Hermes Skill 自我进化系统:让 AI 助手越用越聪明
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。
DeepSeek 高效使用技巧教程,从基础对话到高级功能全面讲解。涵盖对话上下文管理、长文档处理、代码生成调试、联网搜索、文件上传分析等核心功能的最佳用法。对比 DeepSeek 与 ChatGPT 和 Claude 在中文写作、逻辑推理和代码能力上的实际差异,针对不同任务场景给出模型选择建议和参数调优技巧,适合想系统掌握 DeepSeek 的新手。

你已经装好了 DeepSeek,也用它聊了几轮——但回答有时候啰嗦、有时候跑题、有时候太官方。下一步不是换模型,而是换你和它说话的方式。
DeepSeek 内置了思维链机制,推理能力很强,能自己拆解复杂问题。但很多人还在用跟普通聊天机器人一样的方式跟它说话,像是拿着一把瑞士军刀只削铅笔。这篇文章给你五个经过翔宇实战验证的核心技巧,帮你真正释放 DeepSeek 的全部潜力。翔宇在教学过程中发现,百分之八十以上的用户遇到的「AI 回答不好」的问题,根本原因都不是模型不行,而是提问方式有优化空间。
截至 2026 年 3 月,DeepSeek 已经从 R1/V3 发展到了 V3.2-Thinking,V4 也即将发布。V4 引入了原生多模态能力、Engram 条件记忆架构和超过 100 万 token 的上下文窗口。核心原则不变:简单直接的提示词 > 冗长复杂的指令。
要点速览
| 技巧 | 一句话说明 | 解决什么问题 |
|---|---|---|
| 提示词减法 | 越简单越好 | 过度指令反而干扰模型推理 |
| 基础结构 | 三要素框架 | 需求表达不清晰 |
| 表达降维 | 让复杂变简单 | AI 回答太专业看不懂 |
| 文风变形 | 切换写作风格 | 输出风格不符合预期 |
| 优化术 | 少即是多 | 示例反而降低质量 |
搞懂了全貌,我们逐个拆解。
这是最反直觉但最重要的一条:DeepSeek 不需要复杂的提示词。
跟其他模型不同,DeepSeek 有内置的推理链,它会自己拆解问题、分步思考。你给的提示词越繁琐,越可能打断它的内部推理流程。就像给一个资深数学家看题——你不需要告诉他怎么思考。
这个特点在 DeepSeek V4 上会更加明显。V4 的 Engram 记忆架构让模型能根据任务上下文选择性地保留和调用信息,过度指令反而会干扰这个自适应过程。
不推荐:
尊敬的 DeepSeek,请您以严谨的学术风格,兼顾可读性与专业性,撰写一篇关于 AI 生成图片发展现状的文章,字数约 500 字左右,请确保内容准确无误,并注意措辞得当,避免使用过于口语化的表达...
推荐:
写一篇 500 字的学术文章,聚焦 AI 绘图模型 FLUX 的最新进展
第二种写法更短,但 DeepSeek 的输出质量反而更高。原因很简单:DeepSeek 的推理链会自动补全你没说的部分——学术文章自然需要严谨、有条理、用专业术语。你说了等于没说,不说反而让模型自由发挥。
初级减法:去掉客气话和冗余修饰
中级减法:去掉 AI 本身就会做的事
高级减法:去掉 AI 能自行推断的上下文
当你需要清晰表达复杂需求时,用这个三要素结构:
翔宇积累了一批高效提示词模板(完整汇总见DeepSeek 官方 13 个提示词模板),直接拿去用:
内容创作类:
数据分析类:
策略规划类:
每一条都是三要素齐全的。拿来就能用。
DeepSeek 的推理能力在多轮对话中表现更好。翔宇的策略是「层层递进」:
第一轮:给出大方向
我想写一篇关于 AI 视频生成工具的对比文章
第二轮:基于回复细化
很好,请聚焦 Kling 3.0、Seedance 2.0 和 Runway Gen-4 这三个工具,从画质、价格、易用性三个维度对比
第三轮:针对具体段落调整
第二段的价格对比请补充最新的定价信息,格式用表格
这种递进式对话比一次性给出所有要求效果更好——每一轮你都在 AI 的输出基础上做精准调整。
DeepSeek 有一个很强的能力:它能把专业内容翻译成任何认知水平的人都能理解的语言。关键在于你怎么触发这个能力。
场景化表达:告诉 AI 你的受众是谁
身份定位:告诉 AI 你是谁
类比法:要求 AI 用熟悉的事物解释不熟悉的概念
限制词汇量:
默认输出:
量子隧穿是指粒子穿越高于自身能量的势垒,这一现象在经典物理学中是不可能的,但在量子力学的框架下,由于波函数在势垒区域不会突然归零而是呈指数衰减,粒子存在一定概率出现在势垒另一侧...
加上「说人话 + 我是文科生」后:
就像你有穿墙超能力。即使面前有 100 米厚的城墙,量子粒子也能像崂山道士一样「嗖」地穿过去,这是量子计算机快如闪电的秘诀之一。在日常生活中不可能发生的事,在极小极小的粒子世界里,是家常便饭。
同一个知识点,降维后理解成本下降了 90%。
翔宇总结的三条原则:
DeepSeek 对中文写作风格有深入的理解。你可以直接指定目标风格,它会模仿得很到位。
这是国产模型的独特优势——内嵌了海量中文本土化知识,不管是网络用语、名人信息还是新闻资讯,都能精准匹配。
翔宇整理了一张 DeepSeek 最擅长的风格矩阵:
| 风格类型 | 触发关键词 | 特点 | 适合场景 |
|---|---|---|---|
| 文学大家 | 莫言风/余华风/鲁迅风 | 浓厚文学味 | 故事性内容 |
| 品牌文案 | 苹果体/耐克体 | 简洁有力 | 产品推广 |
| 社交平台 | 小红书风/知乎风/微博风 | 平台调性精准 | 社媒内容 |
| 新闻体 | 新华社风/财新风 | 客观严谨 | 新闻报道 |
| 口语化 | 脱口秀风/播客风 | 轻松幽默 | 视频脚本 |
指令:用莫言风格写现代写字楼
输出:写字楼像老家腌咸菜的缸,电梯里的人都有隐形条形码,仿佛前世注定要在第 27 层相遇又不打招呼...
指令:用苹果风格写手表广告
输出:时间本该自由生长。Watch X 系列打破界限,重构时间生态。这不是手表,而是时间的文艺复兴。
指令:用小红书风格写防晒推荐
输出:姐妹们!!!这个防晒我真的后悔没早用!去三亚一整天没晒黑一个度!SPF50+但完全不假白不搓泥,成膜超快,干皮油皮都能用...
你甚至可以混搭风格:
用知乎高赞答案的逻辑结构 + 小红书的表达语气,写一篇关于选显示器的攻略
DeepSeek 能准确理解这种混搭指令——逻辑严密但表达活泼。
翔宇发现 DeepSeek 对风格模仿的能力已经超越了简单的关键词触发。你可以直接给它一段目标风格的文字样本,让它分析风格特征后模仿。比如你特别喜欢某位作者的写作风格,可以把那位作者的一段文字发给 DeepSeek,然后说"分析这段文字的写作风格特征,然后用同样的风格写一篇关于某某主题的文章"。翔宇实测这种"样本分析加模仿"的方法比单纯说"用某某风格"效果更精准,因为模型能捕捉到更多微妙的风格细节——句式长短、用词偏好、修辞手法、段落节奏等。
另外一个进阶玩法是"渐变风格":你可以让 DeepSeek 在一篇文章中从一种风格渐变到另一种风格。比如"开头用学术论文的严谨风格引出问题,中间用知乎高赞答案的通俗风格展开分析,结尾用小红书的轻松风格做总结"。这种多风格融合在长文创作中特别有价值。
这一条特别针对 DeepSeek 这类推理模型:放弃 few-shot 示例。
研究表明,在 DeepSeek 的提示词中加入示例(few-shot)反而会降低模型性能。这违反直觉,但数据支持这个结论。Zero-shot 提示(不提供示例,直接给指令)往往能获得最佳结果。
原因在于 DeepSeek 被训练成独立思考的模型。告诉它目标,而不是事无巨细地指导,避免打断它自身的推理链路。
虽然 DeepSeek 通常不需要示例,但有两种情况是例外:
除此之外,零示例 + 明确指令 = 最佳效果。
| 维度 | 推理模型(DeepSeek R1/V4) | 普通模型 |
|---|---|---|
| 示例 | 不需要,零示例最佳 | 1-3 个示例有帮助 |
| 指令长度 | 越短越好 | 可以详细一些 |
| 思维过程 | 不需要指导,模型自己推理 | 可以用 CoT 提示 |
| 角色设定 | 简短即可 | 详细角色描述有帮助 |
| 约束条件 | 只写必要的 | 可以多写一些 |
记住这条规则:最好的提示词往往是最简单的那个。
翔宇走过这条路,对比测试了多个模型后发现:DeepSeek 在中文文本生成、风格转换和创意写作上已经比肩甚至超越了国际顶尖模型。
这不是偶然。DeepSeek 基于海量中文语料训练,对中文的语感、修辞、文化背景的理解是刻在模型权重里的。当你需要写地道的中文内容时,国产模型的优势是结构性的。
DeepSeek V4 即将带来的新能力值得关注:
| 场景 | 推荐模型 | 技巧组合 | 效果 |
|---|---|---|---|
| 中文创作 | DeepSeek V3/V4 | 减法 + 文风变形 | 最佳 |
| 代码编写 | DeepSeek Coder/V4 | 减法 + 三要素 | 很好 |
| 数据分析 | DeepSeek V3 | 三要素 + 精简上下文 | 很好 |
| 学术写作 | DeepSeek V3 | 降维 + 文风变形 | 好 |
| 客服对话 | DeepSeek V3 | 减法 | 好 |
这 5 个技巧不只适用于 DeepSeek,对任何推理型大模型都有效。
翔宇分享一个真实的工作案例,展示如何综合运用五个技巧完成一个完整的任务。
任务:为一个 AI 教程频道写一期十分钟视频的口播脚本,主题是"零基础学习 AI 编程的五个步骤"。
第一轮(减法加三要素):
翔宇只给了一句话:"写一个十分钟视频脚本,主题是零基础学 AI 编程的五个步骤,面向完全没有编程经验的职场人"。
DeepSeek 生成了一个结构完整但措辞偏专业的初稿。
第二轮(降维):
翔宇追加一句:"用我教小学生学编程的语气重写,每个专业概念都要配一个生活化的类比"。
输出立刻变得通俗易懂。
第三轮(文风变形):
翔宇继续细化:"语气再轻松一些,像脱口秀风格,适当加入自嘲和幽默"。
最终输出既专业又有趣,直接可用。
整个过程不到十分钟,三轮对话就完成了一个过去需要两到三小时的脚本撰写任务。关键在于:每一轮只调整一个维度,不贪多不着急,让模型逐步逼近你的预期。核心思想就一条:信任模型的推理能力,你只需要说清楚目标。
翔宇在日常工作中有一套固定的 DeepSeek 使用工作流,分享出来供参考。
早上九点到十一点(创作时段):用 DeepSeek V3 做长文创作。利用减法技巧加文风变形,快速生成文章初稿。翔宇通常在这个时段能完成两到三篇初稿。
下午两点到四点(分析时段):用 DeepSeek 做数据分析和策略规划。利用三要素结构清晰表达分析需求,让模型帮翔宇整理数据洞察和行动建议。
晚上八点到九点(学习时段):用 DeepSeek 做知识降维。把当天阅读的专业文章或技术文档扔给它,让它用通俗语言帮翔宇梳理要点。这种方式比自己逐字阅读效率高三到四倍。
翔宇每天和 DeepSeek 的对话量大约在三十到五十轮,覆盖写作、分析、翻译、代码和学习等多个场景。五个技巧已经内化成了习惯——写提示词时自动用减法精简、自动套三要素结构、自动选择合适的风格。这种"无意识的高效"才是技巧掌握的最终形态。
最后翔宇分享一个关于 DeepSeek V4 的展望。根据公开信息,V4 预计在二零二六年四月发布,将带来万亿参数级别的多模态理解能力、超过百万级别的上下文窗口和全新的条件记忆架构。这意味着未来你可以一次性把整个项目的所有文件交给 DeepSeek 分析,模型能在超长对话中精准保持上下文。翔宇非常期待这些新能力,它们将再次改变我们和 AI 协作的方式。更重要的是 DeepSeek 一贯坚持权重开源的策略,这意味着企业和个人开发者可以在本地部署和微调 V4 模型,对数据敏感型场景来说这是极大的利好。翔宇预测 V4 发布后,国内的 AI 应用开发将迎来新一轮爆发,尤其是在中文内容创作、智能客服和企业知识管理这三个方向。持续关注 DeepSeek 的官方动态和开源社区,第一时间试用和理解新模型的特性,才能抢占先发优势赢得市场竞争的主动权。
翔宇的建议:把这 5 个技巧打印出来贴在显示器旁边,每次和 AI 对话前扫一眼。一个月后你会发现,你和 AI 的沟通效率已经比 90% 的人高了。
翔宇在日常工作中不会只用一个模型,而是根据任务特点选择最合适的工具。DeepSeek 的强项是中文创作和风格控制,但在某些场景下和其他模型配合效果更好。
翔宇常用的组合方式是:先用 DeepSeek 做中文初稿的创作和风格定调,因为它对中文的理解和表达能力确实是一流的;然后用 Claude 做逻辑检查和事实核验,因为 Claude 的推理严谨性和格式遵循度非常好;最后如果需要处理超长文档或做跨文件分析,用 Gemini 的百万级上下文窗口。
这种多模型协作的工作方式看起来复杂,但实际上每个步骤都很快。翔宇完成一篇五千字长文的全流程——从选题到初稿到检查到定稿——通常只需要一到两个小时。这在没有 AI 辅助的时代可能需要半天甚至一整天的时间。
看场景:中文写作和理解首选 DeepSeek,英文内容和多模态任务 ChatGPT 更强。两者都免费可用,建议同一个任务两边都试,用输出质量说话。
恰恰相反。DeepSeek 有内置推理链,过度指令会干扰它的思考过程。核心原则是「三要素」:做什么 + 做成什么样 + 特殊要求,其余让模型自己补全。
复杂推理、数学计算、代码调试、多步骤分析时开启深度思考。简单对话、日常写作不需要——会变慢且不一定更好。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
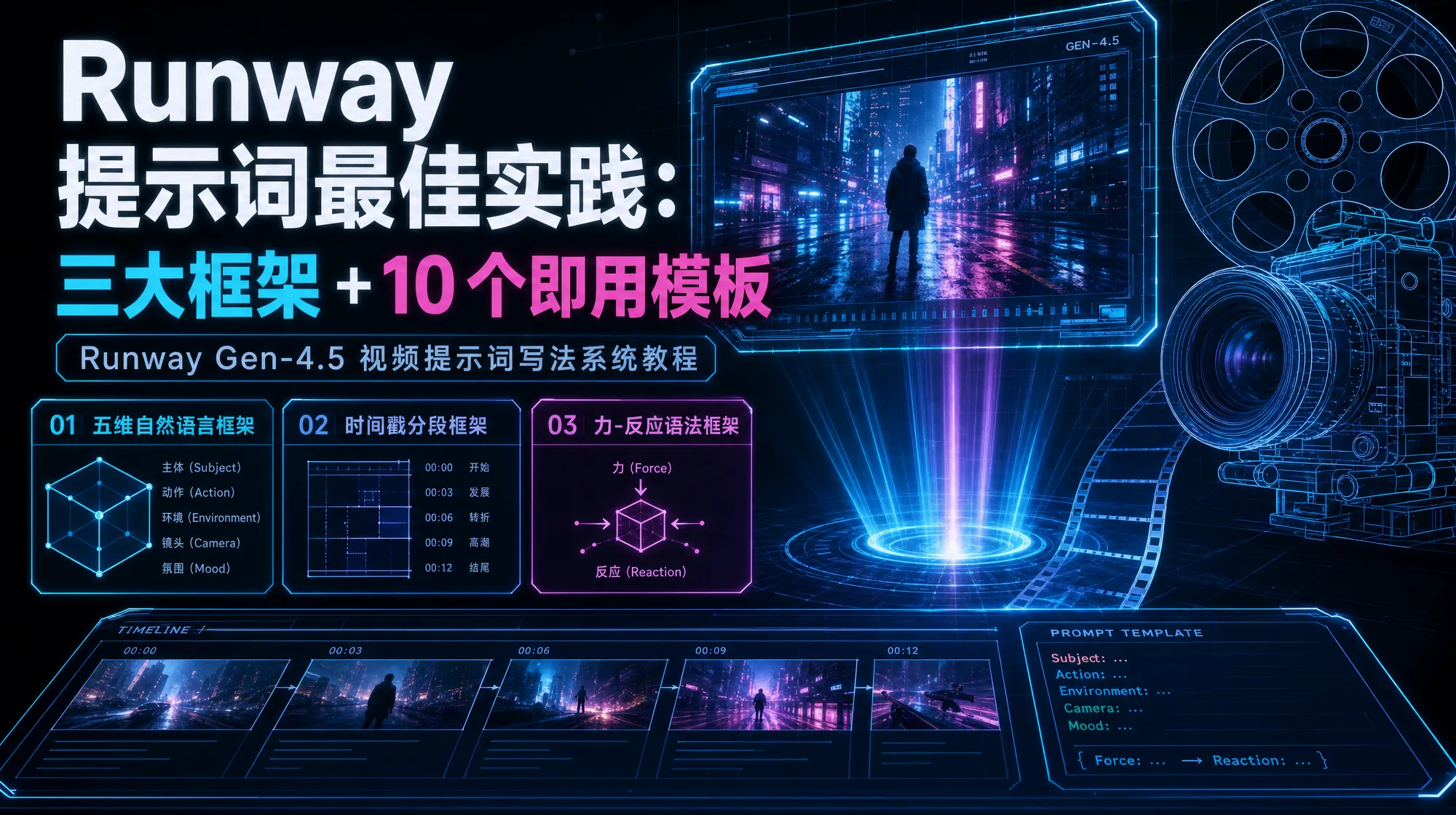
从零掌握 Runway Gen-4.5 视频提示词写法。一个八层统一框架融合五维自然语言、时间戳分段和力-反应语法,附 10 个精选模板和可直接使用的元提示词。

从零掌握 Google Veo 3.1 视频提示词写法。一个八层统一框架覆盖单镜头到时间戳多镜头,附 10 个精选模板和可直接使用的元提示词。

每周精选 AI 编程与自动化实战内容,直达你的邮箱