Hermes SOUL.md 人设工程 + 三层记忆深度解析:让 Agent 精确遵循你的人格
Hermes Agent 的三层记忆系统——SOUL.md 定义身份、MEMORY.md 记录环境事实、USER.md 刻画用户画像——合计约 1,300 Token 的永久记忆预算,在会话启动时冻结注入系统提示词。本文深度拆解 10 层提示词拼装顺序、9 种外部记忆提供商对比、记忆安全扫描机制,附翔宇指针架构实战全文与 SOUL.md 调优四步法。
Hermes Agent 的三层记忆系统——SOUL.md 定义身份、MEMORY.md 记录环境事实、USER.md 刻画用户画像——合计约 1,300 Token 的永久记忆预算,在会话启动时冻结注入系统提示词。本文深度拆解 10 层提示词拼装顺序、9 种外部记忆提供商对比、记忆安全扫描机制,附翔宇指针架构实战全文与 SOUL.md 调优四步法。
Hermes Agent 语音模式支持三种交互表面:CLI 按键录音、Telegram 语音气泡、Discord 语音频道实时对话。本文覆盖 10 种 TTS 与 6 种 STT 提供商对比、零成本方案(faster-whisper + Edge TTS)、26 短语幻觉过滤器、四档 config.yaml 配置模板。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
按官方源码核对后的 NCA Toolkit 新手实战指南:讲清它适合什么场景、如何用 n8n 调用、关键字段怎么写,以及常见报错怎么排查。

No-Code Architects Toolkit,简称 NCA Toolkit,是一个开源的媒体处理 API 工具包。它把视频、音频、图片、字幕、转录、格式转换和云存储上传等能力封装成 HTTP API,适合接入 n8n、Make、脚本或自建后台。
它不是剪映、CapCut 这类可视化剪辑软件,也不是“部署完就完全免费”的云服务。软件本身开源,但你仍然要为服务器、Cloud Run、对象存储、带宽和计算时间付费。
它真正有用的地方是:把原本分散在多个 SaaS 里的媒体处理能力,集中成一个你自己可控的后端服务。对于内容创作者和自动化工作流用户,这一点比“多一个工具”更重要。
官方仓库:
https://github.com/stephengpope/no-code-architects-toolkit
如果你还没有部署服务,先看这篇安装教程:
https://xiangyugongzuoliu.com/google-cloud-nocode-architects-toolkit-guide-zh/
新手不要一上来研究全部接口。最稳的学习顺序是:
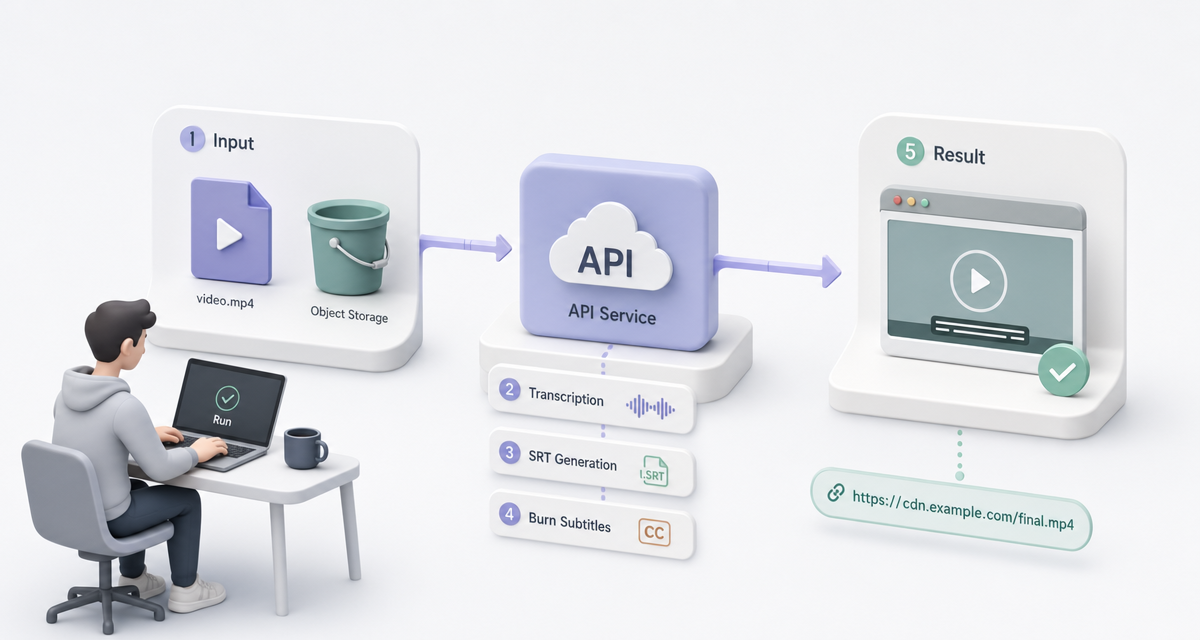
/v1/toolkit/test 确认部署和对象存储正常。/v1/media/transcribe 跑通转录和字幕文件生成。/v1/video/caption 把字幕烧录到视频里。如果这四步能跑通,你基本就理解了 NCA Toolkit 的核心工作方式:输入一个媒体 URL,提交一个处理任务,拿到一个 job_id,最后得到云存储里的结果 URL。
NCA Toolkit 最适合三类人。
第一类是内容创作者。你经常要做视频转字幕、提取音频、切片、拼接、转格式、生成缩略图,手工操作已经开始浪费时间。
第二类是自动化工作流用户。你已经在用 n8n 或 Make,希望用 HTTP Request 节点把视频处理接入工作流,而不是每一步都手动打开一个网页工具。
第三类是有一定部署能力的团队。你不想同时订阅多个媒体 API,也不想让核心素材全部经过第三方 SaaS,希望把常用能力部署成自己的 API。
它不适合三种情况:
这种情况下,剪映、CapCut、Premiere 或在线工具会更省事。
看 NCA Toolkit,不要只看接口列表。源码里有三个概念决定了你怎么调用它。
第一个概念是鉴权。
源码里的 services/authentication.py 读取请求头 X-API-Key,并和环境变量 API_KEY 对比。也就是说,所有正式接口都要带 x-api-key,值必须和你部署时设置的 API_KEY 一致。
第二个概念是任务队列。
源码里的 app.py 会给请求生成 job_id。如果请求里带了 webhook_url,通常会先返回 202 processing,任务进入队列,完成后再回调你的 webhook。没有 webhook_url 的请求则更倾向于同步执行。
第三个概念是云存储。
很多接口处理完成后,会把结果上传到 Google Cloud Storage 或 S3 兼容存储,再返回文件 URL。也就是说,部署时只配置 API_KEY 还不够,你还要正确配置 GCP 或 S3 存储,否则测试接口可能直接卡在上传结果这一步。
最小环境变量一般包括:
API_KEY:接口鉴权用。GCP_BUCKET_NAME 和 GCP_SA_CREDENTIALS:使用 Google Cloud Storage 时需要。S3_ENDPOINT_URL、S3_ACCESS_KEY、S3_SECRET_KEY、S3_BUCKET_NAME、S3_REGION:使用 S3 兼容存储时需要。LOCAL_STORAGE_PATH:本地临时文件目录,默认是 /tmp。MAX_QUEUE_LENGTH:队列最大长度,默认 0 表示不限制。GUNICORN_TIMEOUT:长任务需要调大,官方 README 示例建议大文件任务可设到 300。不要先做“全自动剪辑系统”。先用三个小任务判断环境是否靠谱。
第一步,测试 API 和对象存储。
GET https://<your-host>/v1/toolkit/test
x-api-key: YOUR_API_KEY
这个接口会创建一个测试文件,上传到你的云存储,然后返回文件 URL。如果这里失败,先不要测视频接口。优先检查:
x-api-key 是否正确。API_KEY 环境变量是否生效。第二步,测试转录。
{
"media_url": "https://files.example.com/source-audio",
"task": "transcribe",
"include_text": true,
"include_srt": true,
"include_segments": false,
"response_type": "cloud",
"words_per_line": 8,
"webhook_url": "https://your-n8n.example.com/webhook/nca-done",
"id": "demo-transcribe-001"
}
这里有两个字段要注意。
response_type 建议新手先用 cloud。这样结果会变成 text_url、srt_url 这类文件链接,更容易接到 n8n 后续节点。
words_per_line 是当前源码路由 schema 里接受的字段。官方文档个别位置写过 max_words_per_line,但当前 routes/v1/media/media_transcribe.py 里是 words_per_line,并且接口设置了 additionalProperties: False。如果你照抄不被 schema 接受的字段,会直接收到 Invalid payload。
第三步,测试烧录字幕。
{
"video_url": "https://files.example.com/video-input",
"captions": "https://files.example.com/subtitle-file",
"settings": {
"style": "classic",
"position": "bottom_center",
"alignment": "center",
"font_family": "Arial",
"font_size": 24,
"line_color": "#FFFFFF",
"outline_color": "#000000"
},
"webhook_url": "https://your-n8n.example.com/webhook/nca-done",
"id": "demo-caption-001"
}
captions 可以传纯文本,也可以传字幕文件 URL。不要把旧教程里的 subtitle_url 当成当前推荐字段,当前 /v1/video/caption 路由 schema 使用的是 captions。
如果你不传 captions,接口会尝试自动从视频音频生成字幕,再烧录到视频里。新手调试时,我更建议先传一个已经确认可访问的字幕文件,这样更容易判断问题到底出在字幕生成,还是出在视频烧录。
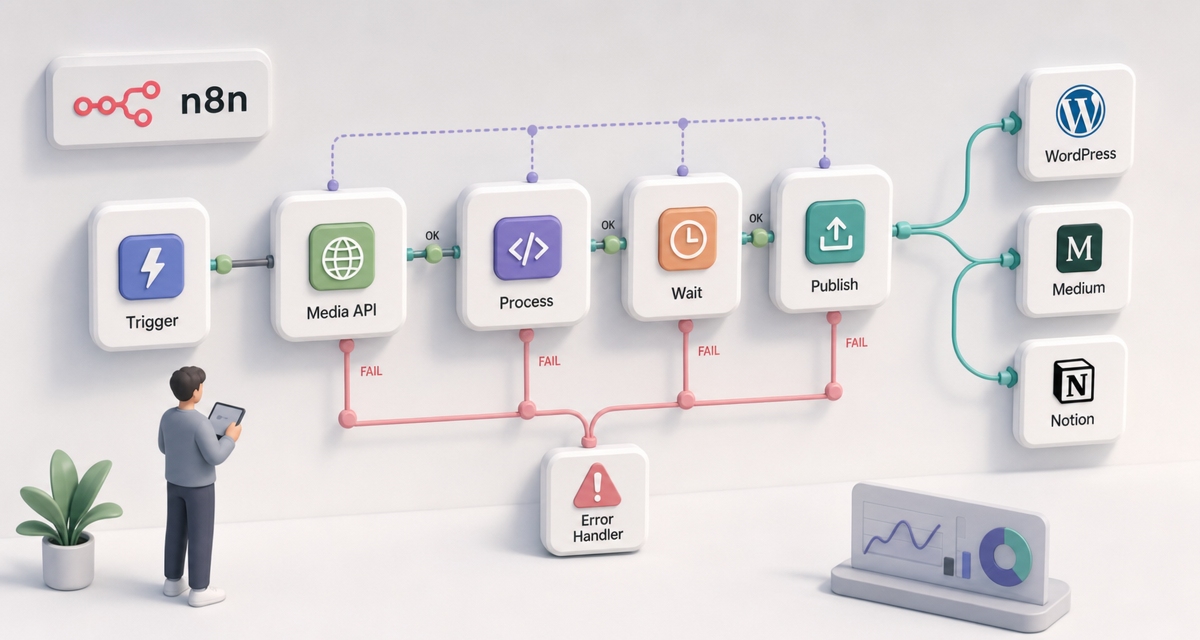
在 n8n 里,不要把 NCA Toolkit 当成“一个 HTTP 节点解决所有问题”。更稳的结构是拆成四段。
触发段:
处理段:
/v1/toolkit/test 做环境检查,生产环境可以省略。/v1/media/transcribe 生成文本和字幕。/v1/video/caption 烧录字幕。/v1/media/convert/mp3。等待段:
webhook_url,用 n8n Webhook 节点接收回调。job_id,再用 /v1/toolkit/job/status 查询状态。发布段:
这里的关键不是节点多,而是每一步都有明确输入和输出。哪一步失败,就只查那一步的请求体、响应和日志。
新手先记住这些就够。
基础检查:
/v1/toolkit/test:检查 API、鉴权和云存储是否能跑通。/v1/toolkit/authenticate:检查 API Key 是否有效。/v1/toolkit/job/status:按 job_id 查单个任务状态。/v1/toolkit/jobs/status:查近期任务状态。字幕和转录:
/v1/media/transcribe:把音视频转成文本、SRT 或 segments。/v1/video/caption:把字幕烧录进视频。/v1/media/generate/ass:生成 ASS 字幕样式,适合更细的字幕控制。视频处理:
/v1/video/thumbnail:从视频指定时间点提取缩略图。/v1/video/trim:保留一个时间段。/v1/video/cut:删除一个或多个时间段。/v1/video/split:按多个时间段拆分。/v1/video/concatenate:拼接多个视频。音频和媒体转换:
/v1/media/convert:通用格式转换。/v1/media/convert/mp3:提取或转换成 MP3。/v1/audio/concatenate:拼接多个音频。/v1/media/metadata:读取时长、分辨率、编码、码率等信息。/v1/media/silence:检测静音片段。下载和截图:
/v1/BETA/media/download:基于 yt-dlp 下载媒体,支持格式、音频、缩略图、字幕和 cookie。/v1/image/screenshot/webpage:用 Playwright 截网页图。/v1/image/convert/video:把静态图片转成视频。高级能力:
/v1/ffmpeg/compose:用结构化 JSON 组合 FFmpeg 输入、滤镜、输出参数。/v1/code/execute/python:远程执行 Python 代码片段。/v1/s3/upload 和 /v1/gcp/upload:把文件 URL 上传到对应云存储。高级接口不是新手第一天要用的。尤其是 /v1/ffmpeg/compose 和 /v1/code/execute/python,能力很强,但也更容易写错参数或带来安全风险。

第一,x-api-key 不是放在请求体里,而是放在请求头里。
第二,id 和 job_id 不是一回事。id 是你自己传的业务标识,例如 demo-caption-001;job_id 是 Toolkit 生成的任务 UUID,用来查状态。
第三,长任务尽量传 webhook_url。带 webhook_url 后,接口通常先返回 202 processing,真正结果通过 webhook 返回,或者你再用 job_id 查询。
第四,当前路由普遍使用 JSON schema 校验,很多接口设置了 additionalProperties: False。这意味着多写一个不存在的字段,不会被忽略,而是可能直接报 Invalid payload。
第五,转录接口当前源码字段是 words_per_line,不是 max_words_per_line。
第六,视频加字幕接口当前字段是 captions,不是 subtitle_url。
第七,task: "translate" 在 Whisper 场景里通常表示翻译成英文,不是任意语言互译。做中文字幕或双语字幕时,更稳的流程是先转录,再交给翻译节点处理,最后再烧录。
学习测试可以用 Google Cloud Run。它上手快,适合先跑通 API、对象存储和 n8n 调用。
但如果你要处理长视频、大文件或高并发任务,长期更建议用 VPS、专用 Docker 主机或更可控的容器环境。原因很简单:媒体处理吃 CPU、内存、磁盘、网络和时间。
官方 README 里也提醒了两个限制:
webhook_url,避免代理超时。部署时建议固定下面几条规则:
API_KEY 用随机长字符串,不要用教程里的示例弱口令。LOCAL_STORAGE_PATH 指向空间足够的临时目录。GUNICORN_TIMEOUT 根据任务长度调大,例如 300 秒起步。MAX_QUEUE_LENGTH 不要一直无限制,生产环境建议按机器资源设置上限。返回 401 Unauthorized:
先查请求头。n8n HTTP Request 节点里要加 header:x-api-key: 你的 API_KEY。如果 header 没问题,再查服务端环境变量 API_KEY 是否真的生效。
返回 400 Invalid payload:
先查字段名。NCA Toolkit 的很多路由不接受多余字段。比如转录接口写成 max_words_per_line,当前源码就不会通过 schema 校验。
返回 202 processing 但没有后续结果:
先保存返回的 job_id,用 /v1/toolkit/job/status 查任务。再检查 webhook_url 是否是公网可访问地址,n8n Webhook 是否处于生产 URL,是否被防火墙或鉴权拦住。
测试接口失败:
优先查对象存储。/v1/toolkit/test 会创建测试文件并上传到云存储。如果这里失败,通常不是视频处理问题,而是 GCP / S3 配置问题。
下载 YouTube 或其他平台失败:
/v1/BETA/media/download 底层用的是 yt-dlp。平台风控、地区限制、年龄限制、登录态和 cookie 都会影响下载。不要把它当成“永远可下载任何平台”的万能接口。
字幕烧录失败:
先确认视频 URL 和字幕 URL 都能被服务器访问。浏览器能打开,不代表部署环境一定能下载。私有链接、带登录态链接和过期签名链接都可能失败。
长视频卡住或超时:
先减小输入文件,跑一个 30 秒样片。样片能跑通,再处理长视频。不要一开始就拿 2 小时视频测试部署是否成功。

NCA Toolkit 最值得新手掌握的,不是“它有多少接口”,而是它能把媒体处理变成可编排的 API。
你可以先从一个最小流程开始:
/v1/media/transcribe 生成字幕。/v1/video/caption 烧录字幕。这个流程跑通后,再逐步加入下载、翻译、缩略图、剪切、拼接、自动发布和人工审核。
核心原则只有一句:先把部署和存储跑稳,再把工作流拆小,最后再谈批量自动化。
源码核对版本:
d9bb5679e203e6b5d3b3c2b9ab848a289c645024,官方 main 分支,核对日期 2026 年 4 月 30 日。
官方仓库:
https://github.com/stephengpope/no-code-architects-toolkit
官方 README:
https://github.com/stephengpope/no-code-architects-toolkit/blob/main/README.md
任务队列源码:
https://github.com/stephengpope/no-code-architects-toolkit/blob/main/app.py
路由发现和 payload 校验源码:
https://github.com/stephengpope/no-code-architects-toolkit/blob/main/app_utils.py
视频加字幕路由:
转录路由:


小红书、公众号、抖音、视频号、YouTube、X——6 个平台先做哪个?这个站先帮你选对平台,再给每个平台用 AI 做内容的打法。
Sean 已经算是「翔宇工作流」学员实践栏目的常客。前段时间我们刚介绍过他的 Animaker Dev,现在他又上线了 GoodTrans,把长文档翻译做成可编辑译文、双语对照、质量报告和异步邮件交付。

翔宇学员云燚和团队制作的 AI 时代深度播客《42织序》,由人类主播和 AI 搭档“序言”共同构成节目第二视角,目前两期围绕 AI 重塑工作、关系操作系统、岗位议价权等命题展开。本文将节目介绍给关注同方向的听众。
每周精选 AI 编程与自动化实战内容,直达你的邮箱