发任何加深(已不是关键词) | —— |
/effort high(会话命令) |
effort 档位命令 | 整段会话的推理力度 | 持续到再改 |
--effort(启动参数) |
effort 档位参数 | 单次启动的会话档位 | 该次会话 |
CLAUDE_CODE_EFFORT_LEVEL |
环境变量 | effort 档位,优先级最高 | 看你怎么导出 |
MAX_THINKING_TOKENS=0 |
环境变量 | 强制关闭扩展思考 | 看你怎么导出 |
/config 的思考开关 |
全局设置 | 默认开不开思考 | 持久 |
Option+T / Alt+T |
快捷键 | 当前会话开关思考 | 当前会话 |
ultracode |
Claude Code 设置 | xhigh + 编排动态工作流 | 仅当前会话 |
💡 通俗讲:把这张表当成一张「旋钮地图」。要临时加深,找
ultrathink;要整段定调,找/effort;要彻底关,找MAX_THINKING_TOKENS=0。剩下的暂时不用管。
记住一条主线就不会乱:深浅看 effort 档位,单次加深看 ultrathink,开关看 /config 和快捷键。 其他都是这三类的不同设法。
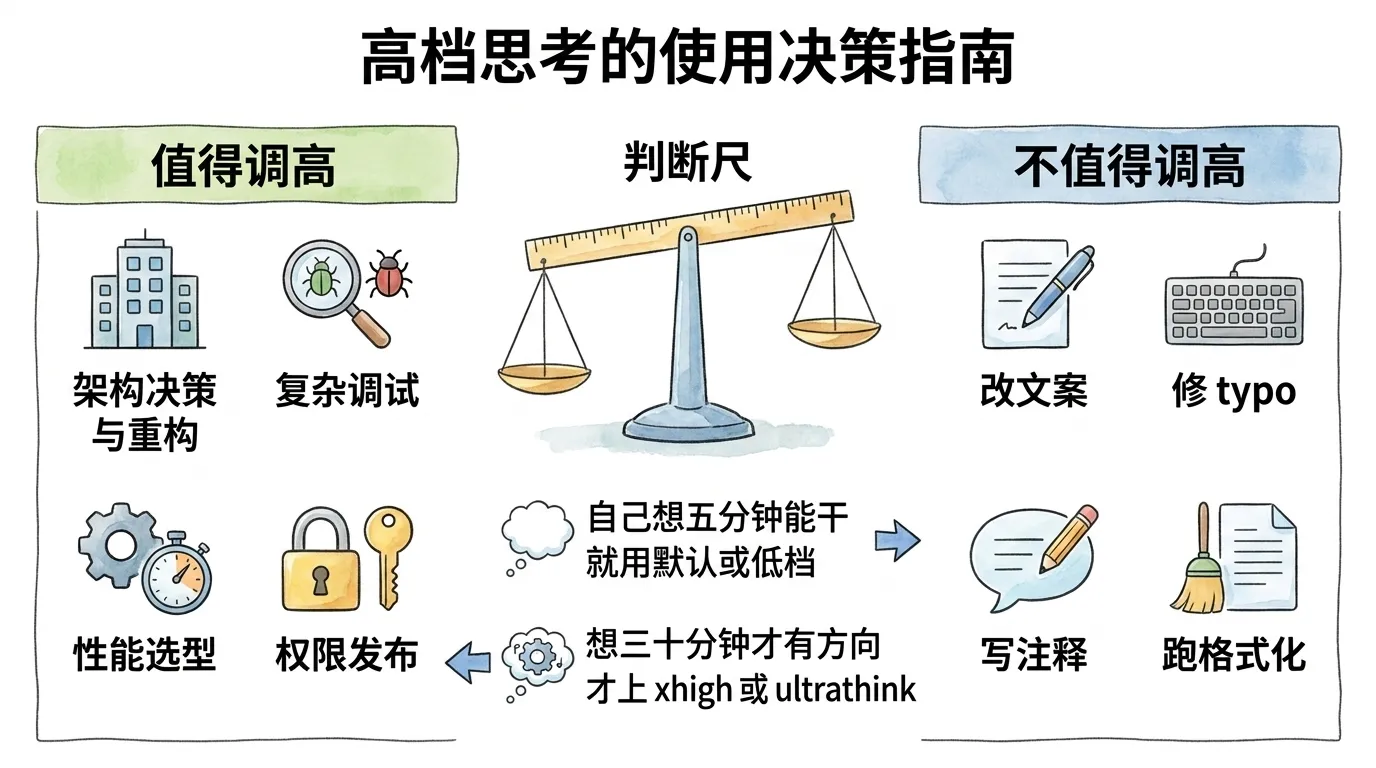
先回答:难、错了代价高、有多方案取舍的活值得调高;明确机械的活用默认或低档。
下面两组场景按官方对档位的定位 + 实际编程经验整理,照着对号即可。
值得调高(xhigh 或临时 ultrathink)的五类活:
| 场景 | 为什么值得 |
|---|---|
| 架构决策(重构 / 迁移 / 选型) | 多方案权衡,错了回滚成本高 |
| 复杂调试(跨多文件、难复现的 bug) | 要追因果链,浅想容易抓错根因 |
| 性能与数据结构选型 | 取舍多,需要比较 |
| 权限、发布这类风险动作 | 影响面大,要先列风险和回滚 |
| 不熟悉的代码区做较大改动 | 先深读再动手,省得改错 |
不值得调高(默认或 low)的五类活:
| 场景 | 为什么不值得 |
|---|---|
| 改文案、改一处明确文本 | 机械操作,深想是浪费 |
| 修 typo、加日志 | 范围窄、风险低 |
| 写文档 / 注释 | 表达类,靠理解即可 |
| 依赖升级、跑格式化 | 流程固定 |
| 重复模式代码(如写 CRUD) | 照搬已有模式 |
给新手一个朴素判断标准:这件事你自己想五分钟也能干,就用默认或低档;想三十分钟才有方向,才值得上 xhigh 或 ultrathink。 把这条记住,你就不用纠结具体档位名,按「我自己要想多久」来选,八成不会错。
判断原则就一句:思考强度跟任务风险匹配,不跟焦虑匹配。简单任务硬上最高档,质量几乎没差,只是更慢更贵。
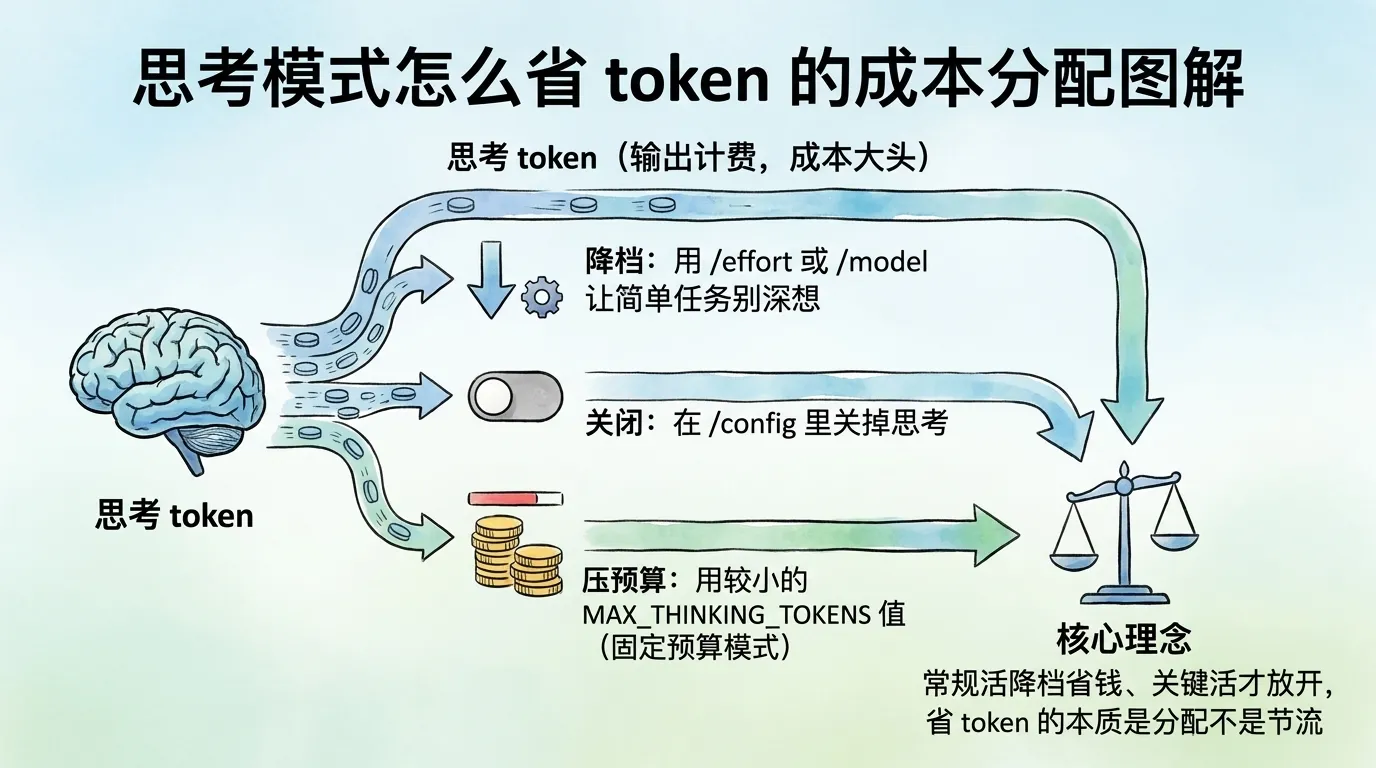
先回答:思考 token 按输出 token 计费、默认预算可能上万,所以它是成本大头,省钱的核心就是「常规活降档、关键活才放开」。
很多新手只关心「想得深不深」,忽略了它直接影响账单。官方给的省钱办法有三条,按好上手程度排:
/effort 或 /model 降档:让简单任务别深想,这是最直接的一条。整段会话都是常规活,跑 /effort low 或 /effort medium。/config 里关掉思考:纯机械批量任务,不需要推理时整体关掉。MAX_THINKING_TOKENS 值压预算:比如 MAX_THINKING_TOKENS=8000,但记住这只在固定预算模式(旧模型或显式关掉自适应推理)下生效。⚠️ 常见踩坑:为了省钱把所有任务都设
low,结果复杂任务质量明显掉,返工反而更费 token。省钱不是一味降档,是让档位跟任务匹配——简单活降、难活放开。一刀切的低档和一刀切的最高档,都是误用。
团队场景可以更进一步:统一一个较低的默认档控住整体成本,只在难任务专属的环境或会话里放开高档。落到具体做法,团队可以在设置文件里把 effortLevel 定成 medium 当统一基线,约定「日常改动用基线、架构和迁移类任务才临时升 xhigh 或加 ultrathink」。管理员还能限制可选模型、统一默认,避免有人一直挂着最贵的组合。想知道思考到底吃掉多少,可以在会话里跑 /usage 看本次的 token 用量和成本估算,心里有数再决定要不要降档。这样既不会让简单活拖慢拖贵,也不会在关键活上省过头。省 token 的本质是分配,不是节流。
说明一下,这是个人路由,不是让你照抄——你的项目类型和我的不一定一样。但这套节奏对大多数新手适用。
翔宇自己面对一个新项目,思考档不会一开始就拧到底,大致按三步走:
high(多数模型的出厂默认),日常编码、问代码、小改动都用它,不另设。ultrathink,比如要重构一个模块、追一个跨文件的 bug,只给那一轮加深,不动会话设置。/effort xhigh 定调,比如一整个下午都在做架构迁移;做完切回默认,不让高档一直挂着。判断「该用单次 ultrathink 还是整段 /effort xhigh」有个简单依据:难题是孤立一道,还是会接连出现一串。 修一个跨文件 bug,难的就是定位那一下,定完后面都是机械改动,用单次 ultrathink 即可;而做一次架构迁移,从拆依赖、排顺序到逐个文件改,每一步都要权衡,这种「连续难」才值得用 /effort 把整段会话定到 xhigh,省得每条提示词都补关键词。
一条实战经验:max 和 ultracode 这种最高档,一年也用不了几次,多数所谓「难题」用 high 加一次 ultrathink 就够了。还有一个反直觉的体感——档位调太高,有时反而更难用,因为模型会在一个本来不复杂的点上反复权衡、给一堆你不需要的备选,读起来更累。这正是官方说 max 容易「过度思考」的实际表现。更要警惕一种心态——为了「看起来认真」给每个任务都加深思考,短期觉得稳,长期就是更慢更贵。能让你少犯一个真实错误的档位,才值得调高。
这套节奏跑顺以后,你对「该深还是该浅」会有体感,不用每次都查表。在那之前,先按「默认 + 单次 ultrathink + 难活整段 xhigh」三档走,足够覆盖绝大多数场景。
思考模式用错,多半不是机制太难,而是判断没对上。把这五个坑记住,能避开大多数误用。
| 坑 | 正确做法 |
|---|---|
还在堆 think hard / megathink 想加深 |
这些已不是关键词,临时加深只认 ultrathink |
| 简单任务也设最高档 | 按任务风险选档,简单活用默认或 low |
| 把「想久」当质量保证,不补需求 | 先写清目标和验收,再决定要不要加深 |
在新模型上设 MAX_THINKING_TOKENS=31999 |
新模型用自适应推理,这数值无效,改调 effort 档 |
| 高档思考后直接全自动执行 | 高档只提高判断质量,仍要跑测试、看 diff、验证 |
⚠️ 常见踩坑:最隐蔽的一个坑是把深度思考当成免验收的护身符。Claude 想得更久,也可能遗漏测试、误判依赖、忽略你的限制。高档思考提高的是判断质量的机会,不替代验证。该跑测试、看 diff、检查边界的时候,仍然要做。
这五个坑里,前两个是认知没更新(还停在旧教程),后三个是把工具当魔法。两类都靠一句话破解:思考模式让该慢的地方慢下来,不让你跳过自己的判断和验收。
先回答:新手前两周只要把「默认 + ultrathink + /effort」三件事用顺,再往后才看团队统一、成本统计和跨工具对比。
可以按三个阶段给自己定节奏:
ultrathink。先把这个反射建立起来。/effort 给整段会话定调,并观察账单变化,感受不同档的成本差。xhigh),用 /usage 看思考占用的成本占比。到这一步,思考模式就从「一个旋钮」变成了「一套和成本、质量挂钩的工作习惯」。
再往深走,可以了解交错思考(interleaved thinking)这个能力。它指 Claude 不只在回答前思考,在一次次工具调用之间也能停下来想一想——读完一个文件、跑完一条命令后,先想想下一步再动手,而不是机械地按计划走完。这对多步骤任务很关键:跨文件调试、按计划逐步迁移这类活,中途往往要根据上一步的结果调整方向,交错思考让模型能边做边纠偏。对新手来说,你不需要专门配置它,知道「高档思考 + 多步任务时,模型会在工具调用之间也动脑」就够了——这解释了为什么难任务用高档时,它的每一步看起来更有章法。真正要细抠这些能力的开关,等你把前面三件事用顺再说。
动手前后,拿这张清单过一遍,能避开大多数误用:
ultrathink,而不是已失效的 think hard?/effort 定了调,而不是每条提示词都加关键词?下面几条是正文没专门展开的边角问题,正文讲透的「effort 怎么选、ultrathink 现在还有没有用」就不在这里重复了。
我设了 xhigh,可机器好像没按 xhigh 跑,为什么?
多半是当前模型不支持这一档。遇到不支持的档,Claude Code 不会报错,而是自动落到它支持的、不超过你所设值的最高档。想确认实际生效的档,看 logo 和加载提示旁边的标注(如「with low effort」),或重开一次 /effort。
/effort auto 和直接设一个档有什么不一样?
/effort auto 是把档位重置回当前模型的出厂默认,等于「不手动指定,交给模型默认」;直接设档位名(如 /effort low)则是你显式压一个值。换模型后想回到那个模型该有的默认体验,用 auto 最省事。
能不能给某个 Skill 或子智能体单独设一个思考档?
可以。在 Skill 或子智能体(subagent)的 markdown frontmatter 里写 effort 字段,它运行时就按这个档跑,覆盖会话级设置——但仍盖不过环境变量 CLAUDE_CODE_EFFORT_LEVEL。适合让某个固定干重活的子智能体常驻高档,而主会话保持低档省钱。
几种设 effort 的方式同时存在时,谁说了算?
优先级从高到低:环境变量 CLAUDE_CODE_EFFORT_LEVEL > 你配置的档(设置文件 / /effort / --effort)> 模型默认。Skill 或子智能体 frontmatter 的 effort 在它们运行期间覆盖会话档,但同样盖不过环境变量。记不住就一句:环境变量最大。
折叠不看推理过程,是不是就不花思考的钱了?
不是。所有思考 token 都计费,哪怕你用 Ctrl+O 把它折叠起来不看、或接口把它做了删节。省钱要靠降 effort 档或关思考,靠「不看」省不了。
你现在只要带走三句话:
/effort 定调,默认 high 多数够用,难活才上 xhigh。ultrathink 一个词。其他 think hard 之类已失效,别再堆。如果要继续学,建议先把 Claude Code 的整体能力地图补上,再回头看思考模式怎么和别的功能配合:
同系列下一步:
机制和参数的细节,以官方文档为准:
最后提醒一句:思考模式的价值不在于让回答显得复杂,而在于让该慢的地方慢下来、该快的地方保持快。先判断任务难度,再选档,比记住每个档位名重要得多。
📚 更多 Agent 编程方法论:Agent 编程方法论:不教工具教方法,让 AI 按你的规矩干活
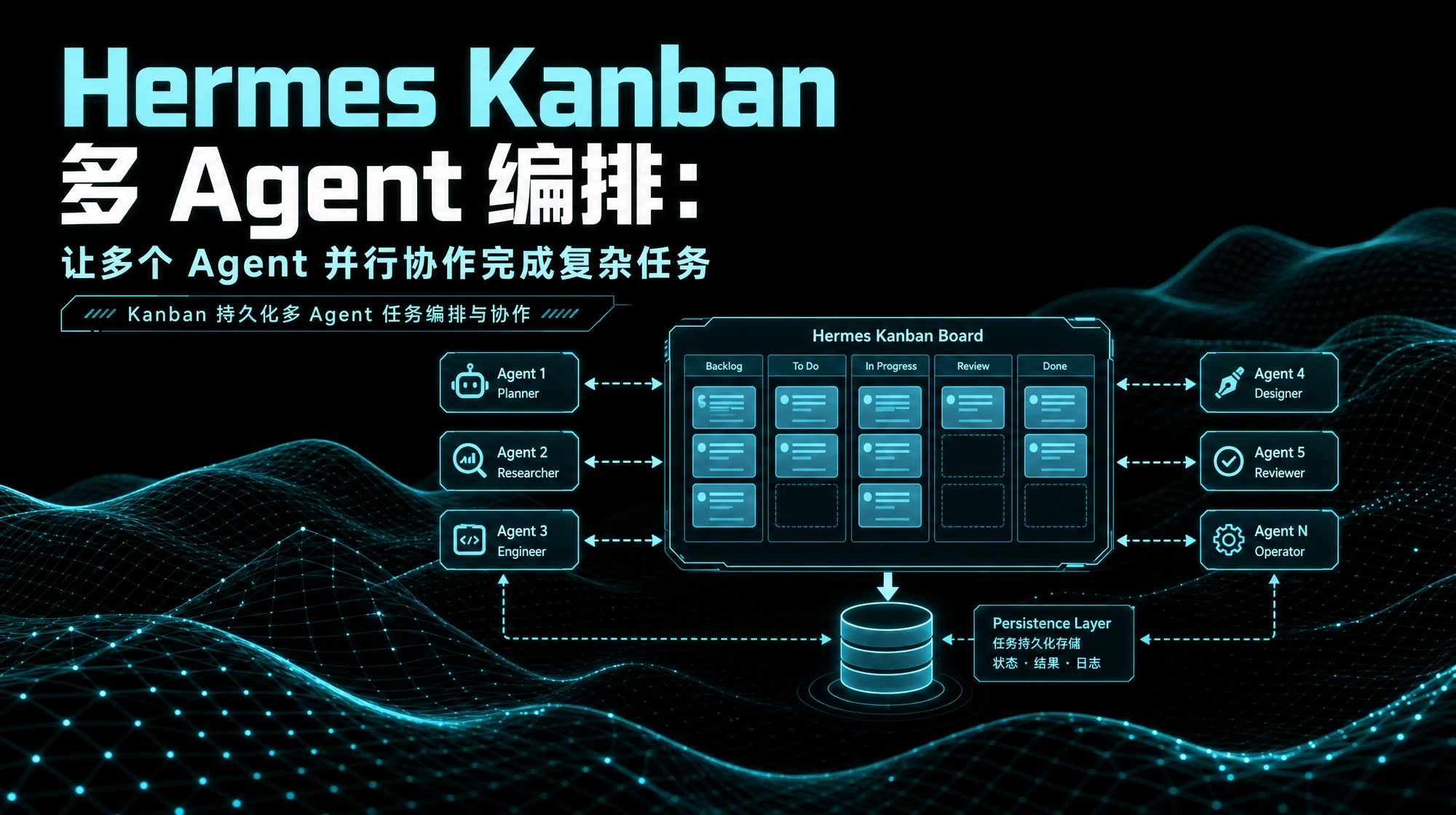
Hermes Kanban 是一块持久化任务板,多个命名 Agent 在上面认领、执行、交接工作——跨进程、跨重启、可追溯。本文拆解六列看板机制、九种协作模式、delegate_task 子代理委派、五种委派模式、Kanban Codex Lane、Orchestrator 铁律,以及四个用户故事的完整实操步骤,附 8 问 FAQ。
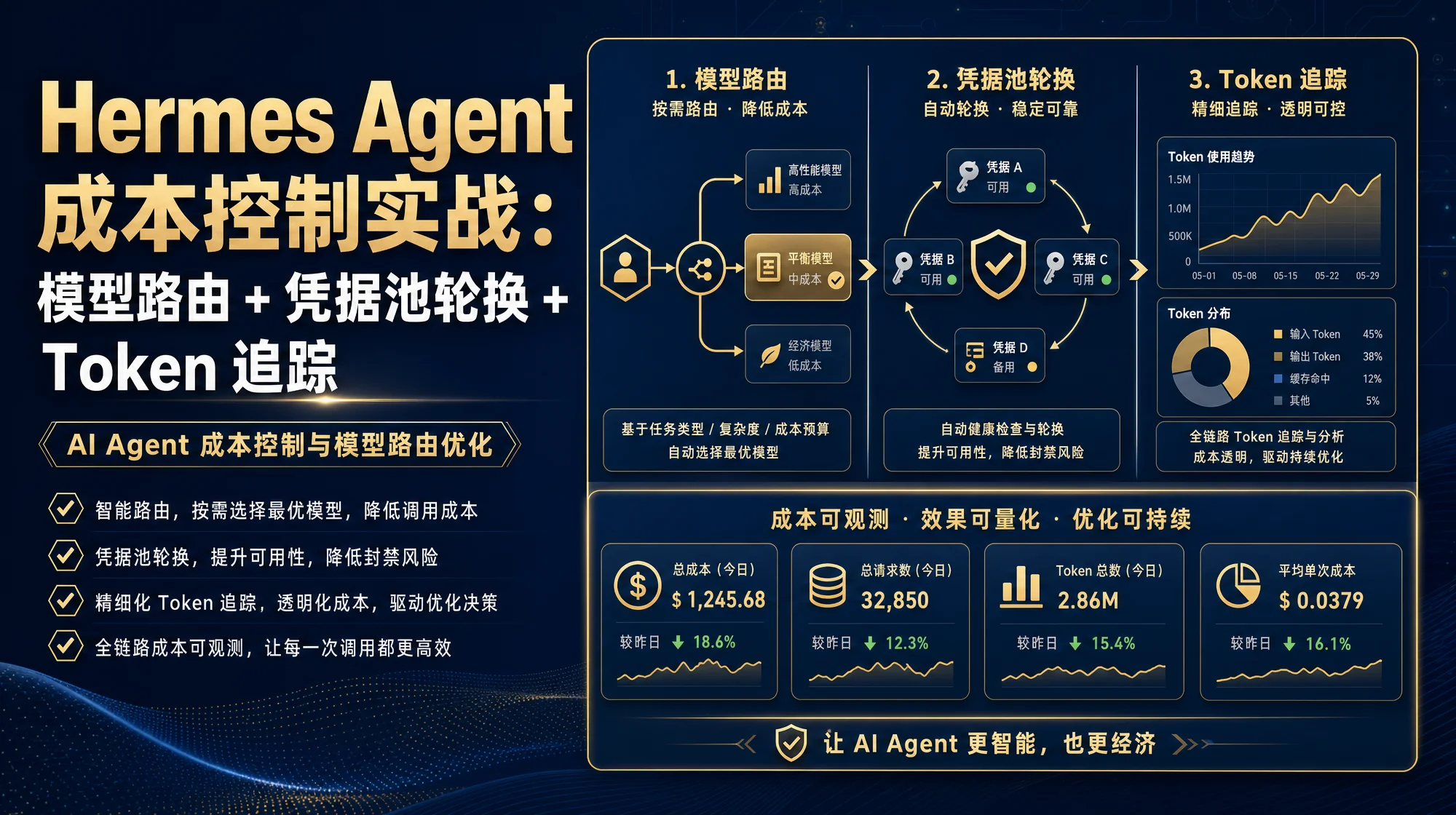
一套系统化成本控制方案,把 Hermes Agent 月费从 $200 压到 $5 以下:Provider Routing 六种排序策略、Credential Pools 四种轮换策略、三层韧性降级链、辅助模型独立配置防压缩风暴、Tool Search 延迟加载省 89% Token、execute_code 中间结果不入上下文——附翔宇五台机器实战 config.yaml 完整配置。
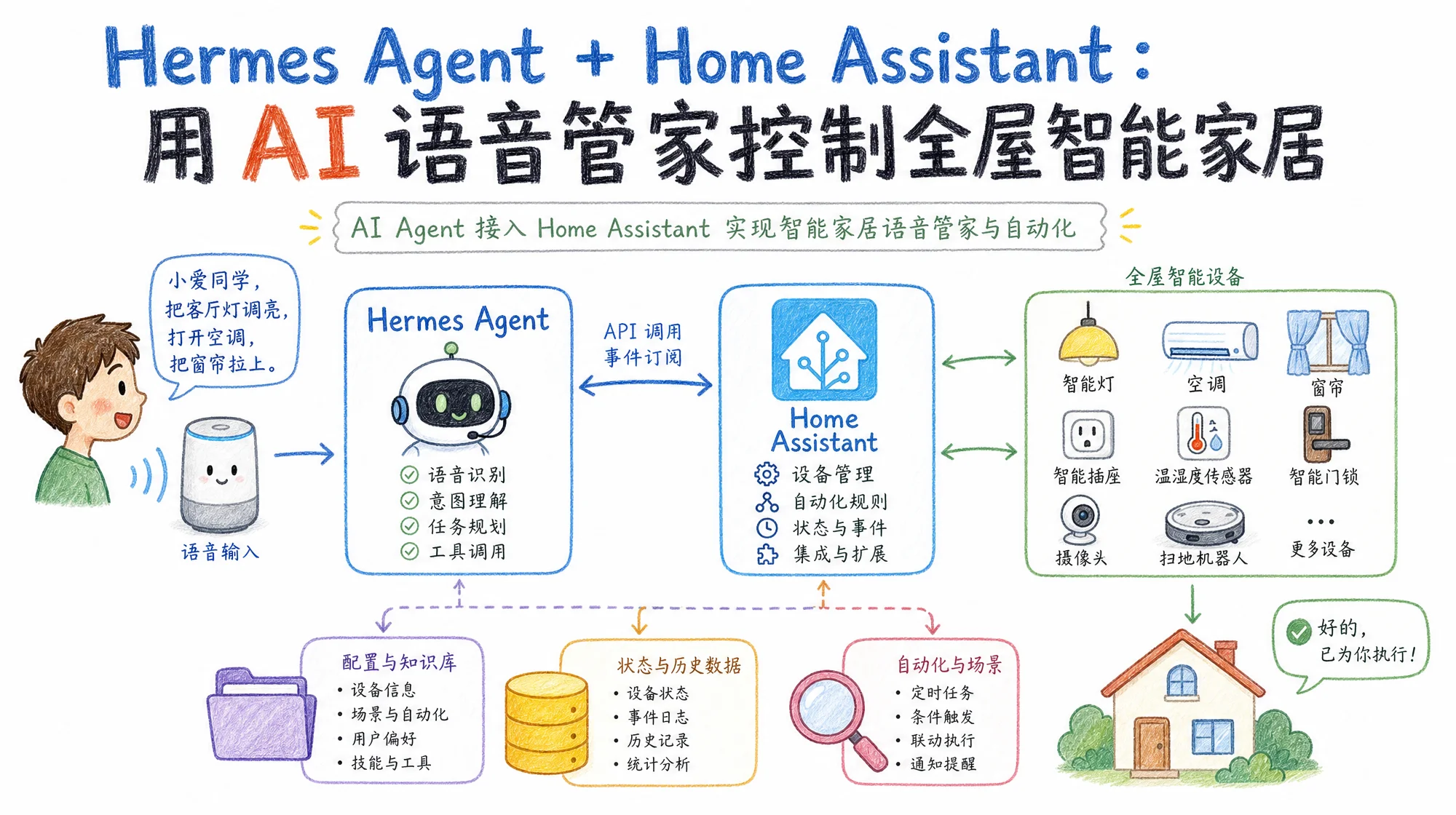
Hermes Agent 内置四个 Home Assistant 工具,一个 Token 激活全部能力:REST API 主动控制设备 + WebSocket 实时监听事件 + 语音往返 + Cron 定时自动化。本文覆盖两种接入模式、ha_* 工具集详解、语音控制完整流程、Apple 生态联动、米家设备桥接、竞品对比和 8 个常见问题。

Hermes Agent 支持三种本地推理后端:Ollama 一键启动、LM Studio 可视化管理、vLLM 生产级吞吐。本文覆盖完整接入配置、64K 上下文铁律、模型选型矩阵(按硬件/任务/语言推荐)、社区高频痛点解决方案,以及翔宇 GLM→DeepSeek→Gemini 三模型实战策略。
每周精选 AI 编程与自动化实战内容,直达你的邮箱