Claude Code + Hermes MCP 消息桥接实战:任务完成自动通知手机
Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
向量数据库太重、RAG 管线太脆——用 CLAUDE.md 多级路由 + 纯文件系统,从零搭建一个 AI Agent 能直接读懂的知识库。本文拆解 1000+ 文件规模的真实架构,给你一套可直接抄作业的方案。
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
OpenAI Codex 单人用顺了,一上团队就乱:代码风格各成一派、配置各管各、没人说得清谁烧了多少额度。本文从协作崩溃的真实场景倒推,讲清团队化要补的几件事、什么时候该补,以及一个人怎么用「轻团队」做法拿到团队级产能。

预计阅读 16 分钟 | 目标:讲清 OpenAI Codex 从一个人用到一个小团队一起用要补哪些东西,看完你能判断自己该不该升级、第一步该配什么。
这篇不堆术语。你只要抓住一条主线:单人用 Codex 解决的是「我自己干得快」,团队用 Codex 解决的是「所有人干得一致、还能被监管」。从前者过渡到后者,要补的不是更复杂的工具,而是几件把「藏在各自脑子里的规矩」搬到仓库里的事。
三个人,一个仓库,每个人手上都有一份用得很顺的 Codex。听起来很美。两周后,真实发生的往往是这样:
A 让 Codex 用 pnpm 装依赖,B 的 Codex 习惯用 npm,C 干脆每次手动改——同一个仓库的 lock 文件来回打架。评审时 A 看 B 写的代码总觉得别扭,因为两人各自的 AGENTS.md 里写的命名规范、错误处理风格根本不一样,谁也没把它当回事。一个拉取请求里混着人写的和 Codex 写的代码,评审的人分不清哪段该重点查。月底账单下来,谁也说不清这个月谁烧了多少额度、哪个项目最贵。更尴尬的是,安全同事突然问「上周那个改鉴权的提交,是 AI 写的还是人写的、它当时还跑了什么命令」——没人答得上来。
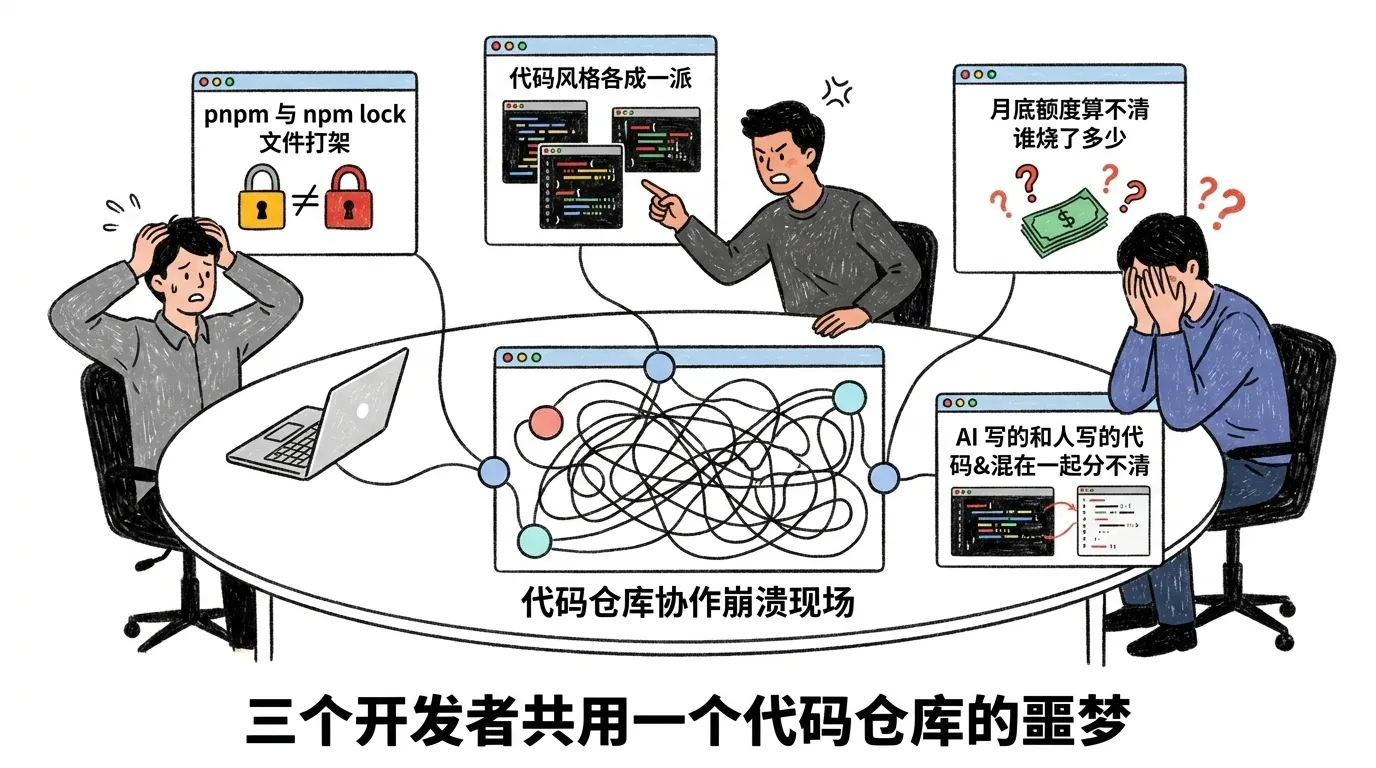
这不是 Codex 不好用,恰恰相反,是它太好用了:一个人用的时候,所有规矩都装在你自己脑子里,怎么省事怎么来,从不出问题。可一旦变成好几个人,每个人脑子里的那套规矩互不相同,仓库就成了几套习惯的角力场。
团队化要做的,就是把这些「藏在各自电脑里、各自脑子里的个人约定」,搬到「写进仓库、所有人克隆就自动继承」的明文位置上。下面这些事,本质上都是在拆解上面这个崩溃现场的某一块:
| 崩溃现场的某一幕 | 要补的那件事 | 一句话 |
|---|---|---|
| 代码风格各成一派、命名规范没人统一 | 共享 AGENTS.md | 把项目规则提交进 git,全队克隆即用 |
| 高频套路靠口口相传,新人反复踩同样的坑 | 共享 Skills | 把可复用工作流沉淀成共享技能 |
| 人写的和 AI 写的混在一起、评审分不清重点 | Cloud 代码评审 | 让 Codex 把第一道关,人做终审 |
| 月底说不清谁烧了多少额度 | 成本与权限治理 | 搞清楚用量归集,按规模选方案 |
| 危险操作没统一刹车、追溯不到 AI 跑过什么 | 沙箱标准化与审计 | 全队同一档沙箱 + 统一审批 + AI 代码可追溯 |
这张表不是要你照着从上到下做满。先看自己的崩溃现场卡在哪一幕,就先补对应那件事——团队化按痛点触发,不按人数触发。后面每一节就是把表里的每一行展开讲透。
💡 通俗讲:单人阶段你管的是「Codex 能力强不强」,团队阶段你管的是「所有人是不是按同一套规矩干活、谁干了什么能不能查、危险动作有没有统一的刹车」。补的这几件事,本质上就是把「能力问题」之外的「一致性 + 可监管」问题一个个解决掉。
崩溃现场最先冒出来、也最好补的一幕,是代码风格各成一派。根因是每个人的规矩只写在自己的全局配置里,互不相干。解法很直接:把项目根的 AGENTS.md 提交进 git,所有人克隆仓库就自动拿到同一套规矩。这是团队化里投入最小、收益最快的一步,也几乎一定是你该先动手的那件事。
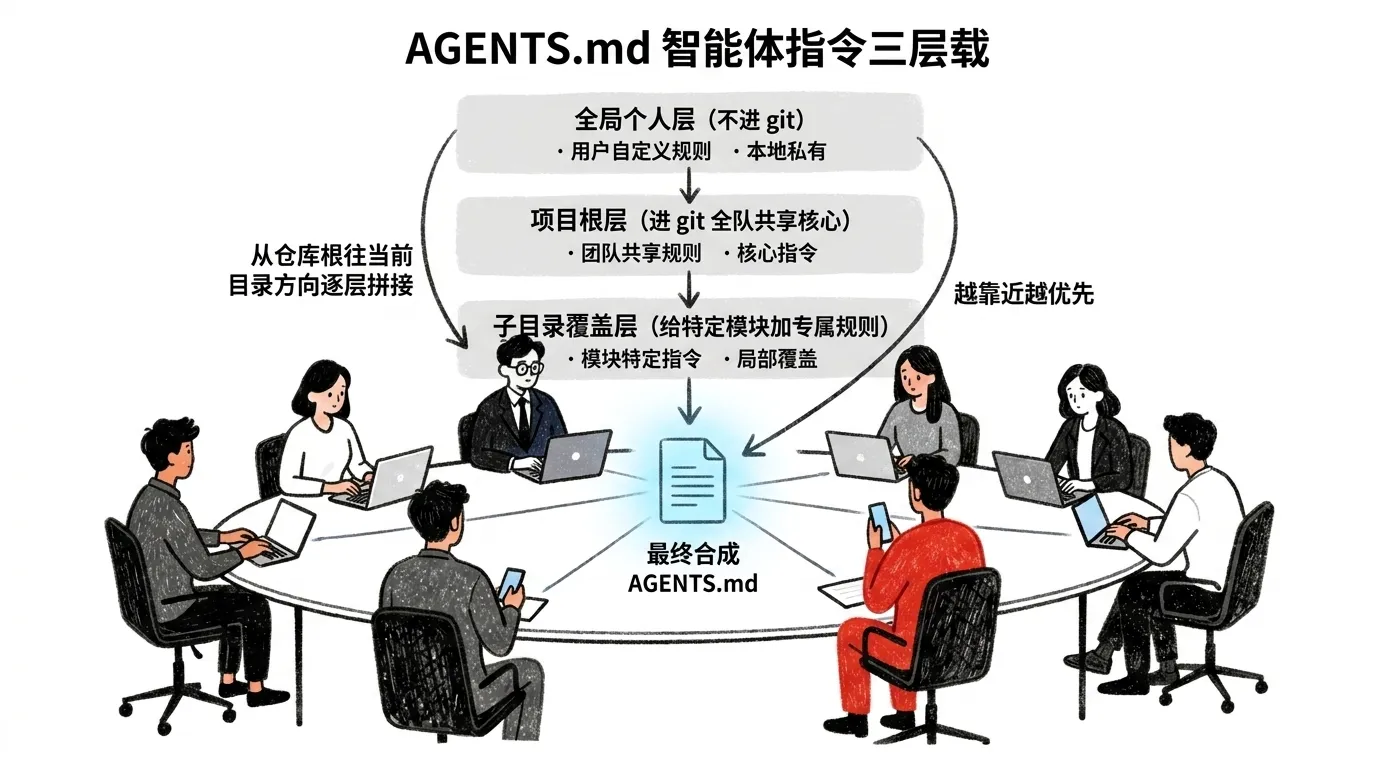
AGENTS.md 是 Codex 的指令文件,类似给智能体看的 README。Codex 按三层加载它,越靠近你工作目录的越优先:
| 层级 | 位置 | 进 git? | 放什么 |
|---|---|---|---|
| 全局个人层 | ~/.codex/AGENTS.md |
否 | 个人偏好、沟通风格、评审啰嗦程度 |
| 项目根层 | 仓库 git 根目录的 AGENTS.md |
是 | 项目铁律、构建/测试/评审标准(团队共享核心) |
| 子目录覆盖层 | 子目录里的 AGENTS.md |
是 | 给某个模块(如 frontend/、services/payments/)的专属规则 |
💡 通俗讲:Codex 从仓库根目录往你当前所在目录方向,把这些文件按顺序拼起来,后出现的(更靠近你的)覆盖前面的。官方对拼接后的总大小设了上限,由
project_doc_max_bytes这个配置项控制,默认 32 KiB——具体数值以官方当前文档为准,但思路不变:项目根那份别写成长篇大论,写关键铁律就行,超出上限的部分会被截掉。
团队怎么用好它,三条实操:
项目根那份共享 AGENTS.md 写多细才合适?给新手一个起步骨架的感觉(不必照抄,按你项目改):
# AGENTS.md
## 项目约定
- 包管理器统一用 pnpm,不要混用 npm / yarn。
- 提交前先跑 `pnpm lint` 和 `pnpm test`,全绿再开拉取请求。
- 改了公共工具函数,同步更新 docs/ 下对应说明。
## 评审准则
- 重点看:输入校验、错误处理、有没有把密钥写进代码。
- 不接受没有测试的新功能。
💡 通俗讲:这份文件就是把「老员工带新人时反复叮嘱的那几句话」写下来,让 Codex 替你叮嘱。它不需要长,关键是写项目特有的、容易踩的那几条,而不是抄一堆通用大道理。通用大道理 Codex 本来就懂,写进去只会撑大文件、挤掉真正该被读到的关键规则。
⚠️ 常见踩坑:把个人偏好(比如「回答简短一点」)写进了项目根那份共享文件,结果全队都被你的个人风格绑架。个人偏好放
~/.codex/AGENTS.md,项目规则才进仓库——这条边界一开始就要划清。
规则共享好了,下一幕痛点是:团队里那些「该怎么做一件复杂事」的套路,全靠老人口口相传,新人反复踩同样的坑。解法是 Skills(技能)——Codex 的可复用工作流,把一件复杂事的标准做法打包好,下次喊一声就跑。团队共享走「项目层」:把仓库里的 .agents/skills 目录提交进 git,团队克隆项目就拿到。
和 AGENTS.md 一样,Skill 也分全局和项目两层:全局放 ~/.agents/skills,项目放仓库里的 .agents/skills。一个 Skill 通常是一个 SKILL.md 文件,加上可选的脚本、参考资料和素材。需要自动安装的依赖,在 agents/openai.yaml 里声明。
💡 通俗讲:AGENTS.md 管「规矩」(该怎么做、不该做什么),Skill 管「套路」(一件复杂事的标准做法打包好,下次喊一声就跑)。团队把高频套路写成共享 Skill,新人不用再口口相传。
共享 Skill 有一个比 AGENTS.md 更隐蔽的坑,值得单独拎出来:
⚠️ 常见踩坑:在你机器上跑得通的 Skill,队友机器上可能跑不通——环境、权限、路径、依赖版本都可能不一样。一份 Skill 自己测好就直接提交,结果队友一跑全报错,是团队共享 Skill 最常见的翻车场景。
对应的两条防御动作:
agents/openai.yaml 让它自动装,减少环境差异。一个团队 Skill 目录的最简结构长这样,新人一眼能看懂库里有什么:
.agents/skills/
├── 新建标准服务/
│ └── SKILL.md ← 一步步建一个符合项目规范的新服务
├── 发布前检查/
│ └── SKILL.md ← 跑完整发布前清单(lint / 测试 / 构建 / 变更日志)
└── 排查线上日志/
├── SKILL.md
└── scripts/ ← 配套脚本
判断一个套路该不该写成共享 Skill,只有一条标准——它是不是被多个人、反复手动重复。你一个人偶尔用的,留在个人层 ~/.agents/skills 就行;全队每周都要做、还容易做错的(比如「新建一个标准服务」「跑一遍发布前检查」),才值得提交到项目层共享。所以团队化别一上来就把所有套路都塞成共享 Skill:先挑最高频、最容易出错的一两件做出来验证收益,再逐步扩。把一次性的东西硬写成 Skill,正是 Skill 库膨胀失控、然后到处「跑不通」的起点。
人写的和 AI 写的代码混在一个拉取请求里、评审分不清重点,是崩溃现场的另一幕。Codex Cloud 能直接在 GitHub 的拉取请求上做代码评审,帮人类把第一道关。配置上你只需要决定一件事:让它「按需触发」还是「自动触发」,评审标准则跟着 AGENTS.md 走。
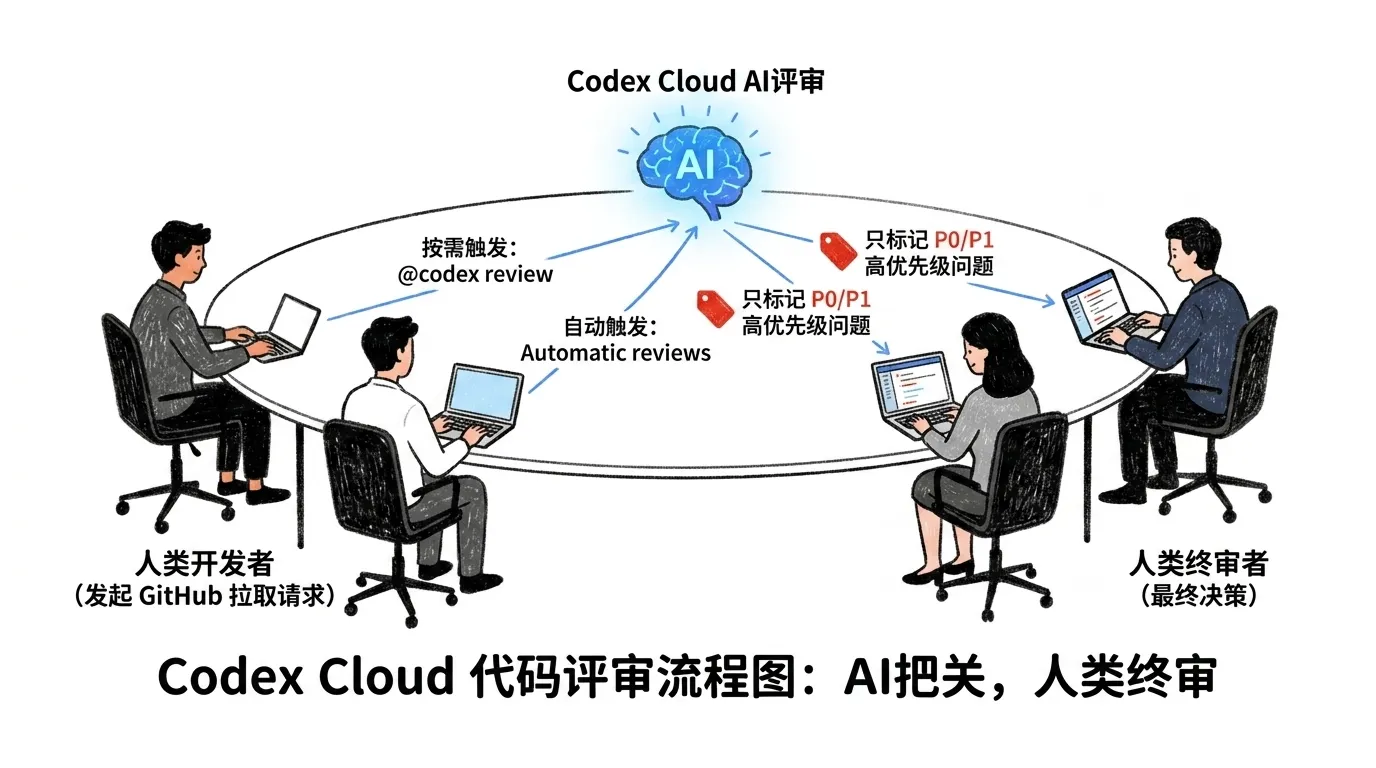
前提是这个仓库已经接好 Codex Cloud。接好之后,两种触发方式:
@codex review,Codex 会回应并像团队成员一样留下一条评审意见。评审时 Codex 只标记 P0、P1 级别的高优先级问题,让评论聚焦真正的风险,而不是淹没在鸡毛蒜皮里。评审标准来自最靠近改动文件的那份 AGENTS.md——在里面写一段「评审准则」即可定制;给某个关键模块加更严的子目录 AGENTS.md,那个模块就会被更仔细地审。评审完想让它直接修,评论 @codex fix the P1 issue,在它有权限时会把修复推回分支。
💡 通俗讲:这等于给团队配了一个 7×24 小时、不知疲倦的「初审同事」,把明显的高优先级问题先挑出来,人类评审员只在它之后做最终把关,省掉大量重复的初筛工作。
新手判断三条:
@codex review 让团队熟悉它的评审风格,再切自动评审,避免一上来满屏自动评论造成噪声。怎么让评审更准?关键是在项目根 AGENTS.md 里写清「这个项目的评审到底看什么」。一段评审准则的起步样子:
## 评审准则(Codex 代码评审参照)
- P0 必拦:密钥/令牌硬编码、SQL 拼接注入、绕过鉴权。
- P1 关注:缺输入校验、错误被吞掉、新代码没测试。
- 本仓 services/payments/ 涉及金额计算,按更严标准审。
写了这段之后,Codex 的评审就不再是泛泛的「代码看起来还行」,而是对着你的真实风险清单逐条挑。
⚠️ 常见踩坑:以为开了自动评审就能替代人工评审。Codex 评审是「初审 + 高优先级过滤」,不是终审。涉及架构决策、业务正确性、安全边界的判断,仍然要人类拍板。开自动评审是为了省掉人类重复的初筛,不是把判断权整个交出去。
月底账单说不清谁用了多少,是团队再大一点就会撞上的一幕。先把一个现实讲在前面:原生 Codex 没有「按团队成员细分用量」的现成报表,这是当前生态的真实空白。好在小团队不用为此上重型方案——账号隔离就够,规模大了再加一层「AI 网关」。
具体做法按团队规模分两档:
3 到 5 人小团队(不必上重型方案):
团队变大或要做合规审计:
社区主流解法是在 Codex 和模型之间加一层「AI 网关(AI Gateway)」:每个开发者用一个虚拟接口密钥(不是真密钥),所有请求经过网关,网关层做按密钥计费、按团队聚合、按个人限额。常见的开源或商业网关有 LiteLLM、Helicone、Portkey 等。
💡 通俗讲:AI 网关就像公司给每个人发的一张「内部充值卡」——刷的是卡,钱从公司账户走,但每张卡刷了多少、谁刷的、能刷多少有上限,都一清二楚。
🔥 翔宇判断:网关是「规模到了才值得的基础设施」,不是越早上越好。人少的时候硬上网关,多出来的是部署和维护成本,省下的计费颗粒度根本用不上。判断很简单——你开始答不出「这个月谁用得最多」并且这个问题真的有人问,才是上网关的时机。
最后一幕崩溃是:危险操作没有统一的刹车,事后还追溯不到 AI 跑过什么。团队安全要做的,就是把每个人各自的权限设置收敛成一套全队标准——所有人用同一档沙箱、越界统一要审批、AI 写的代码可追溯。这件事可以拆成由浅入深的三块来落地。
沙箱标准化。 Codex 有三档沙箱模式:
| 沙箱模式 | 含义 | 团队建议 |
|---|---|---|
read-only |
只读,只能看不能改 | 规划/讨论阶段用 |
workspace-write |
工作区可写(默认),能读、能改工作区内文件、跑本地常规命令 | 团队统一用这档 |
danger-full-access |
去除文件系统与网络限制 | 不放开给团队 |
配合审批策略(approval_policy):默认是 on-request,Codex 越过沙箱边界(比如改工作区外的文件、要联网)前会先要确认。团队统一用 workspace-write + 合理的审批策略,就能保证「没有人能在不被提示的情况下让 Codex 干越界的事」。
审计与追溯。 用同一套配置约束所有人,配合可观测平台记录 Codex 执行过哪些命令,做到「谁让 AI 跑了什么」事后可查。
AI 代码标识。 给 AI 生成的拉取请求加 [AI] 标签,或用专属的提交作者邮箱,让评审时一眼就知道「这段是 AI 写的」,从而加严审查。
⚠️ 常见踩坑:为了省事,让某个人临时切到
danger-full-access跑一个任务,跑完忘了切回来。团队里只要有一台机器长期开着完全访问,整个安全基线就形同虚设。沙箱档位要么全队统一锁死,要么就把「临时放开后必须切回」写进规则。
还有一条数据底线必须讲清:OpenAI 公开说明,对商业用户默认不拿你的输入输出训练模型,ChatGPT Business 的数据默认排除在训练之外。商业敏感代码场景,要用 Business 或 Enterprise 档,而不是个人版——这不是优化项,是合规底线。
读到这里你可能会说:我根本没有团队,一个人撑一摊事(独立开发者、一人公司)。那么前面那些「共享」「治理」「评审流程」对你确实用不上——但「团队级的并行产能」这件事,一个人照样能要,而且不用招人,靠的是 Codex 自带的并行能力。这套做法我习惯叫它「轻团队」,靠三招:
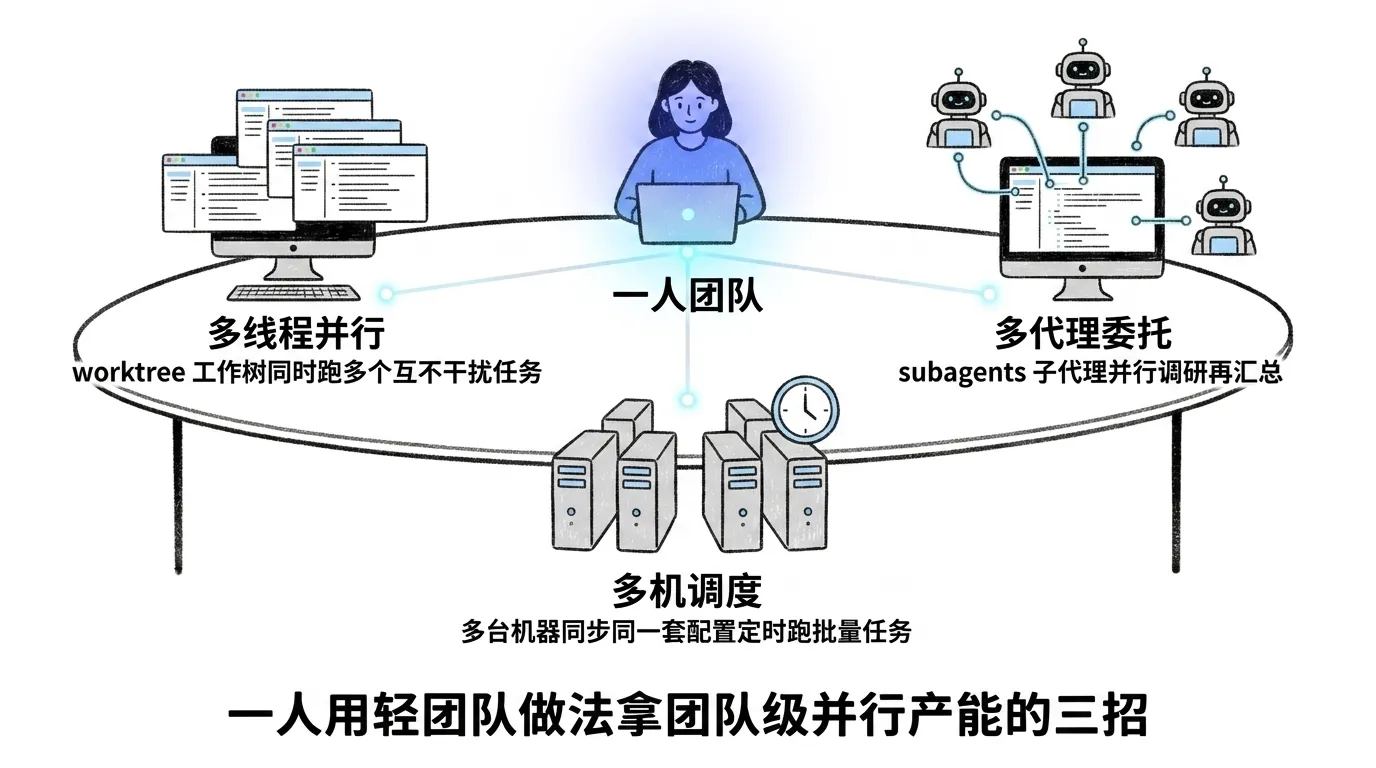
~/.codex/agents/、项目的放 .codex/agents/,每个文件写清名字、什么时候用、行为指引,靠 /agent 命令管理。🔥 翔宇判断:「轻团队」对单人公司的性价比很高——不用真招人发工资,不用上网关做计费,不用拉取请求评审流程,却拿到了团队级的并行产能。落地顺序建议先 worktree(门槛最低、立刻能用),跑顺了再上 subagents,最后才碰多机调度(要先有同步和定时基础设施)。一上来就铺三招,往往是哪招都没真用起来。
💡 通俗讲:worktree 解决「同一时间手上能开几条活」,subagents 解决「一件复杂事能不能拆给几个分身同时查」,多机调度解决「机器闲着的时间能不能也利用上」。三招叠起来,单人也能跑出小团队的吞吐。
团队选工具时,有一个常被忽略但很现实的问题:将来想换工具,沉淀下来的东西搬得动吗? 答案取决于你把东西放在了哪一层。
| 你沉淀的东西 | 迁移成本 | 原因 |
|---|---|---|
| AGENTS.md(项目规则) | 低 | 开放标准(见 agents.md),Codex、Claude Code、Cursor、Copilot 等都支持 |
| Skills(可复用工作流) | 中 | 各家专有格式,文件结构有差异,迁移要重写 |
| hooks(生命周期钩子) | 高 | 完全各家私有,迁移基本要重做 |
所以选工具时不妨先问自己一句「未来换工具的可能性有多大」。可能要换,就把更多规则放进 AGENTS.md(最保险),少依赖 Skills 和 hooks 这类工具私有特性;确定长期绑定一家,再深用它的私有能力换效率。这是一个关于「灵活性 vs 效率」的取舍,没有标准答案,但要在团队化早期就想清楚,别等沉淀了一大堆私有配置才发现搬不动。社区主流的分层策略也印证这一点:项目铁律放 AGENTS.md(保险),复杂工作流写 Skill(成本中等),深度生命周期治理才用 hooks(绑定最深)——按「换工具痛感从低到高」摆放,是相对稳妥的默认选择。
把前面散落的踩坑收成一张反模式清单,团队化时逐条避开:
~/.codex/AGENTS.md,项目规则才进仓库。agents/openai.yaml,建内部目录。danger-full-access。⚠️ 常见踩坑(最隐蔽的一条):把团队化当成「配置任务」一次做完。它其实是个持续过程——规则会过时、Skill 会膨胀、成本会变化。真正稳定的团队,是定期回头删废规则、清没人用的 Skill、复查权限,而不是配完就不管。
如果你已经动手补了第一件事,给一个落地节奏参考,按周往前推:
@codex review),让团队熟悉它的评审风格,把评审准则写进 AGENTS.md。判断进度的标准不是「配了多少」,而是最初那个崩溃现场有没有被一幕幕拆掉:风格还乱不乱、配置还漂不漂、额度说不说得清、AI 代码追不追得到。哪一幕不再发生,对应那件事就算到位了。
收尾时可以拿下面这张清单对照自己的团队现状,逐条勾选:
~/.codex/AGENTS.md,没混进项目共享文件。agents/openai.yaml,有内部目录可查。workspace-write 沙箱 + 合理审批策略,没有机器长期开完全访问。[AI] 标签或专属提交邮箱),可追溯。勾不满也没关系——回头看自己的崩溃现场卡在哪一幕,痛在哪就先补哪条。团队化是逐步推进,不是一次满分。
OpenAI Codex 从单人到团队,难的从来不是工具更复杂,而是把「装在各自脑子里的规矩」变成「写进仓库、全队自动继承的明文制度」。开篇那个三个人一个仓库的崩溃现场,每一幕都对应一件该补的事:风格乱了补共享 AGENTS.md,套路靠传补共享 Skills,评审分不清重点上 Cloud 代码评审,额度算不清做成本治理,危险动作没刹车做沙箱标准化。不按人数、按痛点触发,哪幕先发生就先补哪件,最小动作永远是「项目根放一份共享 AGENTS.md」。就算只有你一个人,也能用「轻团队」三招拿到团队级产能。
相关阅读:
外部参考:
project_doc_max_bytes 上限的来源。@codex review、Automatic reviews、P0/P1 过滤的来源。
Claude Code 跑了 20 分钟你不在电脑前,怎么知道它完成了?三种方案对比:Hooks 轻量脚本、Channels 官方双向、Hermes MCP 反向桥接。本文给完整配置代码,复制即用。
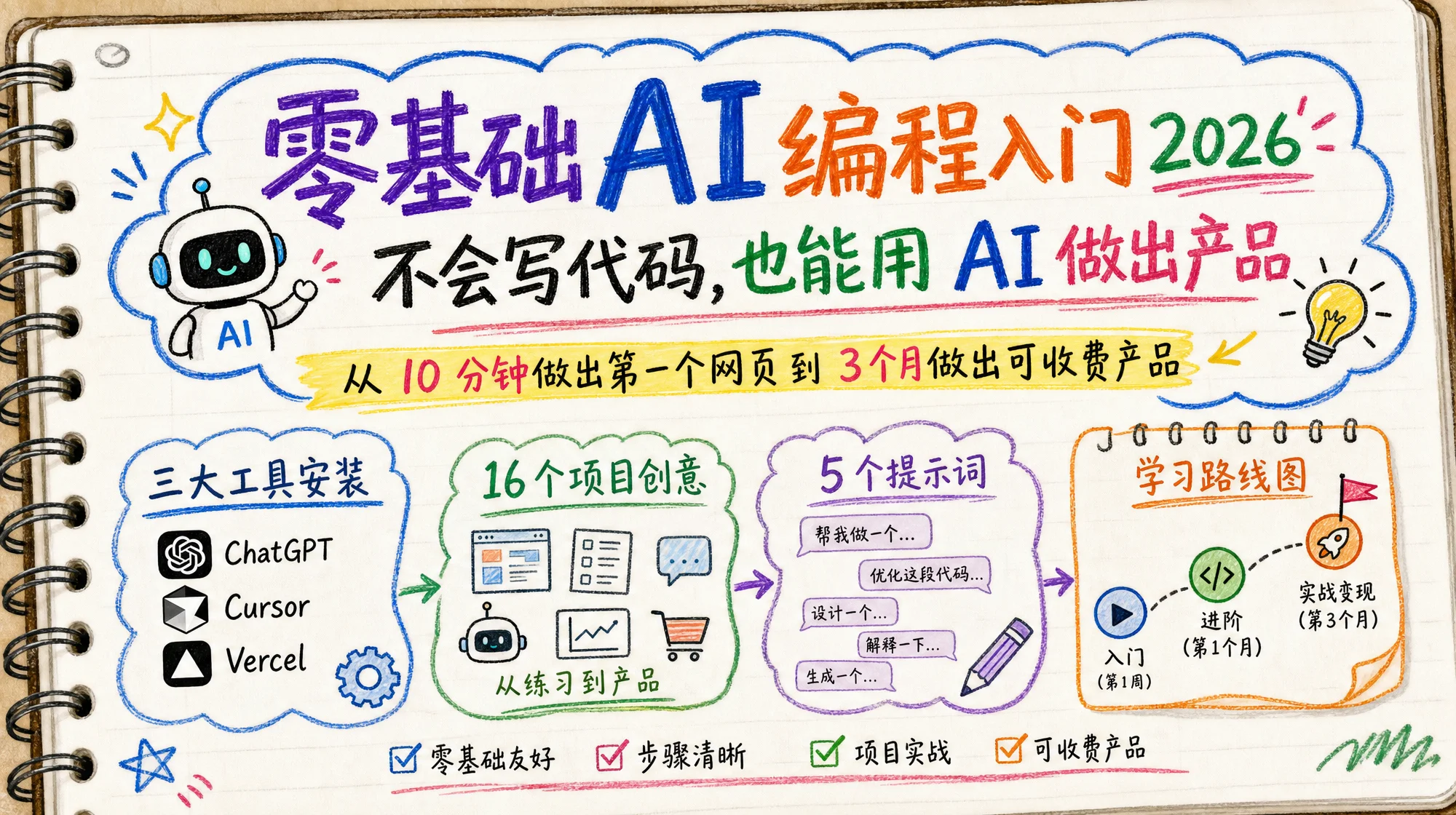
2026 年零基础学 AI 编程,最大的门槛不是技术——是你能不能说清楚自己要什么。这篇指南从 10 分钟第一个作品到 3 个月做出产品,给你一条完整的路。
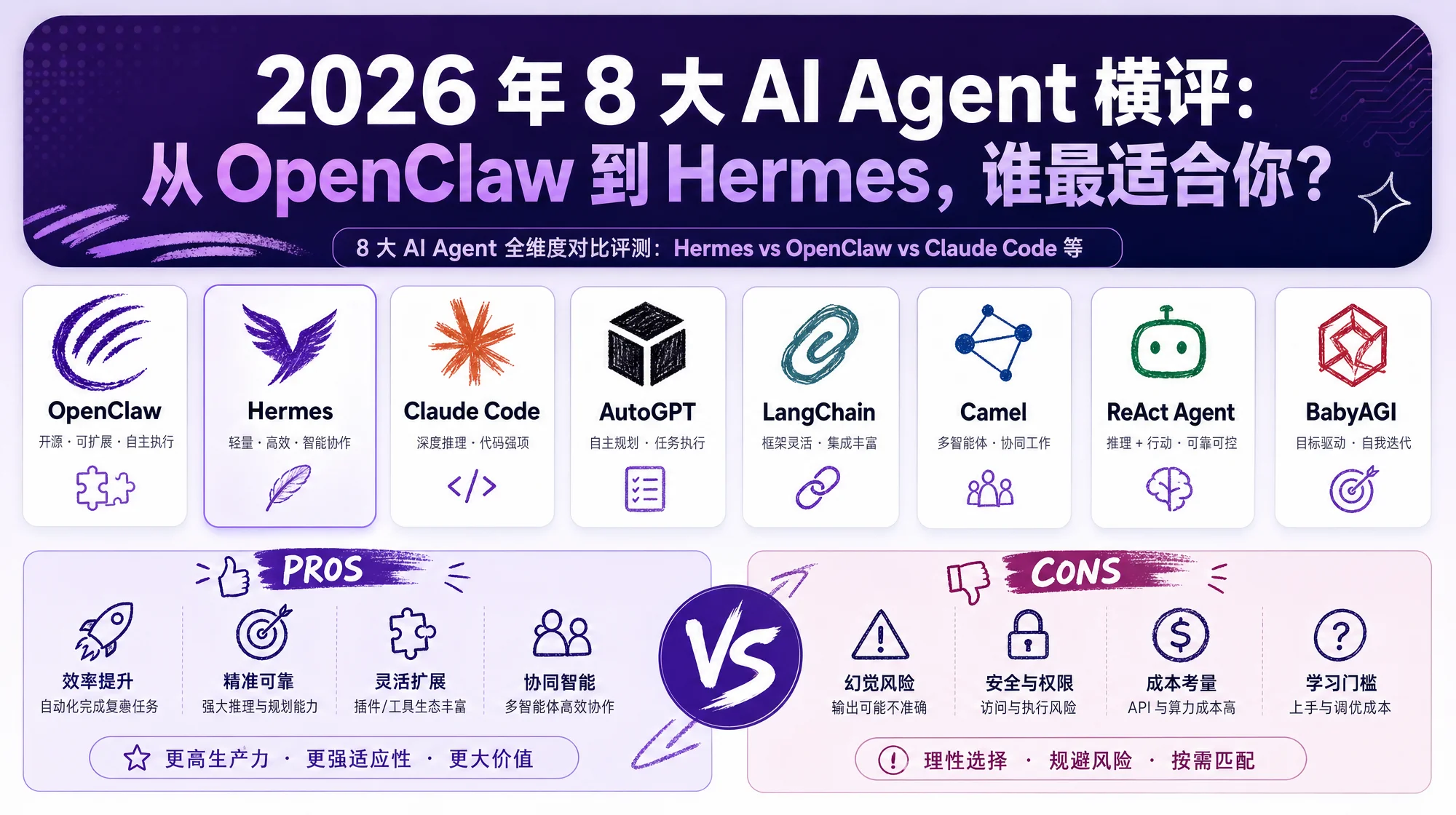
8 大 AI Agent 全维度对比:从 GitHub Stars 到安全记录,从月度成本到真实场景——Hermes 自我进化、OpenClaw 网关编排、Claude Code 编码天花板,附决策树和双修方案。
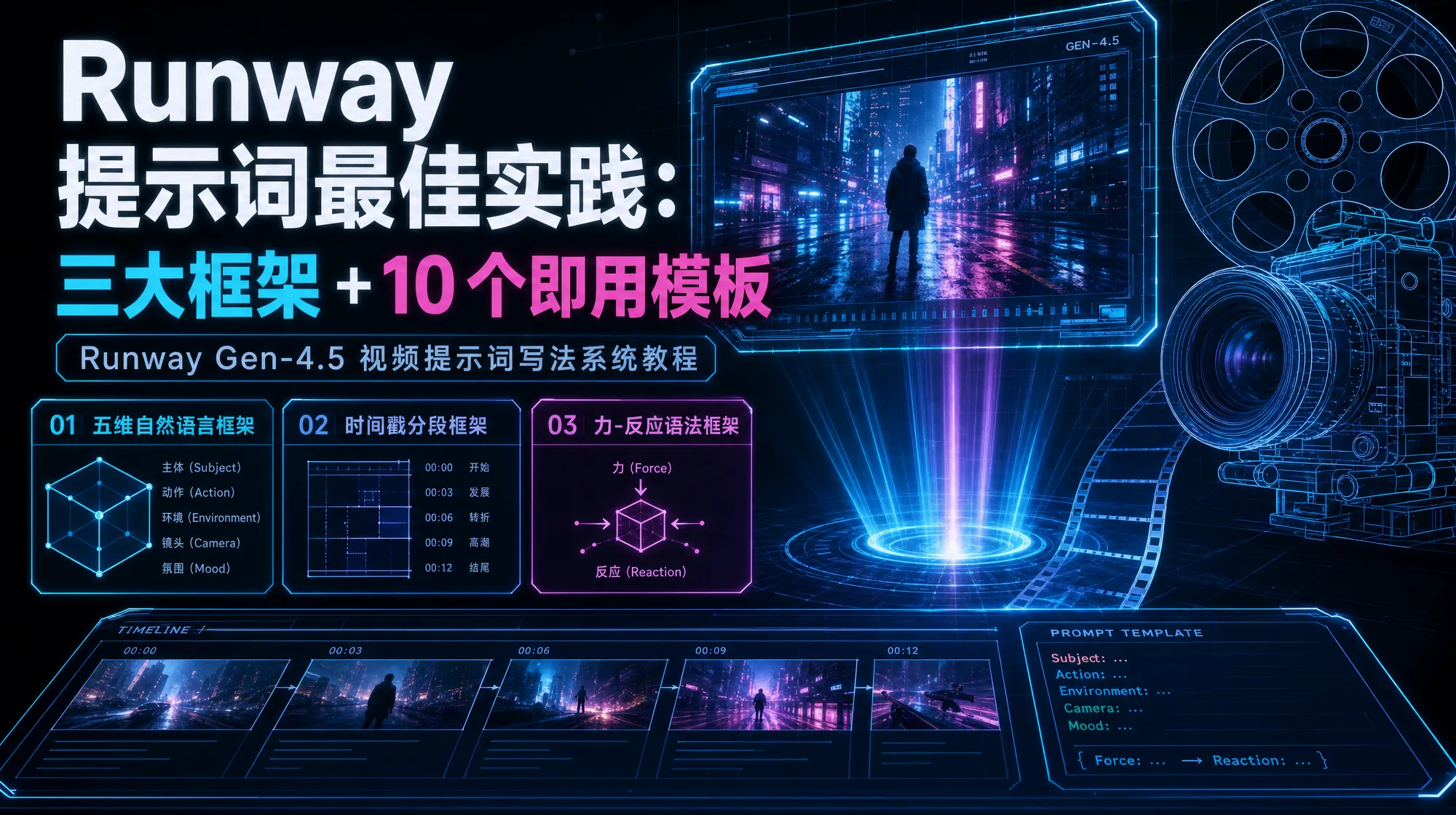
从零掌握 Runway Gen-4.5 视频提示词写法。一个八层统一框架融合五维自然语言、时间戳分段和力-反应语法,附 10 个精选模板和可直接使用的元提示词。
每周精选 AI 编程与自动化实战内容,直达你的邮箱