Claude Code + Hermes MCP 消息桥接实战:任务完成自动通知手机
Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
向量数据库太重、RAG 管线太脆——用 CLAUDE.md 多级路由 + 纯文件系统,从零搭建一个 AI Agent 能直接读懂的知识库。本文拆解 1000+ 文件规模的真实架构,给你一套可直接抄作业的方案。
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
写给第一次用 Codex 做项目的人:从 Codex 为什么会干偏倒推,讲清上下文是什么、真正该管好的两层是哪两层、哪些资料该给、哪些噪音别塞进去。

预计阅读 15 分钟。这篇不打算让你背「上下文工程」(context engineering)这个词,而是反过来问一个更实在的问题:Codex 为什么会突然干偏?把这个原因拆开,你自然就知道该给它哪些信息、又该少给哪些信息。
这篇尽量少用代码讲。新手真正需要的不是一堆配置项,而是一种整理任务的感觉:哪些话要提前说,哪些文件要让它看,哪些噪音不要塞进去。需要上手的地方,我也会把关键命令直接给你。
你让 Codex「帮我修一下登录有时候失败的问题」,顺手把整个 src/ 目录拖了进去,又补了一句「对了顺便把日志里那些警告也清一清」。它跑了一阵,改了七八个文件:登录那段没真正动,倒是把一个无关模块的告警注释删了个干净,还顺手改坏了一处你没让它碰的配置。你心里一沉:昨天它还像个高手,今天怎么像没睡醒。
这不是模型今天「状态不好」。问题出在你给它的上下文上——目标含糊(什么叫「修好」没说)、边界缺失(哪些不能动没说)、材料过载(一整个目录全塞进去,真正相关的两三个文件被淹没)、还塞了一件「顺便」的任务把注意力扯散。Codex 不是读心术,它只在你给它的那张「桌面」上做判断。桌面乱,结果就乱。
这篇就从这个现场往回倒推:先看清 Codex 是怎么一步步被带偏的,再反过来推出该怎么喂信息。上下文工程(context engineering)说到底就一句话——让 Codex 拿到刚刚好的信息去干活,少了它只能猜,多了它会被淹没。
下面这张表按你的身份,告诉你这篇该重点看哪里。
| 你是谁 | 最常卡在哪 | 先看哪一节 |
|---|---|---|
| 第一次用 Codex 做项目 | 不知道上下文是什么、该给什么 | § 一、§ 三(上下文怎么分层) |
| Codex 忽聪明忽糊涂 | 同一个工具时好时坏 | § 二、§ 十一(跑偏先查什么) |
| 听说过大窗口但不会用 | 窗口多大、为什么塞满反而变笨 | § 七(窗口与上下文衰减) |
| 想系统建一套喂料纪律 | 多任务、长会话管不住 | § 三、§ 八、§ 十二 |
整个翻车现场里最常见的那个错误,先说在前面:把所有能想到的资料一次性全塞给 Codex。这恰恰是上下文工程最反对的做法——信息不是越多越好,是越准越好。
你可以把 Codex 想成一个坐在你旁边的工程师。它干活前,桌上会放几类资料:公司规矩、项目说明、你这次交代的任务、它刚刚看过的文件、命令跑出来的结果。它写得准不准,很大程度取决于桌上这些资料是不是刚好。
资料太少,它只能猜。你说「帮我修一下登录问题」,但没告诉它入口文件在哪里、错误长什么样、什么叫修好,它就只能在仓库里摸索。资料太多,它会被淹没。你把十几个文件、几千行日志、好几段背景一次丢进去,它未必知道哪一句最重要。
上下文工程说白了,就是帮 Codex 整理桌面。不是把所有资料都堆上去,而是把这次任务真正需要的东西放在最显眼的位置。
💡 通俗讲:上下文不是「Codex 的记忆」,而是「它此刻能看到的桌面」。你给什么、它看什么;桌面乱,它就乱。
这个动作听起来普通,但会直接影响结果。有一个反直觉的事实值得记住:在 SWE-bench 这类编程评测里,同一个模型、同一套题,换一套更好的「信息组织方式」(业界叫 harness,脚手架),成功率能明显拉开。独立机构 Epoch AI 的对照实验就发现,光是给同一个模型换脚手架,得分就能差出可观的一截,而它点明「脚手架的选择对整体表现的影响最大」。换句话说,怎么喂上下文,有时候比换一个更强的模型还重要。
把这件事做到极致是什么样?据 OpenAI 公开分享,他们有个内部团队从一个空仓库起步,用 Codex 做出了一个百万行代码量级的产品,源代码没有一行是人手写的(连指挥 AI 干活的 AGENTS.md 都是 Codex 写的),人主要负责掌舵、定约束、搭反馈环。他们工程师的工作不再是敲代码,而是设计「能让 AI 可靠写对代码的环境」——这套环境,本质就是上下文工程的放大版。新手不必做到这一步,但方向是一样的:你管的是「给 AI 什么信息」,不是「替 AI 写答案」。
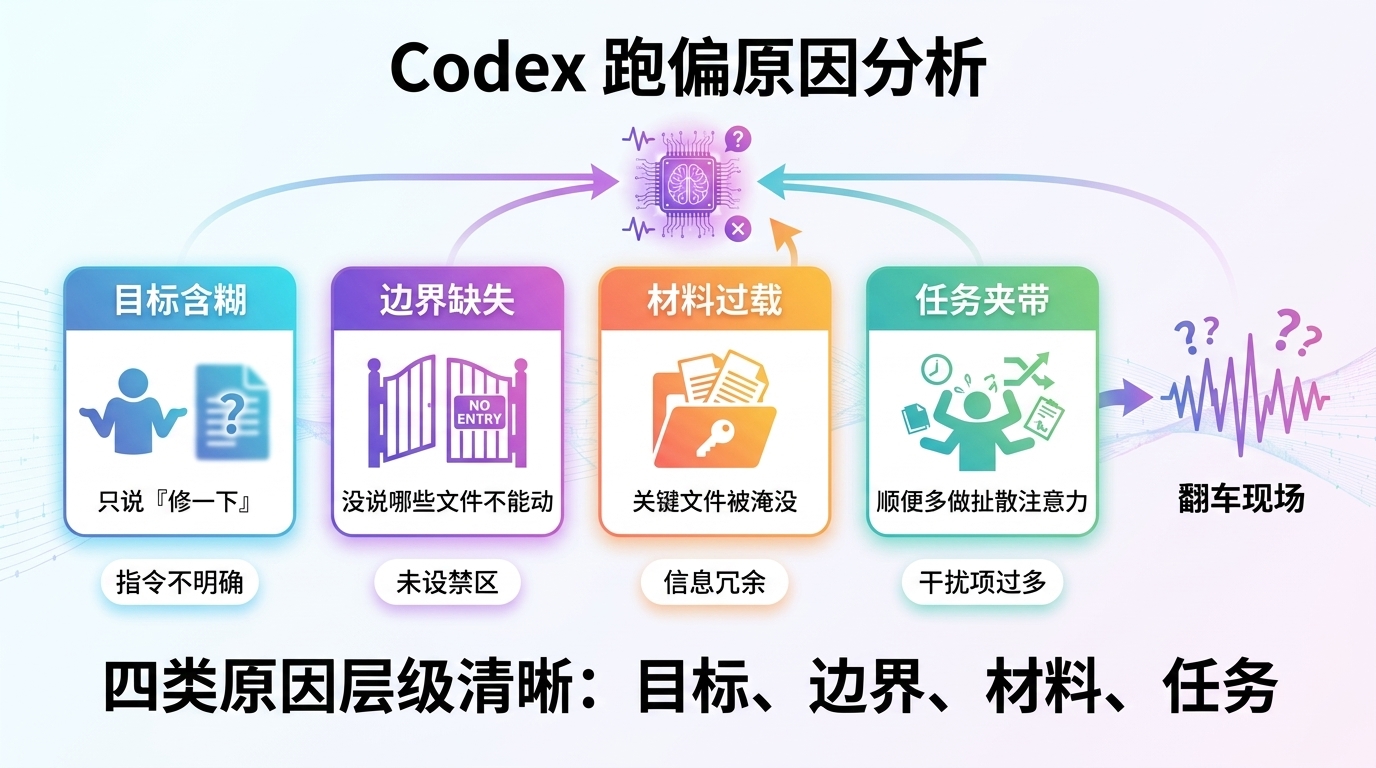
回到开头那次翻车。把它拆开,你会发现 Codex 跑偏几乎都落在四个原因上,而且每一个都对应你能补的一类信息:
这不是责怪用户,新手本来就很难一上来就知道该喂多少信息。但你需要先建立一个简单直觉:Codex 不是读心术,它只在当前上下文里做判断,当前上下文乱,结果就容易乱。
把它当成一次交接会更好理解。你交接给同事时,不会把整个电脑桌面都倒给他,也不会只说「你看着办」。你会告诉他现在问题是什么、先看哪份材料、不要动哪里、做完怎么确认。给 Codex 也是同一个逻辑。后面几节,就是把这四个原因逐个补回去。

Codex 桌上的资料不是一团乱麻,而是分层的,从「最稳定、最不该乱动」到「最临时、用完即弃」大致是这样:
| 层 | 管什么 | 谁来写 | 持久度 | 新手要不要操心 |
|---|---|---|---|---|
| 系统提示词(System Prompt) | Codex 的基本行为底色 | OpenAI 内置,你看不见也改不了 | 永久 | 管不到,不用操心 |
AGENTS.md(项目规则) |
项目级规则,每次对话自动加载 | 你写 | 跨会话长期 | 重点,亲自盯 |
| Skills(技能) | 可复用的工作流,需要时调用 | 你定义 | 按需 | 进阶,后面再碰 |
| 会话级上下文(Session) | 这次的提示词、@ 引用的文件、命令输出 |
当前对话 | 单次会话 | 重点,亲自盯 |
| 长期记忆(Long-Term Memory) | 跨会话保留的项目偏好与决定 | 桌面应用支持,CLI 暂未原生 | 跨会话持久 | 进阶,后面再碰 |
别被「五层」吓住,也不用平均用力。看最右一列就够了:系统提示词你管不到,Skills 和长期记忆是进阶项,新手真正要亲自盯紧的只有两层——AGENTS.md(长期项目规则)和会话级上下文(这次任务怎么交代)。回到 § 二那四个翻车原因,会发现它们全落在这两层里:目标、边界、材料、夹带,要么属于「这次怎么交代」,要么该沉淀进「项目规则」。把这两层喂对,大部分跑偏就没了。
这也是为什么本文把篇幅压在这两层上:§ 四专讲 AGENTS.md 怎么写,§ 五到 § 六、§ 九到 § 十专讲会话级上下文怎么交代任务、给文件、给命令输出。Skills、窗口、长期记忆这些进阶层,放到后面用更短的篇幅说清边界即可。
🔥 翔宇判断:同样是「沉淀经验」,我认为
AGENTS.md比长期记忆更值得新手先花力气——它每次对话都自动生效、覆盖面最广,而长期记忆这类层在 CLI 上还没原生支持。先把这两层做扎实,再去碰窗口、记忆这些进阶问题,顺序对了会省很多事。
这两层里最常见的混乱,是把临时任务写成长期规则。比如今天你说「这次不要跑测试」,它本该只在今天生效;可你要是把这句话沉淀进项目规则,下次它可能真的不测了。上下文工程不是只会加信息,也要知道信息什么时候该消失。
很多新手第一次写 AGENTS.md,会把所有想到的要求都塞进去。回答风格、测试命令、目录解释、历史教训、临时任务、个人偏好,越写越长。刚开始看着很安心,过一段时间就变成杂物间。
这里有个容易被忽略的事实:指令不是写越多越管用。HumanLayer 团队在公开的《Writing a good CLAUDE.md》里给出过一个很有用的判断依据:当前前沿的「会思考」的大语言模型,大约能比较可靠地遵循 150 到 200 条指令,而代理自带的系统提示词本身就已经用掉了大约 50 条(来源)。也就是说,留给你写项目指令的预算并不大——写太长,AI 反而会开始漏掉其中一些。顺带一提,HumanLayer 自己的根目录配置文件就控制在 60 行以内。
照这个预算反推,AGENTS.md 控制在几十行到两三百行通常就够,再往上多半是在「为了写而写」。新手起步先写一个精简版,跑一两周,根据 Codex 反复犯的错再加规则。每加一条前先问自己:这条比已有的哪一条更重要?如果不能替换掉旧的,就别加。
那 Skills(技能)和 AGENTS.md 怎么分工?AGENTS.md 是「每次都生效的项目铁律」,Skills 是「需要时才调用的固定流程」。Vercel 在公开评测《AGENTS.md outperforms skills in our agent evals》里给出过一个反直觉的对照:把文档直接嵌进 AGENTS.md(每次自动加载),通过率到了 100%;而靠 AI 自己决定要不要去读的 Skill,默认配置下通过率只有 53%——和完全不给文档的基线几乎一样(来源)。
⚠️ 常见踩坑:很多人把高频要用的规则塞进 Skill,指望 Codex 自己想起来去读。结果它经常不读。高频、每次都该生效的内容应该进
AGENTS.md;Skills 更适合「不总是需要、但需要时要走完整流程」的场景,比如某个固定的发布流程。
项目规则最适合写三类内容:长期不变的项目背景、必须遵守的工作方式、固定的验证命令。比如「进入这个目录先读哪个文件」「改完必须跑哪个脚本」「哪些目录不要碰」。临时判断不要放进去——「今天先处理 A 文件」「这次不用发版」这种,留在当前对话就好,任务结束它们就该消失。
一个很简单的判断标准:如果下个月还应该遵守,就写进项目规则;如果只为今天服务,就留在这次对话;如果只是你刚才的想法、还没验证,就先别写进任何固定文件。
你给 Codex 发任务时,不需要写长作文。真正关键的是三件事:目标、边界、验收。
目标是你要它完成什么。不要只说「优化一下」,要说「把这篇文章改成新手能听懂,减少代码和术语堆叠」。边界是它不能做什么。比如「不发布到 Ghost」「一次最多改三篇」「不要动已发布文章正文」。验收是怎样算完成。比如「正文里重复模板段落清零,FAQ 不再机械复读,中文字数仍达标」。
这三件事说清楚,Codex 就少猜很多。你不需要把所有背景都补完,只要先把任务的方向、范围、完成标准钉住。
很多失败不是因为提示词不够高级,而是这三件事缺了一件。没有目标,它会发散;没有边界,它会越界;没有验收,它会不知道什么时候停。你把这三件事写清楚,哪怕语气很普通,也比一大段漂亮但模糊的话更有用。
新手常犯的一个错,是把整个目录都丢给 Codex。看起来很放心,实际很容易稀释重点。它当然可以搜索文件,但你让它一次面对太多材料,它也需要判断哪份重要。
更稳的做法是先给一到三个关键文件。比如让它改文章,就给目标文章、写作规范、同类优质样例。让它修 bug,就给报错、相关代码、测试文件。让它做审查,就给变更文件和标准。
这里要专门讲一下 @ 文件引用。在 Codex 里用 @文件名 引用一个文件,它会把这个文件的完整内容读进当前会话——不是装样子,是真读,你能看到它后续输出会引用文件里的具体函数名、变量名。但正因为是「完整读入」,有三个常见误用:
⚠️ 常见踩坑:① 引用一个上万行的大文件,会瞬间吃满窗口;② 引用「整个目录」(比如
@src/),让 AI 自由挑,它挑的往往不是你想要的;③ 引用之后又打一大段字,前面@进来的重点反而被你后面的话稀释了。正确做法是:引用 1 到 3 个具体相关文件、大文件先用关键词抽出相关片段再引、引用后只说一句简短目标。
如果它发现还缺信息,再让它自己查。这样上下文会一层层展开,而不是一开始就把桌面铺满。你还能看到它为什么要查新文件——它说「我需要看测试文件确认预期」,你就知道这一步合理;它如果突然打开一个无关目录,你也能及时拉回来。
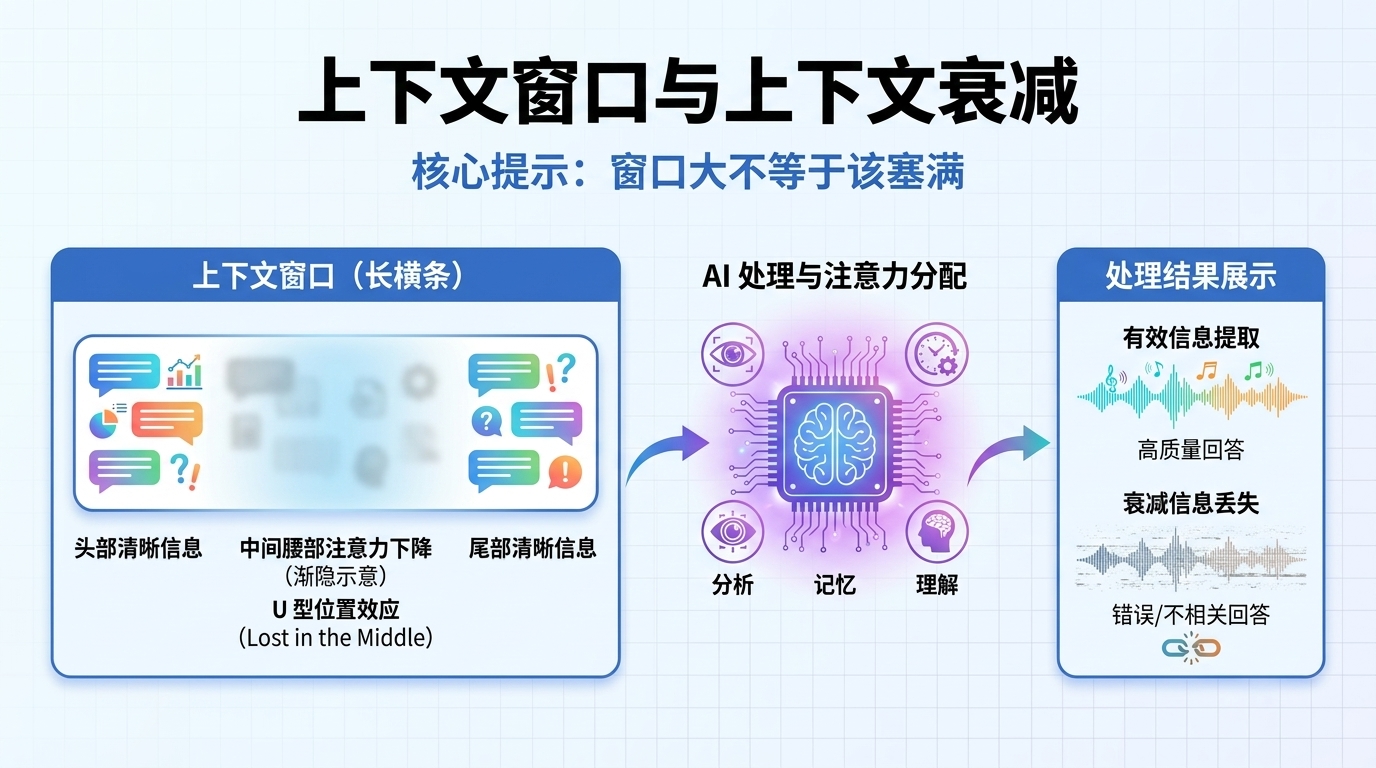
聊到这里就绕不开一个新手最爱问的问题:Codex 的上下文窗口到底有多大?
答案分两层。第一层是「上限」:窗口上限随模型版本变化,具体数字以官方当前文档为准,新手不必把某个版本对应多少 token 记死——这类数字几个月就会变一轮。Codex 确实给了你手动调窗口的能力:在 ~/.codex/config.toml 里有一个 model_context_window 配置键(官方配置文档里有这个键和示例),需要时可以按官方说明设置。
第二层、也是更要紧的一层是:窗口大不等于你该塞满。这里要讲一个关键概念——上下文衰减(context rot)。它说的是:当你往窗口里塞的内容越来越多,模型对「中间位置」信息的注意力会下降,头部和尾部记得清楚、腰部容易丢。这不是 Codex 的 bug,是大语言模型共有的特性,业界常叫它「lost in the middle」(迷失在中间)。斯坦福等机构 2023 年的论文《Lost in the Middle》就实测到这种「U 型」位置效应:相关信息放在中间时,模型的表现会明显下滑,而且上下文越长、整体越容易掉。新模型在这件事上有所改善,但「越长越要当心」的方向没变。
🔥 翔宇判断:再大的窗口也不是「让你随便塞」的邀请,而是「装得下完整材料」的余量。我自己的做法是按任务复杂度分档喂,而不是有多大塞多满——
| 任务复杂度 | 上下文控制建议 |
|---|---|
| 日常单点任务 | 尽量精简,只给当前这件事相关的材料 |
| 跨多文件的复杂任务 | 仍可控,但要主动挑相关文件,不要整目录拖 |
| 超大、跨度极长的任务 | 拆成多个独立子任务,每段开新会话 |
⚠️ 常见踩坑:把上下文窗口当仓库用,看到窗口大就一次性把整个项目、所有日志、几轮历史对话全塞进去。结果不是 Codex「记得更多」,而是它在一堆噪音里找不到那一句真正关键的话。窗口大只代表能装下,不代表每一句都会被同等认真地处理。
真正好用的上下文,不是每次都重新解释一遍,而是把反复出现的经验放到稳定位置。比如某个项目总是需要先跑一个脚本,某个目录不能直接改,某个发布流程必须先生成预览,这些都值得沉淀。
但沉淀不是复制粘贴。不要在 AGENTS.md、README、任务说明、个人备忘里写四份同样的规则。写多了以后,早晚会有一份过期。到时候 Codex 看到互相冲突的规则,还不如没看。
这里也要说清 Codex 的「长期记忆」到底能记住什么。Codex 的桌面应用支持持久的项目记忆——同一个项目下的多个会话之间,能保留你之前告诉它的偏好、踩过的坑、做过的决定。但 Codex 的命令行版本(CLI)当前还没有原生的长期记忆,每开一个新会话上下文都会重置。
💡 通俗讲:CLI 没原生记忆,但你可以用
AGENTS.md当「类记忆层」——把要长期记住的事手工写进去,它每次都会自动加载,效果接近一个简易记忆。新手起步靠这一招就够用了,不必急着上第三方记忆系统。
我的建议是:长期规则只放一个权威位置,任务说明只引用它,不重复展开。上下文工程的成熟感,很多时候来自「少而准」,不是「多而全」。这也是团队协作里最省心的做法——大家都知道该看哪里,Codex 也知道该信哪份文件。
很多人忽略这一点:命令输出也是上下文。你跑了一个很长的日志、一个巨大的测试报告、一个满屏依赖树,Codex 都可能把它当成材料。材料越多,重点越容易被冲淡。
所以给命令输出也要节制。失败时给关键错误,不要一上来贴几千行。需要搜索时先用关键词定位,再给相关片段。测试失败时先看第一个真实错误,不要把所有连锁失败都当成同等重要。
你要训练的是一种习惯:先让 Codex 看证据,而不是看噪音。比如测试失败时,先给第一个失败用例和相关堆栈;文章审核时,先给目标稿和检查标准;功能开发时,先给入口文件和预期行为。你越能把证据缩小到关键处,Codex 越容易给出像样的判断。
还有一个长会话里特别实用的动作:/compact。长会话会不断累积「会话级上下文」(你的所有提问 + AI 的回应 + 工具调用结果),堆到一定量之后注意力就开始分散。/compact 会让 Codex 把之前的对话压成一份摘要,腾出空间继续干。
⚠️ 常见踩坑:反复
/compact会丢细节(摘要会越压越糙)。我的习惯是:跑完一个明确子任务就/compact一次,比放任上下文自然膨胀好;但真正复杂的多轮任务,还是「换新会话 + 自己手写一句摘要」更可控。
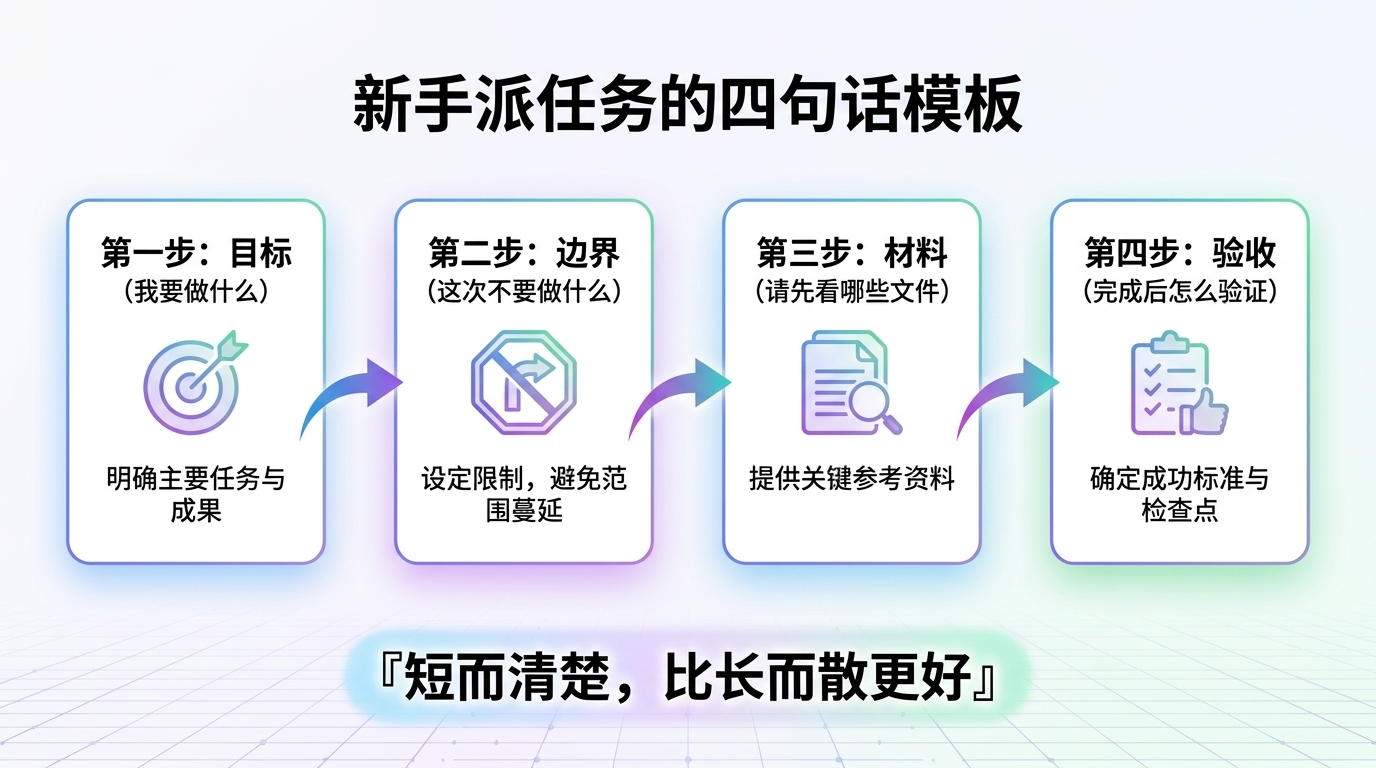
你可以用很朴素的四句话,不需要复杂模板。
第一句:我要做什么。第二句:这次不要做什么。第三句:请先看哪些文件。第四句:完成后怎么验证。
比如:「请把这篇 Claude Code 教程改得更适合新手,不要增加大段代码,不要发布。先看目标文章和写作规范。完成后检查重复段落、FAQ 语义、中文字数和本地链接。」
这几句话听起来普通,但已经包含了目标、边界、材料和验收。Codex 最怕的不是短任务,而是模糊任务。短而清楚,比长而散更好。
如果你怕它理解错,可以再加一句「先说你准备怎么做,再动手」。这句话能让你在它开始改文件之前看到路线。路线不对,你可以立刻纠正;路线对,再让它继续。这一步对新手很友好:你不用等它改完一堆文件才发现方向错了,先看路线,就像出发前看导航,路线不对,停车调整成本最低。
绕了一圈,回到开篇那次翻车。看到 Codex 跑偏,先别动「换个更强模型」的念头,先把 § 二那四个原因当成排查清单挨个对一遍:
开篇那次翻车,四条几乎全中。这四个问题比「要不要换更强模型」更基础:换模型能缓解一部分能力问题,但只要上面这四件没说清,再强的模型也是在一张乱桌面上做判断,照样会偏。
更关键的是,如果你每次出错都先换模型,很容易错过真正的原因——今天是目标不清,明天是边界没写,后天是日志太长。你以为自己在调模型,其实是在用更强的模型掩盖交接问题;而交接问题不解决,再强的模型也会重复栽在同一个坑里。模型是你最后才去动的那一层,不是第一层。
你现在只要带走三句话。
第一,上下文工程就是整理 Codex 桌上的资料。少了会猜,多了会乱,刚好才稳。
第二,任务说明先写目标、边界、材料、验收。新手不要追求华丽提示词,先追求不让 Codex 猜。
第三,盯紧你能控制的那两层:长期规则放 AGENTS.md,这次的临时要求放当前对话,命令输出只给关键证据,窗口再大也别当仓库。
你可以从下一次任务就开始练。不要改工具,不要改模型,只改你的交接方式:先写目标,再写边界,再指定材料,最后写验收。做完一次你就会感受到区别。Codex 不一定突然变得完美,但它会少很多莫名其妙的猜测。
还有一个很实用的练习:下次 Codex 出错时,不要马上重开会话。先把这次任务复盘成四行——我原本要什么、我没说清什么、它误看了什么、下次要提前给什么。复盘两三次,你就会发现错误类型很集中。上下文工程就是从这些重复错误里长出来的。
最后理一下顺序:权限解决的是「它能不能做」,工具解决的是「它能借什么做」,上下文解决的是「它知不知道该怎么做」。顺序反了,新手会很累——工具接了一堆,权限开了一堆,最后 Codex 还是不知道你到底想要什么。配置是手段,理解是方向。方向清楚了,哪怕工具少一点,Codex 也能更稳定地往前走。
全部知识点的位置和学习顺序见 OpenAI Codex 完整学习指南。如果你下一步继续学,可以看 OpenAI Codex AGENTS.md 配置指南、Codex 沙箱与审批设置 和 Codex 模型怎么选、成本与速度怎么权衡。先把上下文讲清,再谈权限和模型,顺序会更自然。
📚 更多 Agent 编程方法论:Agent 编程方法论:不教工具教方法,让 AI 按你的规矩干活

Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
8 大 AI Agent 全维度对比:从 GitHub Stars 到安全记录,从月度成本到真实场景——Hermes 自我进化、OpenClaw 网关编排、Claude Code 编码天花板,附决策树和双修方案。
从零掌握 Runway Gen-4.5 视频提示词写法。一个八层统一框架融合五维自然语言、时间戳分段和力-反应语法,附 10 个精选模板和可直接使用的元提示词。
每周精选 AI 编程与自动化实战内容,直达你的邮箱