Hermes 语音模式完全攻略:CLI + Telegram + Discord 三表面免费搭建
Hermes Agent 语音模式支持三种交互表面:CLI 按键录音、Telegram 语音气泡、Discord 语音频道实时对话。本文覆盖 10 种 TTS 与 6 种 STT 提供商对比、零成本方案(faster-whisper + Edge TTS)、26 短语幻觉过滤器、四档 config.yaml 配置模板。
Hermes Agent 语音模式支持三种交互表面:CLI 按键录音、Telegram 语音气泡、Discord 语音频道实时对话。本文覆盖 10 种 TTS 与 6 种 STT 提供商对比、零成本方案(faster-whisper + Edge TTS)、26 短语幻觉过滤器、四档 config.yaml 配置模板。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
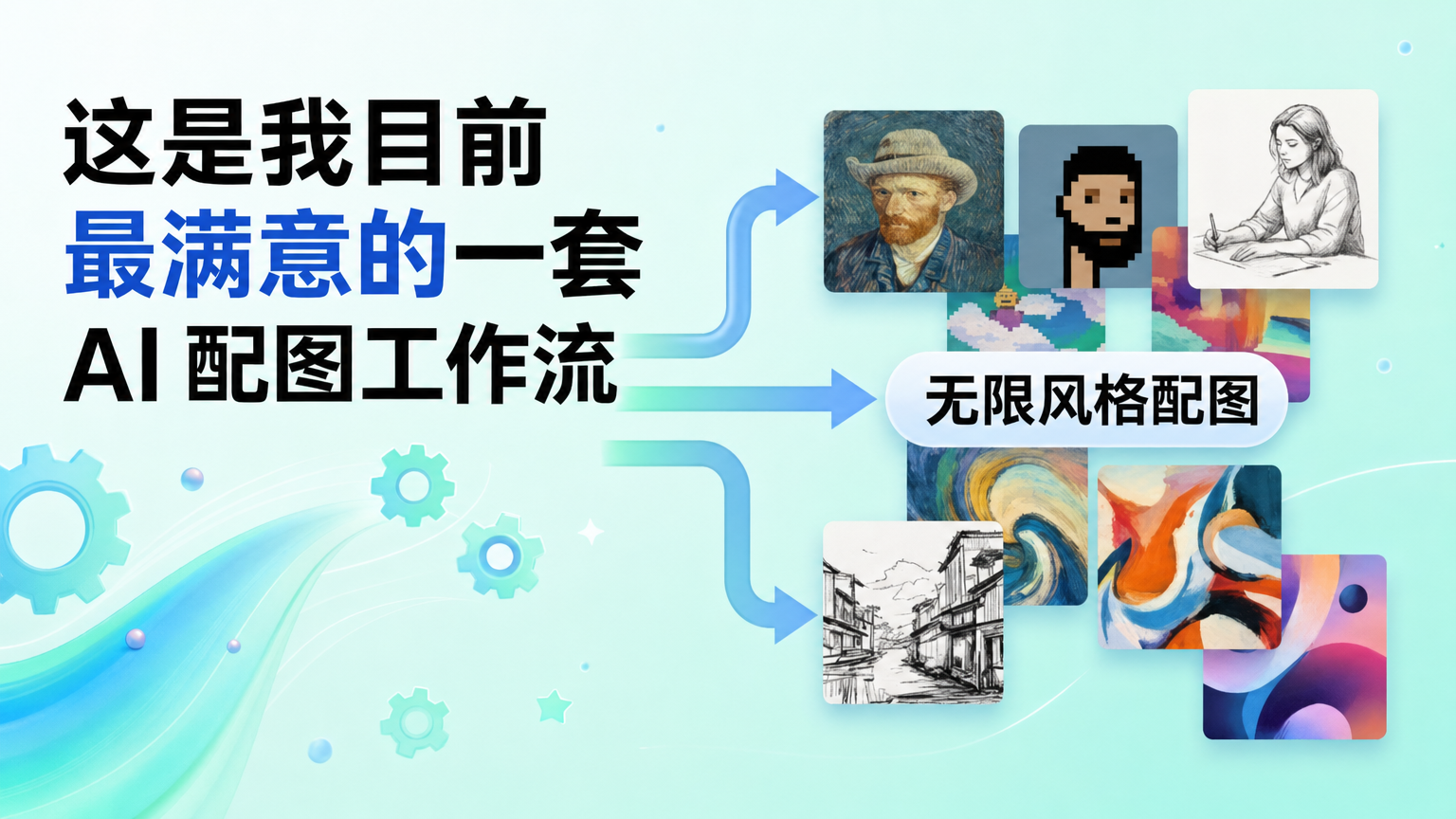
AI 配图最难的不是生成一张好图,而是稳定复现同一种风格。这篇拆解我目前最满意的一套垫图式文章配图工作流:一张参考图定义风格,五步流水线完成生成、上传和写回。
凌晨 1 点,文章写完了,配图还没搞定。
这是我最讨厌的时刻。
打开 AI 绘图工具,写了一堆提示词,生成的图和想象中完全不一样。换个关键词再试,风格又飘了。折腾半小时,还是对不上心中那个「感觉」。
更崩溃的是,好不容易调出一个满意的风格,下次再用,怎么也复现不出来。
问题出在哪?
文字和画面之间,天然存在一道翻译损耗。
AI 绘图工具对文字描述的理解是模糊的。你说「科技感」,它可能给你赛博朋克,也可能给你工业风。你说「简约」,它可能给你极简,也可能给你空洞。文字和画面之间,隔着一道「翻译损耗」。
而「垫图」——用一张参考图作为视觉锚点——直接跳过了文字翻译这一步。AI 看到的不是抽象的描述,而是具体的颜色、构图、笔触。
我做了一个 Skill,用垫图模式实现「无限风格复刻」。
如果你是那种——
那这套系统就是为你设计的。
你将获得 :
先拆解一下配图这件事到底难在哪里:
根问题 :AI 生成的图和心中所想不一致
传统方案(精雕提示词)为什么解决不了?
因为它在错误的方向上优化。
文字的模糊性不是「不够精确」的问题,而是媒介本身的限制 。你说「科技感」,我脑海里浮现的画面和你脑海里的完全不同——因为我们各自的视觉记忆库不一样。AI 也是如此。
用更精确的文字弥补文字的模糊性,就像用更大声的喊叫弥补语言不通——方向错了,努力白费。
这个道理我折腾了半年才想明白。希望你不用。
Adobe Firefly 的官方定义说得很清楚:「AI 图像风格迁移让你上传一张图像作为参考,然后生成与该风格一致的新素材。」
关键词是「视觉锚点」。
用第一性原理思考:配图的本质需求是什么?
不是「描述你想要的风格」,而是「传递你想要的风格」。
文字是「描述」,图片是「传递」。一张参考图直接把风格信息无损传给了 AI——没有翻译,没有理解偏差,没有「每个人脑海里的科技感不一样」。
当你给 AI 一张参考图,它做的不是「理解文字 → 想象画面」,而是「分析画面特征 → 复制特征到新内容」。
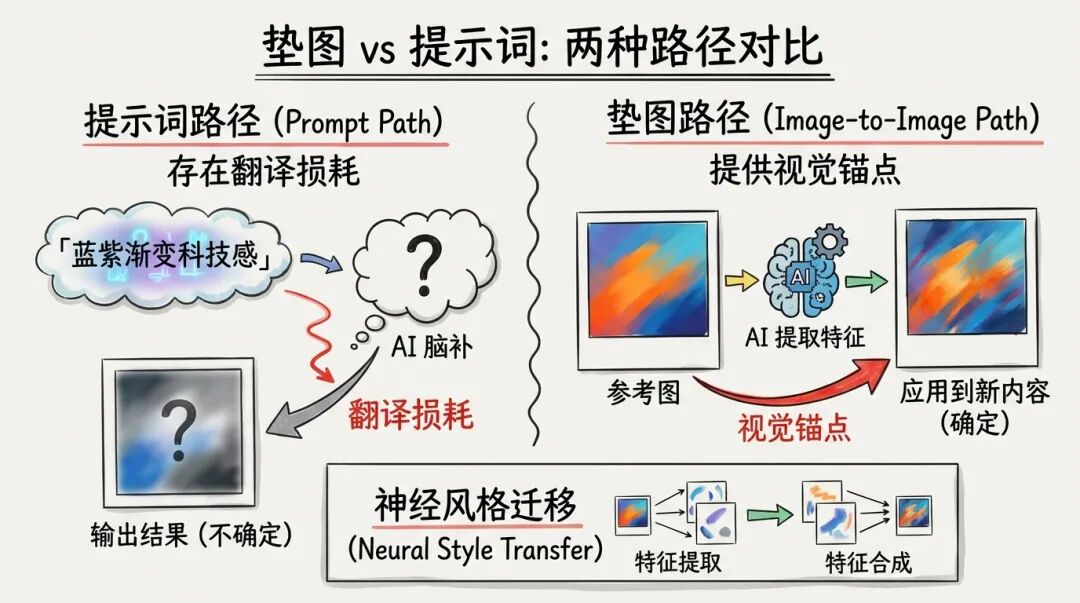
这两个路径的差异巨大——
提示词路径 :「蓝紫渐变科技感」→ AI 脑补 → 输出结果(不确定)
垫图路径 :参考图的颜色 / 构图 / 笔触 → AI 提取特征 → 应用到新内容(确定)
我曾经用同一句提示词连续生成 10 张图,10 张风格都不一样。换成垫图后,10 张图看起来像同一个系列。
这就是「确定性」的价值。
🔬 底层原理
神经风格迁移的本质是「特征提取 + 特征合成」。AI 从参考图中学习色调、纹理、构图模式,然后把这些特征「迁移」到新生成的内容上。这不是简单的滤镜叠加,而是重新生成一张「看起来属于同一系列」的新图。
垫图 vs 提示词:两种路径对比
这套流程跑通后,配一篇文章的图只需要 3 分钟。
更重要的是,你再也不用担心「这次调出来了,下次调不出来」。
找到一个喜欢的风格,永久可用。换一个风格,无缝切换。你的配图库不再是碎片化的试错结果,而是可复用的视觉资产 。
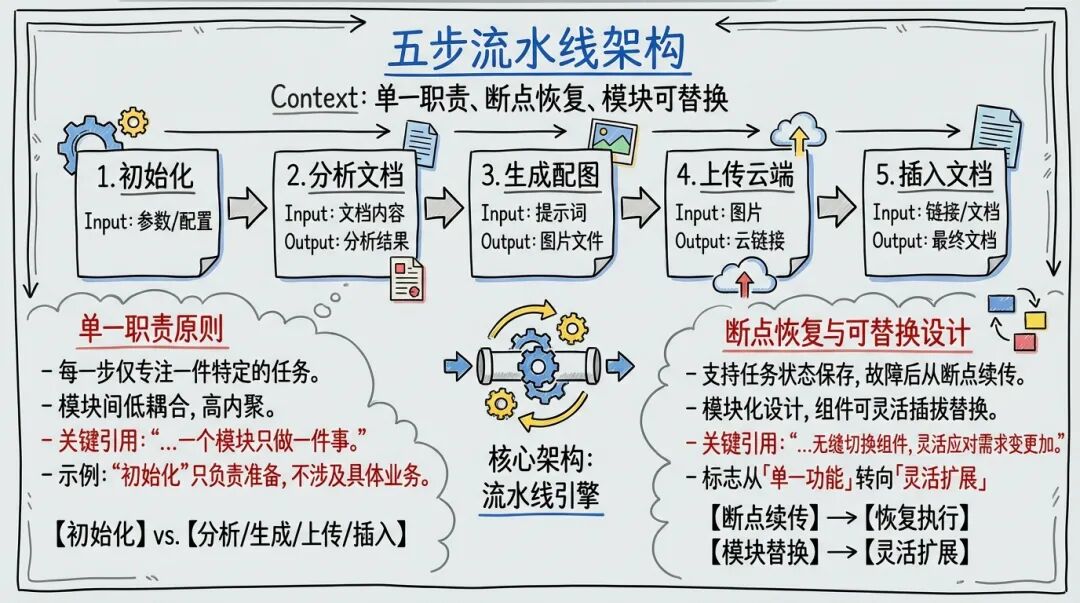
这个 Skill 把配图流程拆成 5 个步骤,每一步只干一件事,出问题好排查:
输入:Markdown 文档 + 用户选择的风格
输出:带配图的 Markdown 文档 + 云端图片 URL
单一职责原则 ——每一步只做一件事,出问题能快速定位。
复杂系统的稳定性,来自组件的简单性。
断点恢复 。每一步完成后都会更新 progress.json。如果 Step 03 生成到一半断了,下次可以从断点继续,不用从头开始。
好的系统不怕中断,怕的是从头再来。
模块可替换 。想换个图像生成服务?只改 Step 03。想换个云存储?只改 Step 04。其他步骤不受影响。
🏗️ 设计洞见
很多人做自动化工具喜欢「一个脚本搞定所有」。这样写起来快,但维护起来是噩梦。把流程拆成独立步骤,每步有明确的输入输出,看起来麻烦,实际上是「用前期的结构化投入,换后期的维护自由」。
五步流水线架构
这一步决定图片好不好看。 其他步骤都是辅助,这里是真正干活的地方。
系统预置了多种风格,每种风格对应一张参考图:
封面风格 (cover_styles):
主图风格 (main_styles):
每张参考图都存放在 reference/images/ 目录,文件名遵循 {类型}-{风格ID}.{扩展名} 的命名规范,比如 cover-gradient-tech.png。
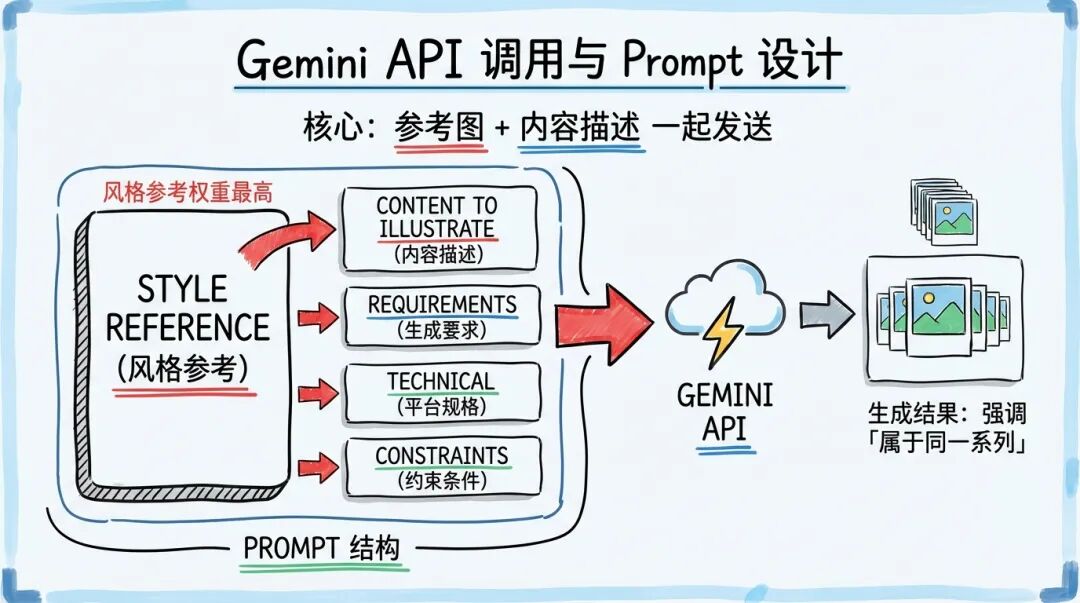
核心是把参考图和内容描述一起发给 Gemini:
Prompt 结构 :
为什么这样设计 Prompt?
第一次运行时的感觉,我到现在还记得。
看着 AI 根据那张参考图,一张一张生成出来——颜色对、构图对、连笔触的粗细都对。那一刻我知道,配图这件事,从此不一样了。
📝 记住这个
垫图的本质是「用图片定义风格」。找到一张你喜欢的图,复制到reference/images/目录,更新styles.json,这个风格就永久可用了。再也不用记那些复杂的提示词。
Gemini API 调用与 Prompt 设计
这是整个系统最「可迁移」的部分。你不需要改任何代码,只需要:
reference/images/ 目录——按命名规范:
cover-{style-id}.pngmain-{style-id}.jpgstyles.json——在对应数组里加一条:封面示例:
{
"id": "my-custom-style",
"name": "我的自定义风格",
"file": "cover-my-custom-style.png"
}
主图示例:
{
"id": "my-main-style",
"name": "我的主图风格",
"file": "main-my-main-style.jpg"
}
下次运行 Skill 时,新风格就会出现在选项里。
大多数人还在研究「怎么写出更好的提示词」。而你,已经在收藏风格了。
设计决策 :风格定义和代码逻辑完全解耦。
styles.json 是纯数据文件,脚本只负责「读取配置 → 加载图片 → 调用 API」。你添加的任何风格,脚本都能自动处理。
这就是「数据驱动」的威力——扩展功能不需要改代码,只需要加数据。
扩展功能不改代码,只加数据——这就是「数据驱动」的威力。
掌握这套系统后,你的思维方式会发生一个微妙的变化:
以前看到好看的图,你想的是「这图真好看」。 现在看到好看的图,你想的是「这个风格我要收藏」。
从「欣赏者」变成「收藏者」——这就是系统化思维带来的认知升级。
🎯 打个比方
这就像手机换壁纸。你不需要懂手机系统是怎么渲染的,只需要把图片放到相册里,选择「设为壁纸」。垫图风格扩展的逻辑是一样的——把图片放到指定目录,更新索引文件,完成。
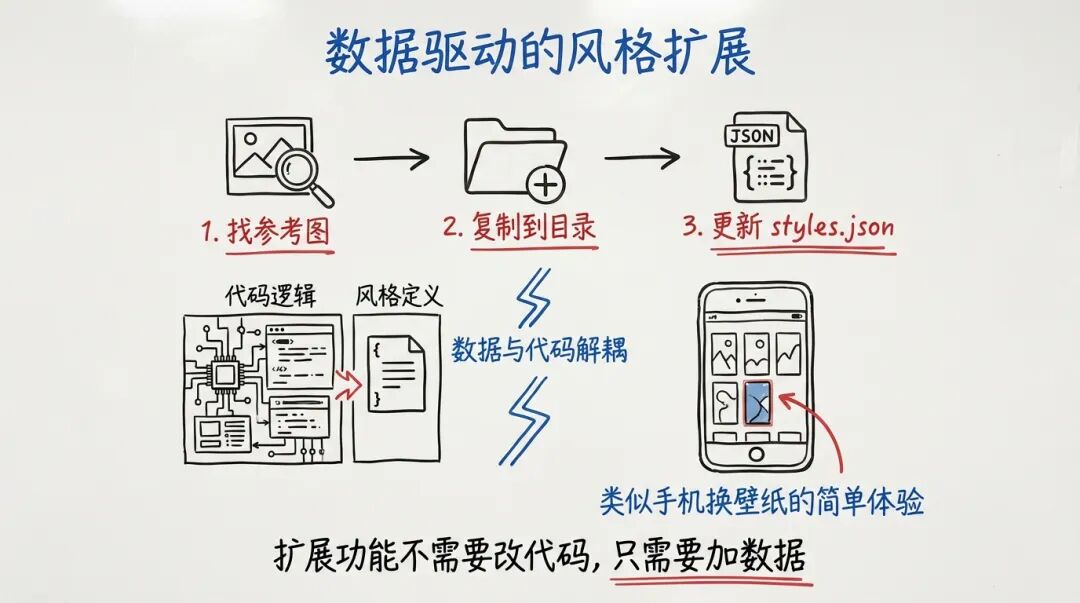
数据驱动的风格扩展
不同平台对图片比例有不同要求:
微信公众号 :封面 2.35:1(接近 21:9),主图 16:9
小红书 :封面 3:4(竖版),主图 3:4
抖音 :封面 9:16(全竖版),主图 9:16
系统在 Step 01 初始化时让你选择目标平台,后续生成会自动套用对应的分辨率。
所有规格定义在 reference/definitions/platforms.json:
"wechat": {
"name": "微信公众号",
"cover": {"aspect": "2.35:1", "resolution": "900x383"},
"main": {"aspect": "16:9", "resolution": "1280x720"}
}
想增加新平台?加一条配置就行。
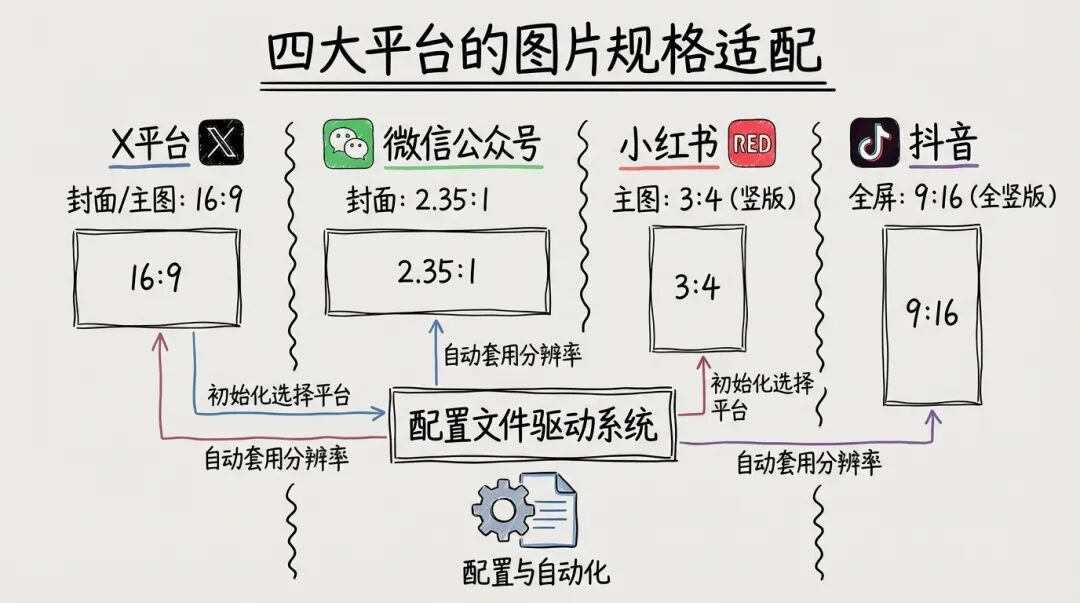
三大平台的图片规格适配
生成完图片,总得有个地方放。系统支持三种存储模式:
腾讯云 COS (推荐国内用户):
credentials/cos.jsonCloudflare R2 (推荐全球用户):
credentials/r2.json本地存储 :
选择存储模式后,Step 04 会自动调用对应的上传脚本,Step 05 会把正确的 URL 插入文档。
如果你想从零搭建这套系统,关键里程碑是:
M1:能跑通最小闭环
output/ 目录下有带图的文档M2:垫图风格生效
M3:多平台多风格
M4:云存储可用
credentials/gemini.json 是否配置正确styles.json 中的 file 字段一致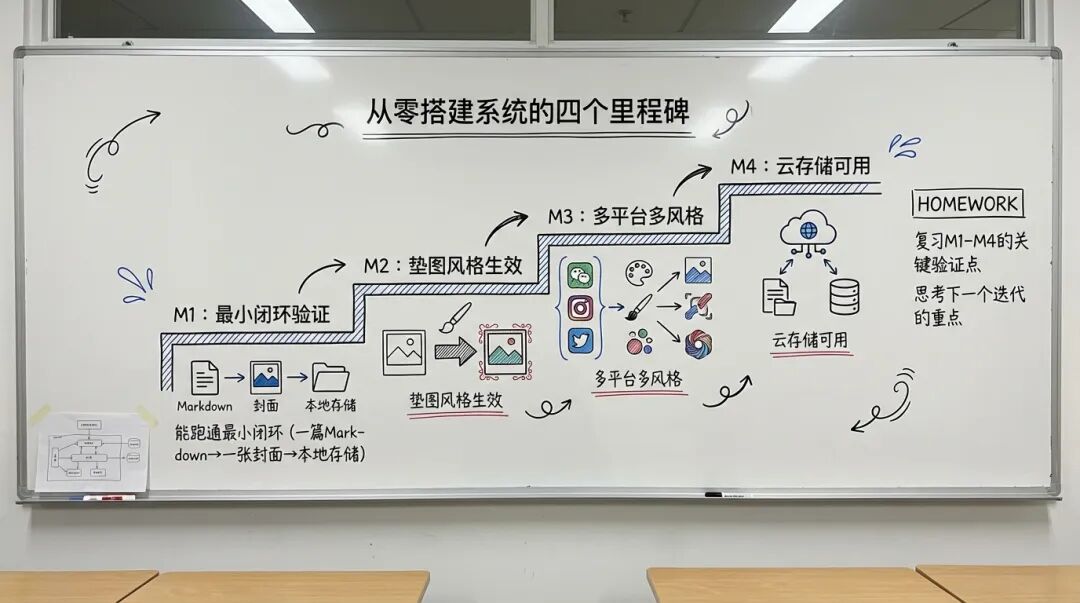
从零搭建的四个里程碑
这篇文章的 7 张配图,就是用这个 Skill 一键生成的。
参考资料
📚 更多 Agent 工作流内容:Agent 工作流实战指南:从单个 Agent 到十人团队的完整搭建路径
🎨 姐妹篇:纯提示词 AI 配图框架:100 种风格随机抽签的三层架构设计——不用参考图,用 100 种预设风格池 + 三层提示词分离解决同样的问题。

Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
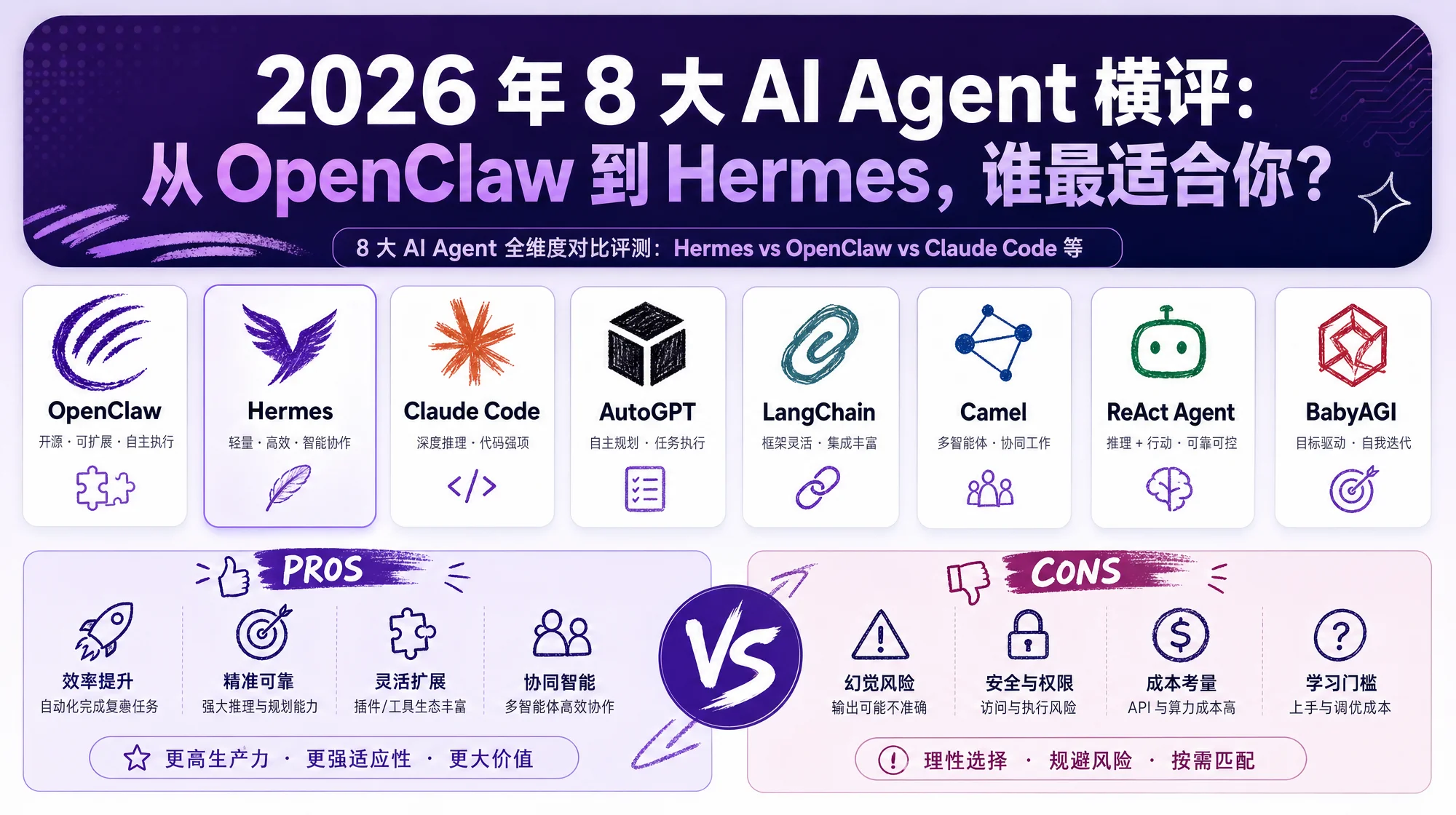
8 大 AI Agent 全维度对比:从 GitHub Stars 到安全记录,从月度成本到真实场景——Hermes 自我进化、OpenClaw 网关编排、Claude Code 编码天花板,附决策树和双修方案。
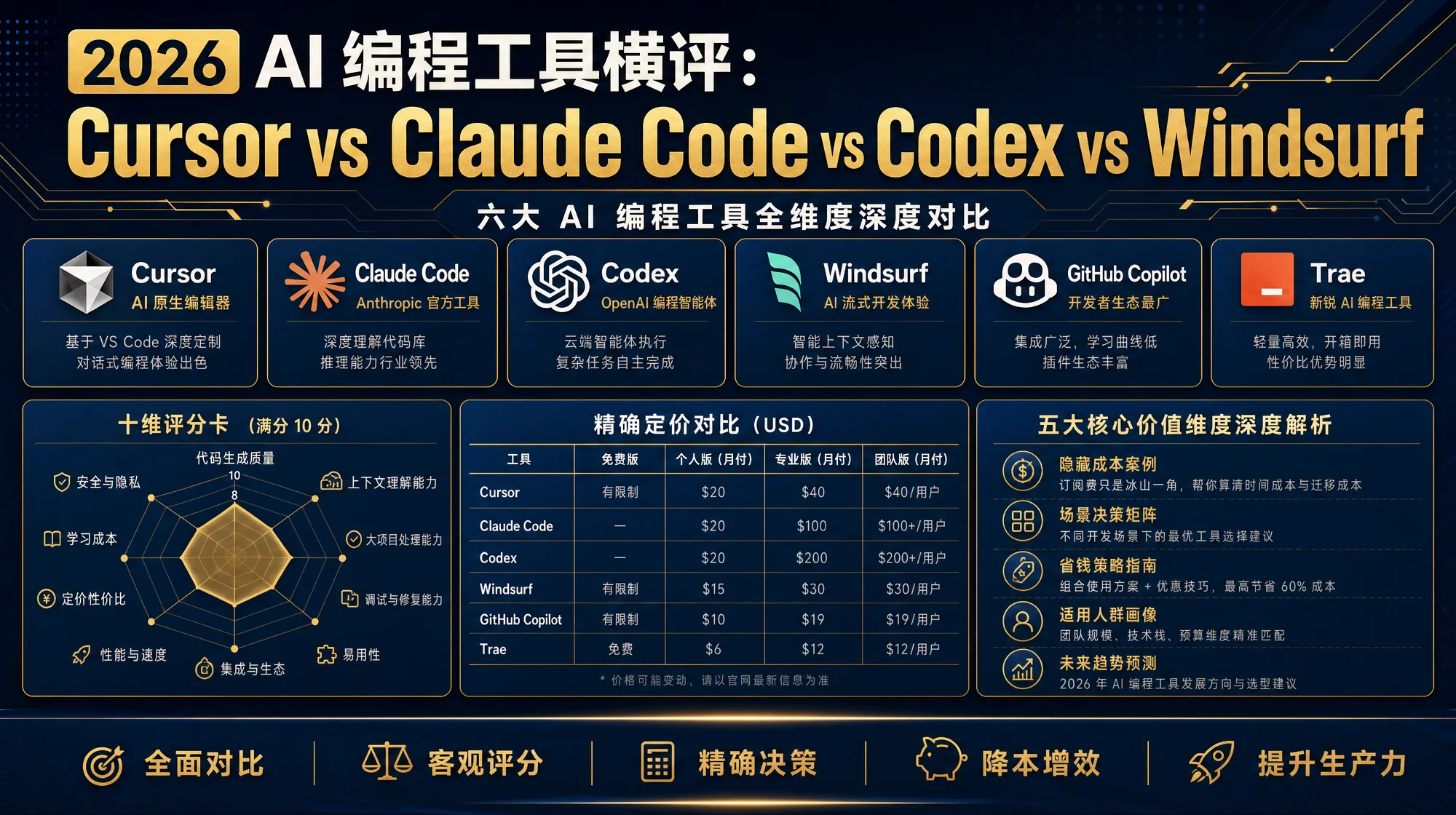
全网极少数同时在生产跑 Cursor、Claude Code、Codex 三大工具的实战横评。六大主力工具十维评分卡、精确定价表、隐藏成本案例、场景决策矩阵、省钱策略——一篇看完不用再翻别的。
每周精选 AI 编程与自动化实战内容,直达你的邮箱