Hermes Skill 自我进化系统:让 AI 助手越用越聪明
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。
DeepSeek 提示词实战案例指南,精选二十余个覆盖写作、编程、数据分析、翻译、教育等场景的高质量提示词模板。每个案例包含完整提示词原文、参数设定说明、输出效果对比和优化思路。教程区分 DeepSeek V3 和 R1 模型的能力差异,针对不同模型版本给出最佳提示词策略,帮你在日常工作中最大化发挥 DeepSeek 的推理能力。

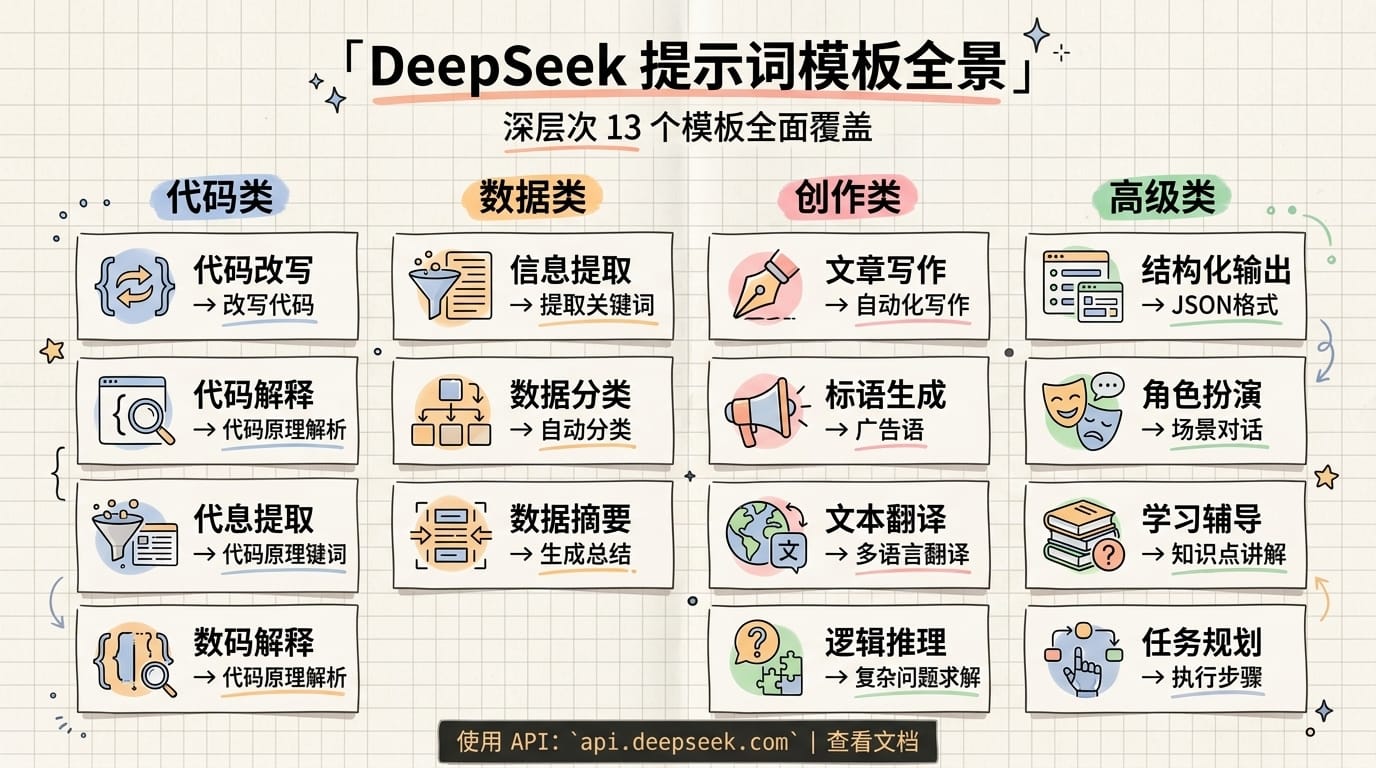
如果给你 13 个提示词模板,你能让 DeepSeek 的输出质量翻一倍吗?这不是夸张——翔宇实测过,同样的任务,用对提示词结构和用随手一写的区别,就是「刚好能用」和「直接交付」的差距。
这 13 个模板不是翔宇自己编的,而是从 DeepSeek 官方文档 整理而来,覆盖代码、写作、数据处理等高频场景。每个模板都经过实测,拿来就能用。
要点速览
| 编号 | 场景 | 核心能力 |
|---|---|---|
| 1 | 代码改写 | 纠错、注释、性能优化 |
| 2 | 代码解释 | 理解复杂代码逻辑 |
| 3 | 数据提取 | 从非结构化文本中抽取信息 |
| 4 | 文章写作 | 生成结构化长文 |
| 5 | 文本分类 | 自动分类归档 |
| 6 | 文本摘要 | 提炼核心要点 |
| 7 | SQL 生成 | 自然语言转数据库查询 |
| 8 | 提示词生成 | 让 AI 帮你写提示词 |
| 9 | 翻译 | 高质量多语言翻译 |
| 10 | 宣传标语 | 创意文案生成 |
| 11 | LaTeX 公式 | 数学公式排版 |
| 12 | 结构化输出 | JSON/表格格式化 |
| 13 | 角色扮演 | 模拟特定专家视角 |
下面逐个展开,每个模板包含使用场景、提示词写法、输出效果。
场景:你有一段能跑但写得不好的代码,想让 AI 帮你优化。
提示词写法:
下面这段代码的效率很低,且没有处理边界情况。
请先解释这段代码的问题与解决方法,然后进行优化:
def fib(n):
if n <= 2:
return n
return fib(n-1) + fib(n-2)
关键技巧:先让 AI 分析问题,再让它给出方案。「先解释再优化」这个顺序会让输出质量更高。翔宇在日常工作中大量使用这个模板来优化自己写的自动化脚本——把写好的代码丢给 DeepSeek,让它先找问题再给方案,翔宇发现这比直接让它「帮我改」效果好得多,因为分析过程本身就帮翔宇理清了代码逻辑中的盲区。
DeepSeek 会指出递归重复计算的问题,提供记忆化递归和迭代两种优化方案,并处理负数输入等边界情况。
进阶用法:如果你使用 DeepSeek-R1(推理模型),可以直接给出代码让它自行分析,不需要提供额外提示。R1 的深度思考链(Chain of Thought)会自动拆解问题。但对于 V3 模型,「先解释再优化」的提示结构依然是最佳实践。更多 DeepSeek 使用技巧详见DeepSeek 五大核心技巧指南。
场景:接手了一段复杂代码,看不懂逻辑。
提示词写法:
请解释下面这段代码的逻辑,并说明完成了什么功能:
[粘贴你的代码]
关键技巧:不需要额外指令,DeepSeek 的推理能力会自动拆解代码逻辑、逐行解释。
进阶用法:对于超长代码(比如几百行的完整模块),可以在提示词中加一个范围限定:「重点解释第 30-60 行的核心逻辑,其余部分简要概括」。这样 AI 不会在不重要的部分浪费篇幅。
场景:你有一段非结构化文本(比如新闻、报告),想从中提取关键信息。
提示词写法:
从以下文本中提取所有提到的公司名称、金额和日期,
以 JSON 格式输出:
[粘贴文本]
关键技巧:明确指定要提取的字段和输出格式。JSON 格式方便后续程序处理。翔宇的经验是:提取的字段越具体,AI 的输出越准确。不要只说「提取关键信息」,而是精确到「提取公司名称、融资金额、融资轮次、日期」——每一个字段都明确命名。
进阶用法:如果文本很长或字段较多,可以先给 AI 一个 JSON Schema 示例:
输出格式示例:
{
"companies": ["公司A", "公司B"],
"amounts": [{"value": 1000, "currency": "万元", "context": "融资金额"}],
"dates": ["2025-01-15"]
}
提供 Schema 后,AI 会严格按照你定义的嵌套结构返回数据,大幅减少后续清洗工作。
场景:需要快速产出一篇有结构的文章。
提示词写法:
写一篇关于中国农业现状的文章,包含以下段落:
第一段:中国农业的现状
第二段:面临的主要挑战
第三段:技术创新的机遇
第四段:未来展望
每段 200 字左右,风格客观中性。
关键技巧:分段指定内容方向 + 字数要求 + 风格约束。三个维度都给到,输出才稳定。
进阶用法:如果你需要更高质量的长文,可以用「两步法」——第一步让 AI 生成大纲,第二步逐段展开:
第一步:为"中国农业现状"这个主题生成一个 5 段式大纲,每段用一句话概括核心论点。
第二步:基于以上大纲,逐段展开,每段 300 字,引用具体数据和案例。
两步法的好处是你可以在大纲阶段就调整方向,避免整篇推倒重来。
场景:大量文本需要按类别归档。
提示词写法:
将以下用户反馈分类为"产品质量""物流服务""售后体验"或"其他":
1. "快递三天才到,包装还破了"
2. "颜色和图片一样,很满意"
3. "退货流程太复杂了"
关键技巧:预先定义好分类标签,让 AI 做选择题而不是开放题。翔宇用这个模板处理过一个实际场景——把三百多条用户评论按情感倾向分类。如果让 AI 自由发挥,它会发明出十几个不同的类别标签,后续根本没法统计。但把分类标签限定为五个选项后,所有输出都整整齐齐,直接导入表格就能做数据分析。
进阶用法:处理大批量分类时(比如上千条反馈),可以要求 AI 输出结构化结果:
请以 JSON 数组格式输出,每条包含 id、原文摘要和分类标签。
如果一条反馈涉及多个类别,列出所有相关标签并标注主要类别。
这样输出可以直接导入 Excel 或数据库处理。
场景:长文章/报告需要快速提炼要点。
提示词写法:
将以下文章总结为 3 个核心要点,每个要点不超过 50 字:
[粘贴长文]
关键技巧:限定要点数量和字数,避免 AI 的摘要比原文还长。
进阶用法:针对不同场景调整摘要粒度:
| 场景 | 提示词调整 |
|---|---|
| 给领导汇报 | "用 3 句话概括核心结论,突出商业影响" |
| 发朋友圈 | "用 1 句不超过 30 字的金句总结" |
| 写读书笔记 | "提取 5 个关键论点,每个配一个支撑论据" |
| 做竞品分析 | "按优势、劣势、机会、威胁四个维度摘要" |
场景:你知道要查什么数据,但不会写 SQL。
提示词写法:
数据库有以下表:
- users (id, name, email, created_at)
- orders (id, user_id, amount, status, created_at)
请生成 SQL 查询:找出最近 30 天内订单总金额超过 1000 元的用户名和邮箱。
关键技巧:先描述表结构,再描述查询需求。表结构越清晰,SQL 越准确。
进阶用法:对于复杂查询,可以要求 AI 输出带注释的 SQL 和执行计划分析:
请生成 SQL 查询并附带以下内容:
1. 每个 JOIN 和子查询的逻辑注释
2. 建议的索引优化方案
3. 如果数据量超过 100 万行,是否需要调整查询策略
这种写法特别适合团队协作——其他人看到你的 SQL 时能快速理解意图。
场景:你想得到更好的 AI 回答,但不知道怎么写提示词。
提示词写法:
你是一位大模型提示词生成专家。
请帮我生成一个"Linux 运维助手"的系统提示词,
要求它能回答常见的 Linux 操作问题,风格简洁专业。
关键技巧:用角色扮演的方式让 AI 生成提示词,效果比自己凭感觉写好得多。翔宇把这个叫做「元提示词」——让 AI 写提示词的提示词。这个技巧在翔宇的工作流里使用频率极高,因为它能帮你快速产出高质量的系统提示词,省去了反复调试的时间。尤其当你需要为不同场景定制多个系统提示词的时候,这个方法能节省翔宇大量的时间和精力。
进阶用法:让 AI 生成提示词时,可以要求它同时输出「正面示例」和「负面示例」:
请帮我生成一个"Linux 运维助手"的系统提示词,并附带:
- 3 个好的用户提问示例(能触发高质量回答的)
- 2 个差的用户提问示例(会导致模糊回答的)
- 对应的优化建议
这样你不仅拿到了提示词,还拿到了使用手册。
场景:需要高质量翻译,不是直译。
提示词写法:
将以下英文翻译为中文,要求符合信达雅标准,语言自然流畅:
[粘贴英文内容]
关键技巧:加上「信达雅」或「语言自然流畅」这类质量约束,翻译质量会明显提升。
进阶用法:不同类型的内容需要不同的翻译策略:
| 内容类型 | 推荐提示词补充 |
|---|---|
| 技术文档 | "保留所有专业术语的英文原文,用括号标注中文释义" |
| 文学作品 | "注重修辞和节奏感,允许意译以保留文学美感" |
| 商务邮件 | "语气正式得体,遵循中文商务书信惯例" |
| 营销文案 | "在传达核心信息的基础上,适配中文消费者的语感和偏好" |
场景:需要产品/品牌的宣传文案。
提示词写法:
你是一个宣传标语专家。请为"希腊酸奶"生成 5 条宣传标语,
要求押韵、口语化、朗朗上口,每条不超过 15 个字。
关键技巧:指定数量 + 风格约束(押韵、口语化)+ 长度限制。
进阶用法:为了得到更多元的创意,可以要求 AI 从不同角度出发:
请从以下 5 个角度各生成 2 条标语:
1. 健康功效角度
2. 口感体验角度
3. 使用场景角度(早餐/下午茶/运动后)
4. 情感共鸣角度
5. 与竞品差异化角度
10 条标语从不同维度覆盖,选择余地大得多。
场景:需要在论文或文档中插入数学公式。
提示词写法:
将以下数学表达式转换为 LaTeX 格式:
x 等于负 b 加减根号下 b 的平方减 4ac,除以 2a
关键技巧:用自然语言描述公式,AI 自动转成 LaTeX 代码。
进阶用法:对于复杂的多行公式推导,可以这样写:
请将以下推导过程转换为 LaTeX 的 align 环境,
每一步标注推导依据,并在关键步骤加注释:
[描述推导过程]
这样输出的 LaTeX 不仅格式正确,还自带推导步骤的文字说明,直接粘贴到论文里就能用。
场景:需要 AI 的输出可以被程序直接读取。
提示词写法:
分析以下产品评价,以 JSON 格式输出,包含字段:
sentiment(正面/负面/中性)、keywords(关键词列表)、summary(一句话总结)
评价:"这个耳机音质不错,但降噪效果一般,电池续航很给力。"
关键技巧:明确定义 JSON 字段名和值的格式,AI 就会严格遵守。
进阶用法:DeepSeek V3 和 R1 都支持在 API 调用中设置 response_format 参数强制 JSON 输出。如果你通过 API 调用,建议结合使用:
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}
)
API 层面强制 JSON + 提示词层面定义 Schema,双重保障输出格式不会跑偏。
场景:需要从特定专业角度获取建议。
提示词写法:
你是一位资深的产品经理,拥有 10 年互联网产品经验。
请对以下产品方案给出专业评价和改进建议:
[粘贴方案]
关键技巧:角色描述越具体(年限、领域、风格),AI 的回答越有专业深度。
进阶用法:多角色联合评审能得到更全面的反馈:
请分别从以下三个角色的视角评价这份产品方案:
1. 产品经理(关注用户需求和商业价值)
2. 技术架构师(关注可行性和技术风险)
3. 市场运营(关注获客成本和竞争格局)
每个角色给出 3 条具体建议。
三个视角交叉验证,比单一角色的建议全面得多。
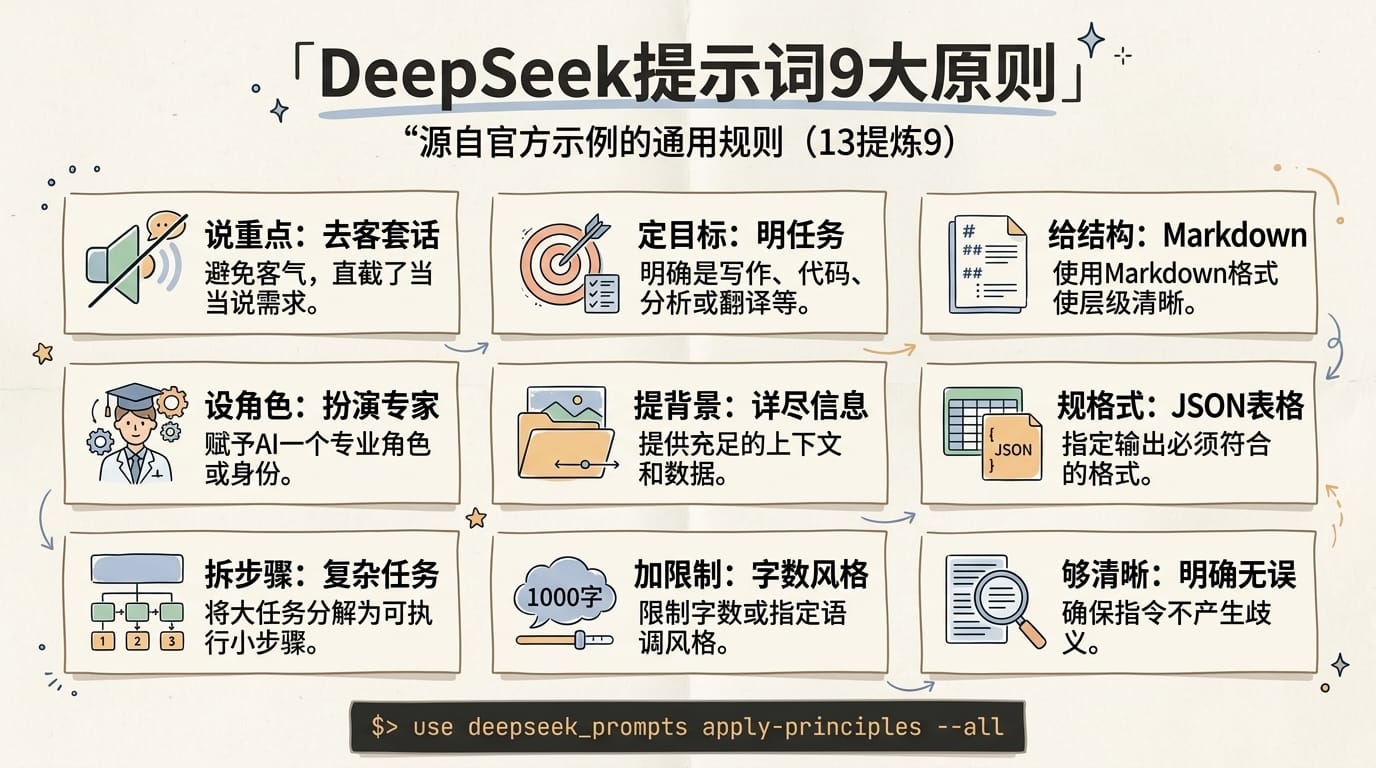
从这 13 个官方示例中,翔宇提炼出这些通用规则:
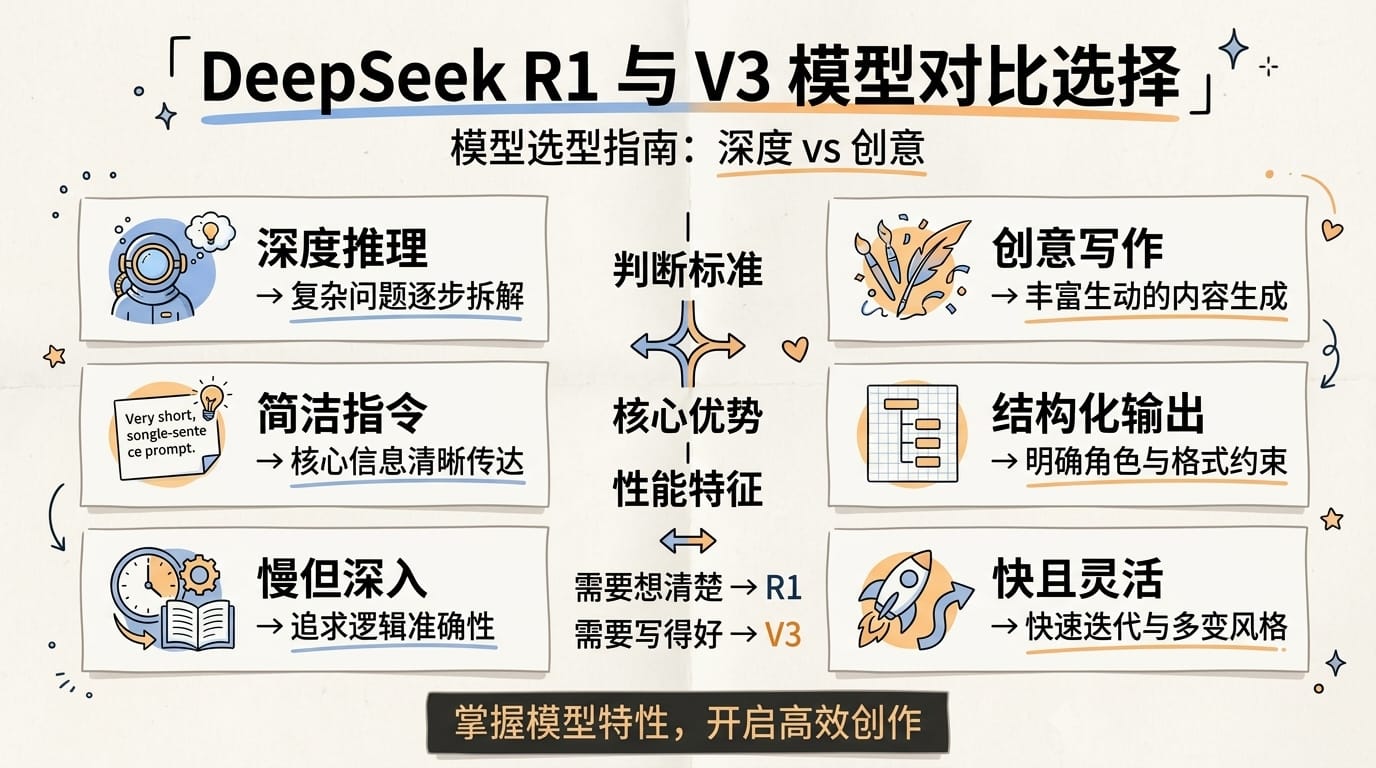
很多人搞不清楚 DeepSeek 的两个主力模型该怎么选。翔宇用一张表说清楚:
| 对比维度 | DeepSeek-R1(推理模型) | DeepSeek-V3(通用模型) |
|---|---|---|
| 核心优势 | 深度推理、数学证明、复杂逻辑 | 创意写作、结构化输出、多轮对话 |
| 提示词策略 | 越简洁越好,让模型自主推理 | 需要明确的角色/格式/约束 |
| Few-Shot | 反而会降低效果(模型会模仿而非推理) | 效果显著,3-5 个示例最佳 |
| 速度 | 较慢(有思考链输出) | 较快 |
| 适合场景 | 算法题、逻辑推导、数学证明 | 本文 13 个模板的大部分场景 |
| 成本技巧 | 放长前缀触发 Context Caching,降低 90% 成本 | 正常调用即可 |
一个实用的判断标准:如果任务需要「想清楚」,用 R1;如果任务需要「写得好」,用 V3。
Q:DeepSeek 是免费的吗?
网页版和 App 免费使用。API 按 Token 计费,价格在主流大模型中属于最低梯队。对于个人用户来说,日常使用成本几乎可以忽略不计。
Q:DeepSeek 和 ChatGPT 相比怎么样?
在中文理解和代码生成方面,DeepSeek V3 的表现已经非常接近 GPT-4o。R1 在数学推理和逻辑任务上甚至有超越。最大的优势是开源——你可以本地部署,数据不出服务器。
Q:提示词写中文还是英文效果更好?
对 DeepSeek 来说,中文提示词的效果不亚于英文。它的中文训练数据充足,不需要刻意用英文写提示词。但如果你的输出目标是英文内容,建议用英文提示。
Q:一条提示词最多能写多长?
DeepSeek V3 的上下文窗口支持 128K Token(约 20 万中文字)。但更长不等于更好——提示词的质量比长度重要得多。把最关键的指令放在开头和结尾,中间放背景资料。
Q:这些模板能用在其他 AI 上吗?
完全可以。这 13 个模板的底层逻辑是通用的——角色设定、结构化指令、格式约束这些方法论适用于 ChatGPT、Claude、Gemini 等任何大模型。区别只在于不同模型对提示词的敏感度不同,微调即可。翔宇实测过把同一个提示词分别用在 DeepSeek V3、ChatGPT 和 Claude 上——结构化输出和角色扮演这两个模板的效果差异最小,基本上换个模型就能用;但代码优化和翻译模板在不同模型间的表现差异较大,需要针对性微调。
分享一个翔宇自己的真实案例。翔宇需要从一份 50 页的行业报告中提取关键数据,整理成结构化的表格,然后生成三个不同角度的分析摘要。
如果手动做,至少要花两到三天。用 DeepSeek V3 配合上面的模板,翔宇是这样操作的:
第一步:用「数据提取」模板(模板 3),让 V3 从报告中提取所有公司名称、融资金额、时间节点,输出 JSON 格式。耗时 2 分钟。
第二步:用「结构化输出」模板(模板 12),让 V3 把 JSON 数据转成 Markdown 表格,按时间排序。耗时 1 分钟。
第三步:用「角色扮演」模板(模板 13),分别从投资人、创业者、行业分析师三个视角生成摘要。耗时 5 分钟。
总耗时:不到 10 分钟,产出质量和人工做三天的结果几乎一样。关键在于每一步都用了精准的提示词模板,而不是模糊地让 AI「帮我分析一下」。
这个案例也验证了一个原则:复杂任务拆成小步,每步用对应的模板,比一次性丢给 AI 一个大任务效果好得多。翔宇现在处理任何复杂任务都会先拆步骤,再逐步喂给 AI。
经过大量实测,翔宇形成了一套 DeepSeek 使用习惯:
response_format 参数强制 JSON 输出,适合需要程序化处理的场景这些模板覆盖了日常工作中最常见的 AI 使用场景。你不需要全部记住——收藏这篇文章,遇到具体场景时回来找对应模板,改改参数就能用。
2026 年 DeepSeek 已经迭代到了 V3.2 和 R1-0528 版本。V3.1 是一次重大更新——它把 V3 和 R1 的优势合并到了一个混合模型中,意味着你不用再纠结「该用 V3 还是 R1」。V3.2 更进一步,在数学和编程评测中达到了和 Gemini 3.0 Pro 同级别的表现。对于日常用户来说,最直观的变化是:模型更聪明了,同时还保持了极低的使用成本。
DeepSeek 作为推理能力突出的开源模型(当前已发展到 V3 和 R1 双线并行,V3 持续迭代优化),最大的特点就是不需要复杂的提示词引导。简单直接的指令,反而能让它发挥得更好。
翔宇的建议是:先从你最常用的两到三个场景开始,把对应模板跑一遍,感受一下「好提示词」和「随便写的提示词」之间的差距。翔宇自己最常用的三个模板是:数据提取(处理各种报告和文档)、结构化输出(和程序对接时必须用 JSON 格式)、角色扮演(从不同专业视角评审自己的内容)。这三个模板覆盖了翔宇日常工作场景的百分之八十以上。
另外一个翔宇想强调的经验:提示词不是一次写好就完事了。同一个任务,翔宇通常会迭代三到四轮提示词。第一轮看 AI 的输出方向对不对,第二轮调整格式和细节要求,第三轮补充约束条件和边界情况。这种迭代过程本身就是在训练你对 AI 能力边界的直觉——用得越多,你越知道怎么写提示词能一次到位。等你建立了直觉,就能自己设计任何场景的提示词了。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
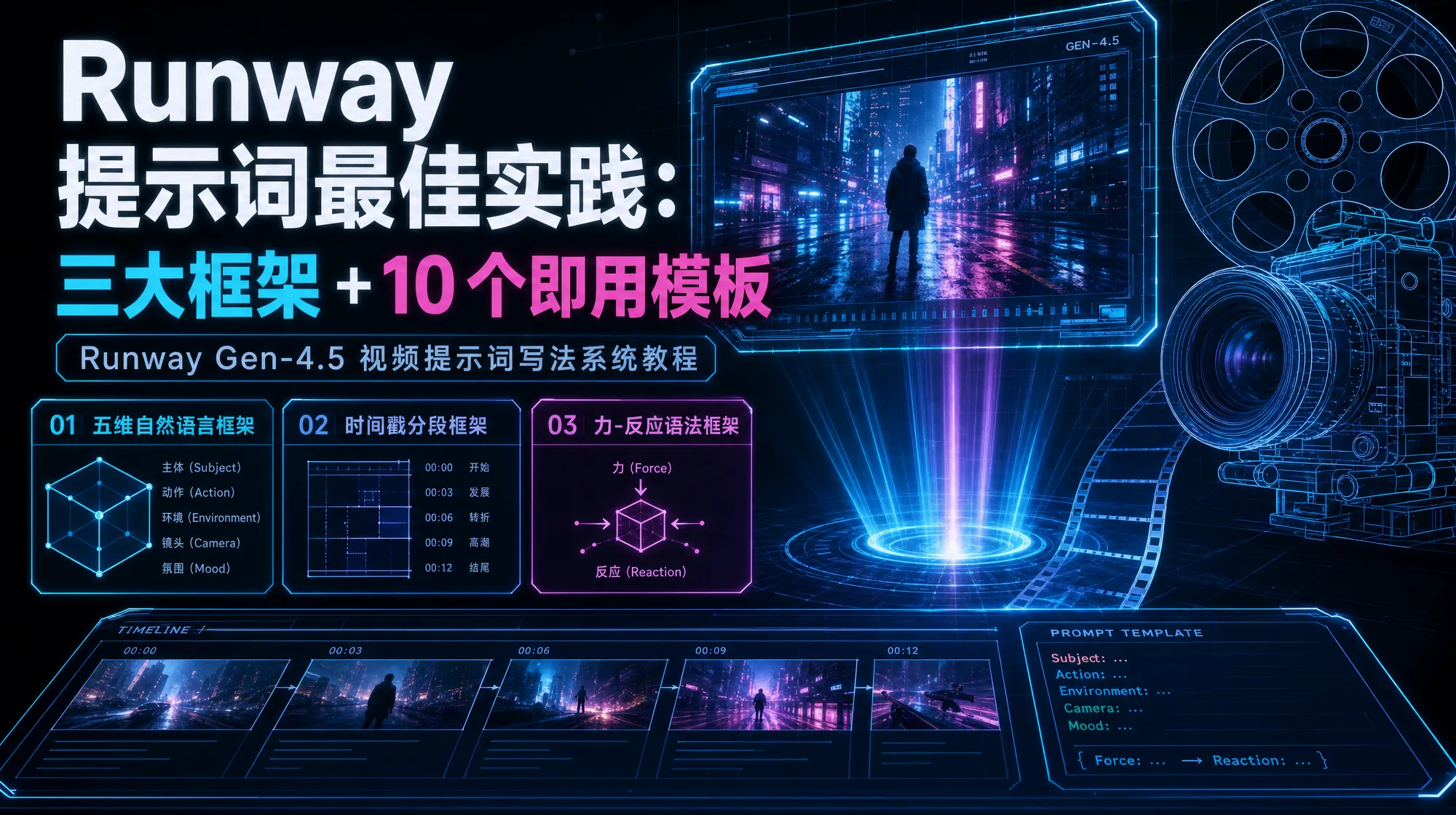
从零掌握 Runway Gen-4.5 视频提示词写法。一个八层统一框架融合五维自然语言、时间戳分段和力-反应语法,附 10 个精选模板和可直接使用的元提示词。

从零掌握 Google Veo 3.1 视频提示词写法。一个八层统一框架覆盖单镜头到时间戳多镜头,附 10 个精选模板和可直接使用的元提示词。

每周精选 AI 编程与自动化实战内容,直达你的邮箱