Hermes Skill 自我进化系统:让 AI 助手越用越聪明
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
Hermes Agent 的 Skill 系统是它被称为「自我进化 Agent」的核心原因。Agent 在完成复杂任务后自动将解法保存为可复用技能,下次遇到类似问题直接加载,遇到新问题自动修补。本文拆解 Skill 创建触发条件、自我改进机制、Curator 自动优化、渐进式披露的 Token 优化策略、155+ 内置 Skill 全景,以及从零写一个 Skill 的完整实操步骤。
拆解 136 个开源循环,发现 85% 只适用于代码类任务、失败原因都是终止条件缺失。本文讲清循环工程的本质,并提供一个四步循环设计 Skill,复制即用。
Hermes Agent 的 Gateway 支持 22+ 消息平台同时接入,一个后台进程管全部。本文从零搭建 Telegram Bot + Discord 服务器 + 微信 iLink Bot 三平台联动,含可复制配置、品牌分区频道设计和跨平台上下文共享机制。
覆盖内容生产、数据采集、社交运营、SEO、电商、办公六大场景的 Make 自动化工作流实战指南。28 篇深度教程串联成完整体系,从零搭建到批量产出。

Make(原 Integromat)是低代码自动化领域的瑞士军刀——不写代码,拖拽连线,就能把几十个应用串成全自动流水线。过去一年,我用 Make 搭了 28 套自动化场景,覆盖内容生产、社交运营、数据采集、知识管理、办公效率和工作流方法论六大方向。这篇指南把这 28 个真实场景按类组织,每个场景都有完整教程链接,从零搭建到批量产出,形成一套可复用的自动化体系。
要点速览
Make 的核心是一张可视化画布。你在画布上放置模块(Module),每个模块对应一个应用或操作——读取 RSS、调用 OpenAI、发送到 Notion、推送到微信。模块之间用连线表达数据流向,数据从左到右流过整条管线,每个模块处理完后把结果传给下一个。
💡 通俗讲:如果说 Zapier 像搭积木——一块接一块往上垒,那 Make 更像画电路图——你可以分叉、合流、循环、加条件判断。灵活度差了一个量级。
这个定位决定了 Make 的适用边界:单步触发用 Zapier 更省事,多步骤、有分支、需要循环或错误重试的场景,Make 是更好的选择。和 n8n 比,Make 是全托管服务不用管服务器,n8n 则给你完全的数据控制权和自托管自由。
Make 免费计划提供每月 1000 次操作,足够跑通本指南中大多数场景的测试。
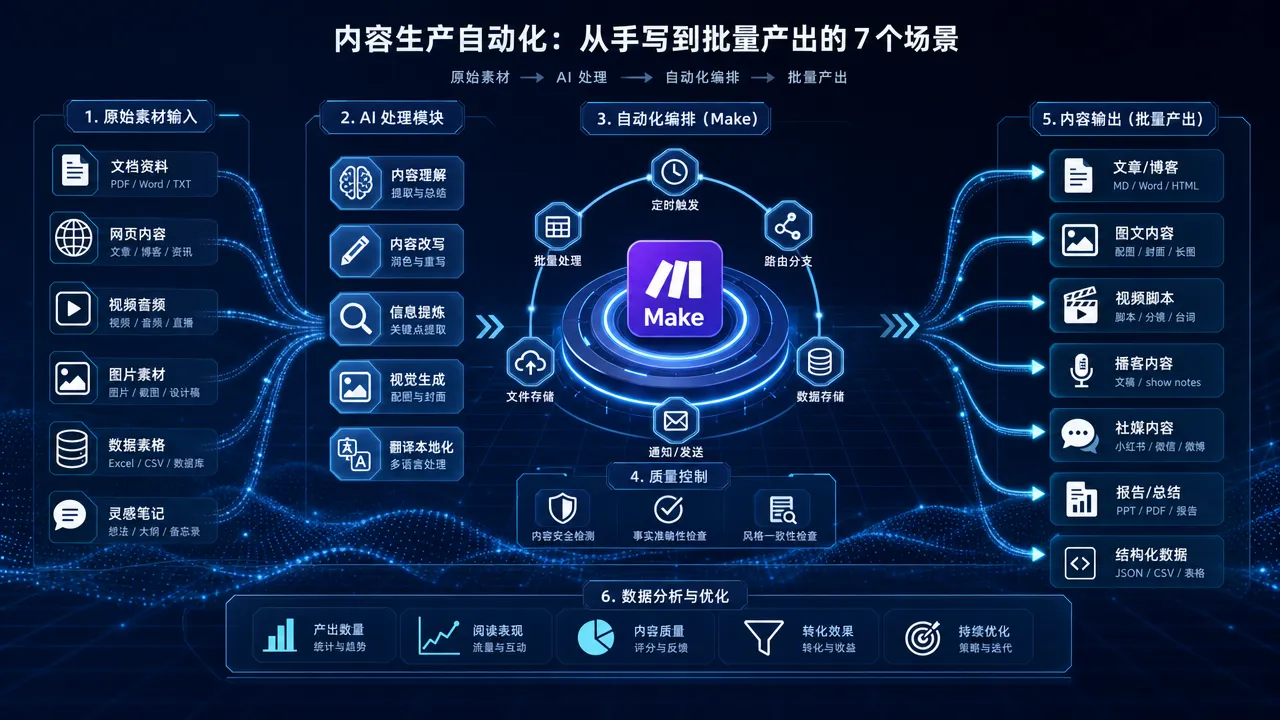
内容创作是 Make 自动化最直接的发力点。手工写一篇公众号文章要 3-4 小时,搭好自动化管线后,素材采集、大纲生成、初稿撰写、排版发布可以全链路串联,人只需要在关键环节做质量把控。
公众号运营最消耗时间的不是写作本身,而是从选题到排版到发布的重复操作。在 公众号批量文章自动化 这篇教程里,我用 Make 串联了 Notion 选题库、AI 写作模块和公众号发布接口,实现了从选题到草稿的全链路自动化。一个场景跑下来,每天早上 Notion 里的选题自动变成公众号草稿箱里的待审稿件。
长文写作对模型能力要求更高,单靠一个模型不够稳定。OpenRouter 批量长文写作 的方案是用 OpenRouter 做模型聚合层——大纲用一个模型,展开用另一个模型,润色用第三个。Make 的 HTTP 模块配合 OpenRouter 的统一接口,一套场景就能调度多个大语言模型协作完成长文。
好的自动化输出取决于好的提示词。高质量提示词工厂 是一个专门生产和迭代提示词的场景:把写作需求输入 Notion,Make 自动调用模型生成提示词初版,再经过评估模块打分,低于阈值的自动重写。跑几轮下来,提示词库的平均质量比手工写的高出一截。
内容创作不只是写——还有采集和改写。Firecrawl 博客自动化 用 Firecrawl 抓取目标网站内容,经 Make 管线清洗结构化后,喂给 AI 模型做摘要或改写,最终自动发布到博客。整条管线的关键是 Firecrawl 的结构化抓取能力,把网页 HTML 变成干净的 Markdown,让下游处理事半功倍。
图文内容的自动化难度更高。Flux 儿童绘本自动化 是一个把文字故事变成绘本的管线:Make 读取故事脚本,逐页生成插画提示词,调用 Flux 模型生成插图,最后拼合成完整绘本 PDF。风格一致性是这个场景的核心挑战——教程里有专门的风格种子锁定方案。
短视频时代,文字内容需要转化成视频脚本。多模态爆款脚本 把文章、数据报告等文字素材,经 Make 管线转化成视频脚本——包括分镜、旁白、字幕和配图提示词。一篇素材进去,一套可直接拍摄的脚本包出来。
Make 提示词自动化技巧 是提示词工厂的进阶版,聚焦在 Make 场景中提示词的动态拼接和版本管理。核心技巧包括:用 Make 变量实现提示词模板化、用数据存储管理提示词版本、用条件路由根据内容类型选择不同提示词策略。
🔍 深入一步:内容生产的 7 个场景看上去各自独立,实际部署时建议串联使用——提示词工厂负责产出高质量提示词,长文写作场景消费这些提示词批量生产内容,博客自动化场景负责采集补充素材。三者通过 Webhook 衔接,形成「素材采集 → 提示词优化 → 内容生产」的闭环。
内容生产完,下一步是分发。社交平台各有规则——小红书要竖版图文、Twitter 限 280 字符、Instagram 重视视觉、微信生态有自己的分享机制。手工逐平台适配是时间黑洞,Make 可以在一条管线里完成多平台格式转换和定时发布。
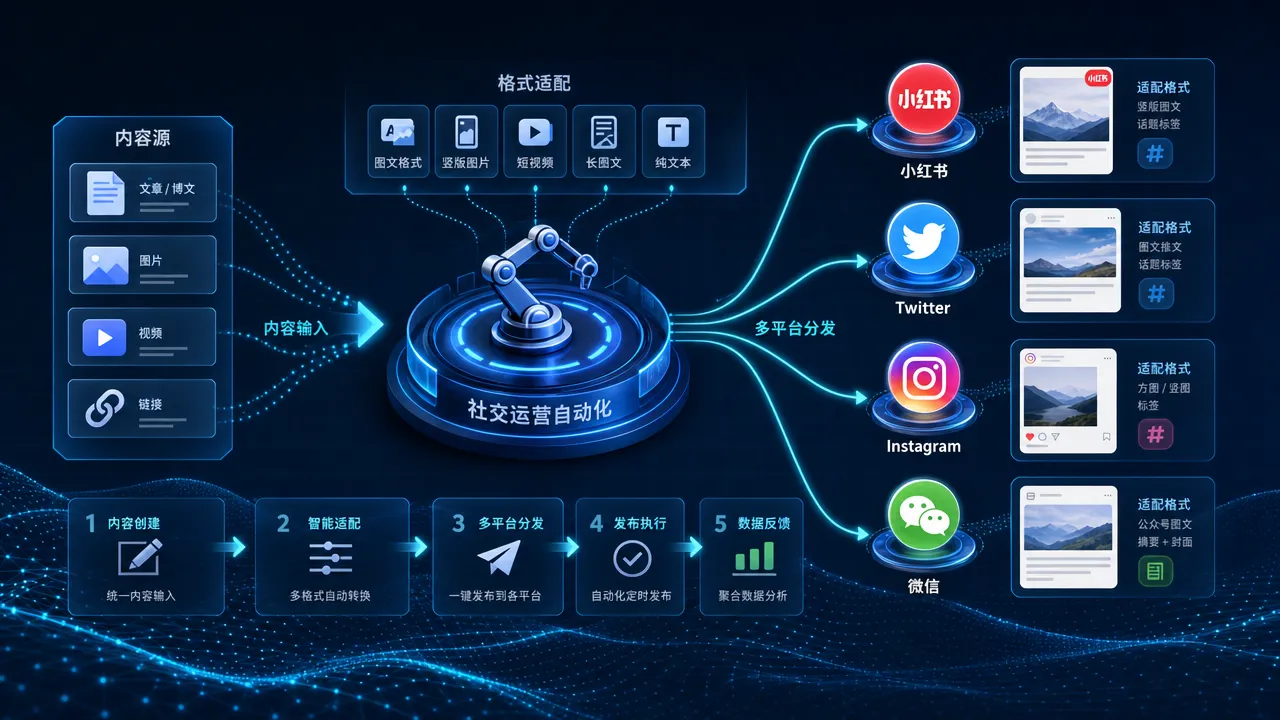
小红书的流量逻辑是「封面决定点击,正文决定收藏」。小红书内容自动化 搭建了一条从选题到发布的完整管线:Notion 选题触发 → AI 生成笔记文案 → 自动配图 → 格式适配 → 排期发布。关键模块是图文格式转换——小红书对图片比例、文字排版有严格要求,教程里有详细的适配方案。
批量运营多个小红书账号时,差异化头像是基础需求。小红书头像自动化 用 Replicate 的图像生成模型,通过 Make 批量生成风格统一但内容各异的头像。输入人设描述,输出适配小红书圆形裁切的头像图。
跨平台内容复用是效率杠杆。小红书 Instagram 图视频自动化 把同一批素材同时适配小红书和 Instagram 两个平台——竖版 9:16 给小红书,正方形 1:1 给 Instagram,视频自动裁切加字幕。一套素材两个平台,省去二次制作。
Twitter(现 X)的短文本特性让自动化更精炼。Twitter 自动化 把长内容压缩成适合 Twitter 传播的短文本,保留核心信息的同时符合字符限制。Make 管线里的关键模块是摘要提取和字符数控制——AI 生成的初版往往超长,需要自动裁剪到合适长度。
微信和小红书的用户群有大量重叠。微信小红书联动自动化 用 Exa AI 做智能搜索引擎,自动发现两个平台的热门内容趋势,然后生成适配各平台格式的内容。核心价值是趋势发现——不再靠手工刷信息流找灵感,AI 帮你扫。
⚠️ 常见踩坑:社交运营自动化最常见的问题是过度自动化——全自动生成+全自动发布的内容很容易被平台识别为低质。推荐的做法是自动化到「草稿」环节,人工过一遍再发布。Make 的暂停模块可以在管线中间插入人工审核节点。
自动化的前提是有数据输入。手工复制粘贴是最原始的数据采集方式,Make 可以把 RSS、API、爬虫等采集手段编排成定时运行的管线,让信息自动流入你的知识库。
RSS 可能是最被低估的信息采集工具。RSS 到 Notion 自动化 把 RSS 源的新文章自动归档到 Notion 数据库——标题、摘要、链接、发布时间,结构化存储,全文可搜索。我用这个场景监控了 200+ 个技术博客和新闻源,每天自动入库,不再遗漏重要更新。
YouTube 是深度内容的宝库,但手工整理视频信息太慢。Apify YouTube 数据采集 用 Apify 爬取目标频道或关键词下的视频信息——标题、描述、播放量、评论数——经 Make 管线清洗后存入 Notion。做竞品研究或内容策划时,数据先行比感觉靠谱。
新闻资讯的时效性要求高。Jina Reader 新闻自动化 用 Jina Reader 把新闻网页转成干净的结构化文本,再经 GPT 做摘要和分类,按主题归档到 Notion。每天早上打开 Notion,当天的行业动态已经分门别类摆好了。
播客是另一个信息密度极高的信源。播客日报自动化 把播客 RSS 订阅的新集自动做转录和摘要——Make 管线读取播客 RSS,下载音频文件,调用语音转文字服务,再用 AI 提取关键要点。每天一份播客日报,不用戴耳机也能跟进行业信息。
💡 通俗讲:数据采集的 4 个场景本质是搭了一套「个人信息过滤器」。互联网信息太多,全部手工看不现实。用 Make 把采集、过滤、归档串起来,你每天只需要看过滤后的结果——从信息消费者变成信息管理者。
采集来的数据堆在那里没用,要变成可检索、可复用的知识资产才有价值。知识管理自动化处理的就是这个「从数据到知识」的过程。
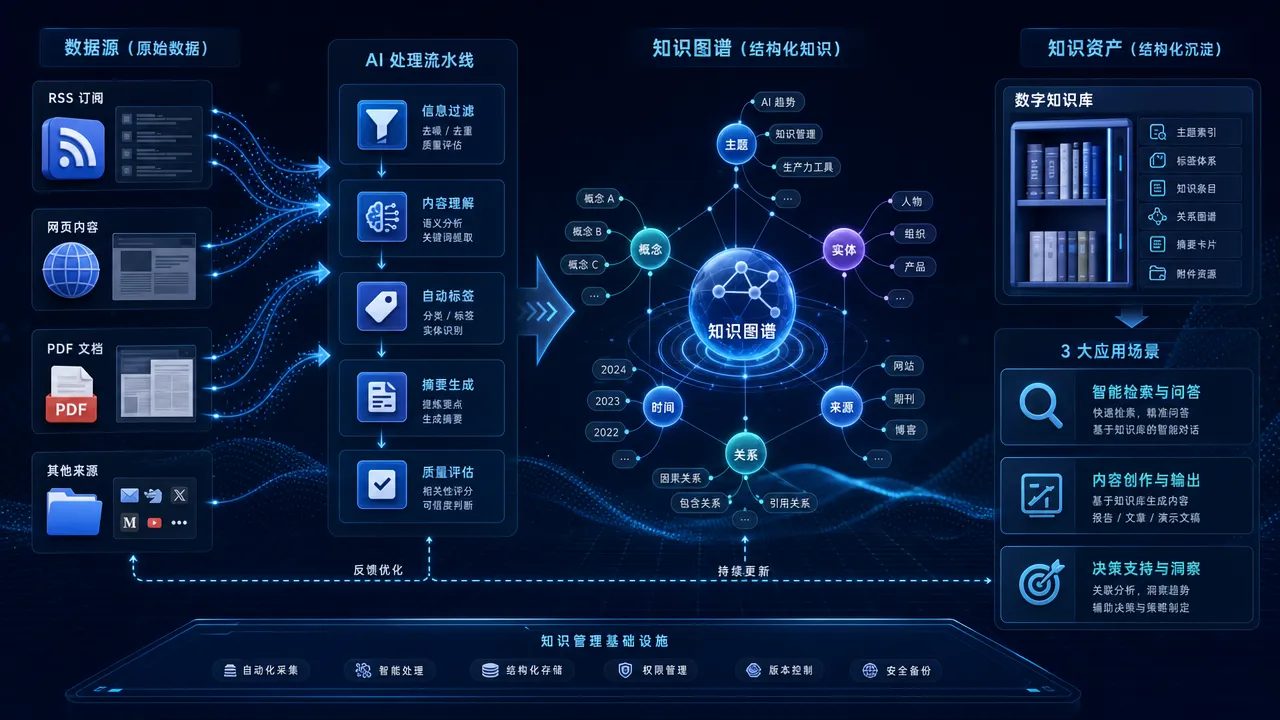
Notion 是很多人的知识管理中枢,但手工维护数据库太累。Notion 数据库自动化 用 Make 实现了 Notion 数据库的自动维护——新条目自动打标签、自动关联相关条目、过期内容自动归档。把 Notion 从手工记录工具变成自运转的知识系统。
读书笔记、文章收藏、视频笔记散落在不同地方。数字图书馆自动化 用 Make 搭建了一个自动化的个人图书馆——不同来源的内容经管线统一格式后汇入 Notion,按主题自动分类,重复内容自动去重。读过的东西不再沉没,随时可检索调用。
电商内容需要大量产品描述、卖点文案、客服话术。RAG 电商内容工作流 用 RAG(检索增强生成)架构搭建了电商内容管线——产品数据库作为知识库,Make 管线接收写作需求后先检索相关产品信息,再喂给 AI 模型生成贴合产品实际的内容。比纯 AI 生成的内容更准确,因为有真实产品数据兜底。
🔍 深入一步:知识管理场景的关键不是工具选择,而是数据结构设计。Notion 数据库的字段设计、标签体系、关联关系,决定了后续自动化的天花板。建议先花半天设计好数据结构,再开始搭 Make 管线。
不是所有自动化都和内容创作有关。日常办公中的 PDF 处理、文献研究、文档翻译——这些重复性高但不可省略的工作,也是 Make 自动化的好标的。
PDF 是办公场景的通用格式,但 PDF 内容的提取和处理一直是痛点。Kimi PDF 自动化 用 Kimi 的长文档理解能力,通过 Make 管线批量处理 PDF 文件——提取关键信息、生成摘要、回答预设问题。一批合同、一摞报告,丢进去自动出分析结果。
做研究最耗时的是文献阅读和整理。批量文献研究自动化 把文献搜索、下载、摘要、归档串成自动化管线——输入研究主题和关键词,Make 自动搜索文献数据库,下载 PDF,用 AI 提取每篇的核心论点和方法论,整理成结构化的文献综述初稿。
跨语言文档处理是刚需。PDF 翻译工作流 用 Make 搭建了一条 PDF 翻译管线——上传 PDF 后自动提取文本、分段翻译、保持原文排版格式。翻译质量可以通过切换不同模型来调整——日常文档用 DeepSeek 够用,正式文件切 GPT-4 或 Claude 提质。
工具和场景讲完了,更重要的是方法论。单个场景好搭,多个场景怎么组合成体系?工作流怎么扩展而不崩溃?
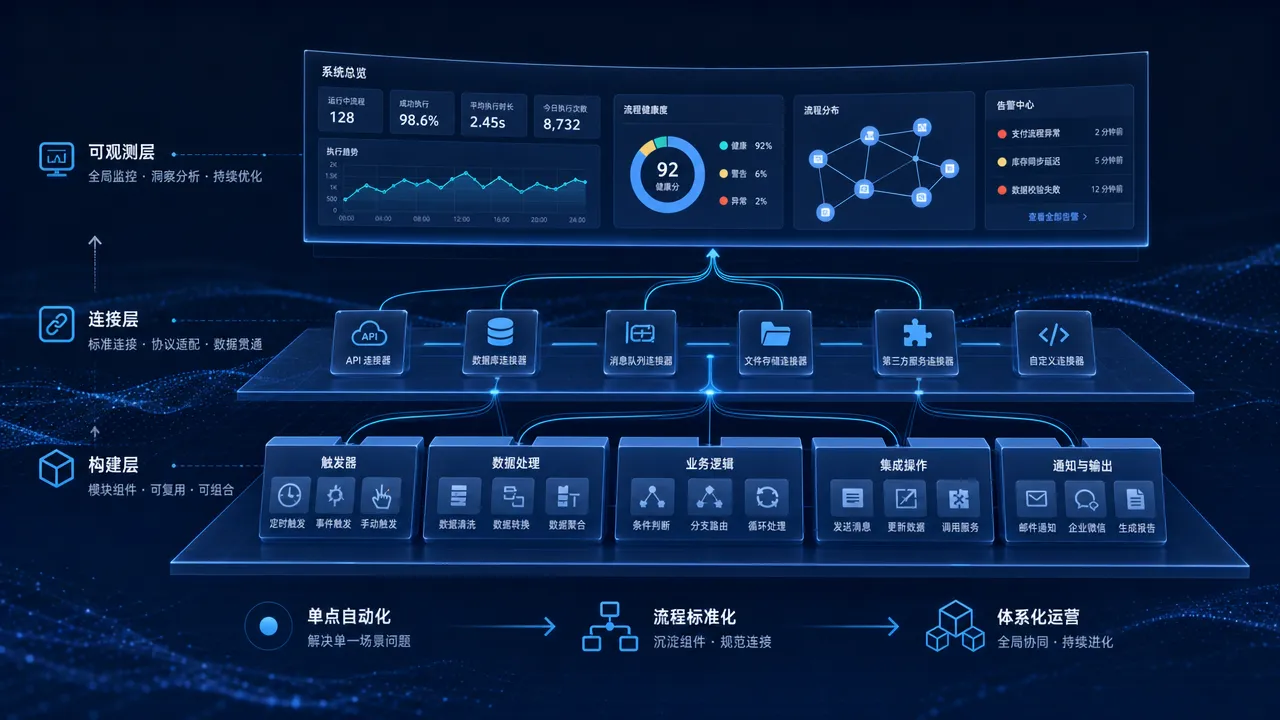
工作流扩展方法论 是这个系列的方法论篇,回答「怎么从一个场景扩展到几十个场景而不混乱」。核心原则是三个:模块化(每个场景只做一件事)、标准化(输入输出格式统一)、可观测(每个节点有日志和告警)。这三个原则是工作流从玩具到生产工具的分水岭。
RSS 自动化指南 是 RSS 采集场景的方法论补充——不只是教你搭一个 RSS 管线,而是讲 RSS 在自动化体系中的角色定位。RSS 是低成本、高可靠的信息输入层,几乎所有内容自动化体系的第一块拼图都应该是 RSS。
小红书批量内容创作 把单篇创作的经验扩展到批量——从选题矩阵设计、素材库搭建到批量生产管线的完整方法论。重点不在单篇质量(那是提示词的事),而在批量生产时怎么保持一致性和差异化的平衡。
⚠️ 常见踩坑:很多人搭工作流时追求「一步到位」——第一次就想搭完整体系。实际经验是反过来的:先跑通一个最小场景,验证可行后再逐步扩展。Make 的场景是可以随时修改的,不需要一次性设计完美。
内容生产和分发做好了,变现是下一步。SEO 优化和写作效率直接影响内容的商业价值。
搜索引擎的展示片段决定了点击率。SEO Meta Description 自动化 用 Make 批量生成和优化文章的 Meta Description——读取文章正文,提取核心要点,按 SEO 最佳实践生成 160 字符以内的描述文本。批量处理几十篇老文章的 Meta Description 优化,几分钟搞定。
DeepSeek 写作革命 探索了 DeepSeek 模型在中文写作场景的独特优势——成本极低、中文理解到位、输出风格稳定。教程里搭建了一个 DeepSeek 驱动的写作管线,从微信公众号到办公文档的日常写作全覆盖。关键发现是:中文写作场景,DeepSeek 的性价比远超 GPT-4。
SEO 文案提示词指南 虽然标题聚焦 ChatGPT,实际内容适用于所有大语言模型。这篇指南系统整理了 SEO 文案的提示词模板库——标题生成、Meta 优化、内容大纲、FAQ 生成、长尾关键词拓展。每个模板都经过实际排名验证,可以直接插入 Make 工作流中使用。

搭了 28 个场景后,我踩过的坑可以归纳成几类:
误区一:自动化 = 无人值守。 全自动不等于高质量。任何涉及对外发布的内容管线,都应该保留人工审核节点。Make 支持在管线中间插入暂停模块,等人工确认后再继续执行。
误区二:一个场景解决所有问题。 超过 30 个模块的场景几乎无法维护。按功能边界拆分成多个场景,通过 Webhook 串联,每个场景独立可调试。
误区三:忽略错误处理。 生产环境下 API 超时、格式异常、配额耗尽是常态。每个关键模块都应该配上错误处理路由——失败后是重试、跳过还是告警,需要预先设计。
误区四:不做数据备份。 Make 的数据存储不是数据库,不要把它当唯一数据源。关键数据同步到 Notion 或外部数据库,Make 只做管线中转。
误区五:忽视成本控制。 免费计划 1000 次操作看起来不少,但一个复杂场景跑一次可能消耗 20-50 次操作。上线前用 Run Once 模式估算操作量,避免月底配额用完。
⬜ 注册 Make.com 账号并完成新手引导
⬜ 搭建第一个 RSS 到 Notion 的采集管线
⬜ 接入至少一个 AI 模型(OpenAI / DeepSeek / Claude)
⬜ 完成一个内容生产场景的端到端测试
⬜ 设置定时调度,让场景自动运行
⬜ 为关键模块添加错误处理路由
⬜ 搭建第一个跨场景 Webhook 串联
⬜ 建立提示词库并纳入版本管理
⬜ 完成一个社交平台的内容分发自动化
⬜ 估算月度操作量并选择合适的付费计划
⬜ 为所有场景添加执行日志监控
⬜ 将采集、加工、分发三类场景串联成完整管线
Make 不是目的,效率才是。这 28 个场景不需要一次性全搭——挑一个离你日常最近的场景开始,跑通了再扩展。自动化的价值不在于炫技,在于把重复劳动的时间省下来,用在真正需要人判断的事情上。
工具会迭代,场景会变化,但「采集 → 加工 → 分发」的管线思维不会过时。把这个思维模型装进去,不管未来用 Make 还是别的工具,你都能快速搭出自己的自动化体系。
本指南涵盖的 28 个实战场景在 AI 编程实操课中都有对应的源码和详细讲解。课程按场景分模块,每个模块配完整的 Make 场景蓝图文件(JSON)和运行说明。


Claude Code MCP 工具新手教程:用简单直观的语言讲清核心概念、适用判断、上手步骤、常见问题和下一步学习路径。

OpenAI Codex 怎么接 MCP 服务器?一篇讲清 MCP 是什么、怎么装第一个、新手必装哪几个、配置字段详解、安全风险与避坑,新手按最小路径上手。

小红书、公众号、抖音、视频号、YouTube、X——6 个平台先做哪个?这个站先帮你选对平台,再给每个平台用 AI 做内容的打法。
每周精选 AI 编程与自动化实战内容,直达你的邮箱